轻松获取加密网页源码,教你抓取技巧!
优采云 发布时间: 2023-03-16 12:10在如今这个信息时代,网络安全问题变得越来越重要。许多网站的开发者们都会采用加密方式来保护网页源代码,以此来保证网站的安全性。但是,如果你需要获取这些加密的网页源码,该怎么办呢?本文将为大家详细介绍如何抓取加密的网页源码。
1.什么是加密的网页源码
在了解如何抓取加密的网页源码之前,我们先来了解一下什么是加密的网页源码。通常情况下,我们可以通过浏览器查看页面源代码来获取页面信息。但是,在某些情况下,开发者可能会对网页进行加密处理,以保证页面信息不被泄露。这时候,我们就需要使用一些特殊的工具和技术来获取被加密的网页源码。
2.使用浏览器开发工具获取未加密的网页源码
如果你想获取未经过加密处理的网页源码,那么使用浏览器开发工具就是一个非常好的选择。现代浏览器都内置了一些非常强大的开发工具,可以帮助我们查看和编辑页面元素、样式和脚本等信息。下面是获取未加密的网页源码的步骤:
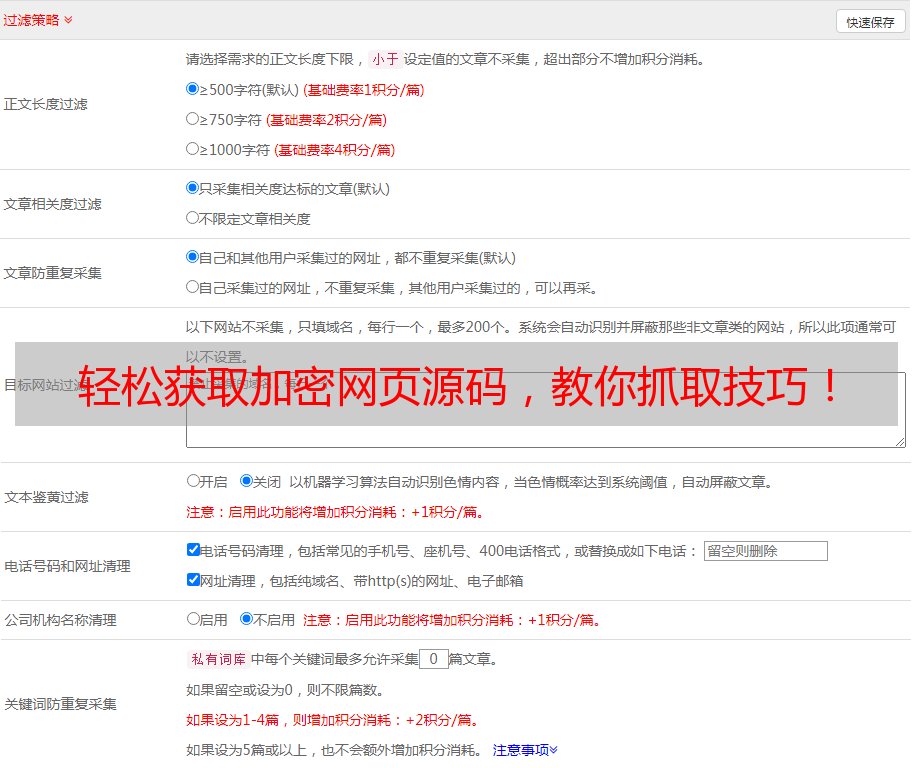
(1)打开需要查看源代码的页面,并在浏览器中按下F12键或者右键选择“检查”选项。
(2)在开发工具中找到“Elements”选项卡,并在其中定位需要查看源代码的元素。
(3)右键点击该元素,并选择“Edit as HTML”选项即可修改并保存该元素对应的HTML代码。
3.使用网络爬虫技术获取加密的网页源码
如果你需要获取已经经过加密处理的网页源码,那么使用网络爬虫技术就是一个比较好的选择。网络爬虫是一种自动化程序,可以模拟人类用户访问网络并收集相关数据。下面是使用网络爬虫技术获取加密网页源码的步骤:
(1)确定目标URL和所需参数,并构建请求头。
python
import requests
url ='https://www.example.com'
headers ={
'User-Agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
params ={
'param1':'value1',
'param2':'value2'
}
response = requests.get(url, headers=headers, params=params)
(2)解析响应内容,并提取所需信息。
python
import re
from bs4 import BeautifulSoup
html_text = response.text
soup = BeautifulSoup(html_text,'html.parser')
encrypted_content = soup.find('div',{'class':'encrypted-content'}).text
decrypted_content = decrypt(encrypted_content)
4.使用插件或软件获取被动态加载和渲染的网页源码
有些时候,开发者会采用一些特殊技术来动态加载和渲染页面内容,从而使得传统方法无法直接获取到完整的网页源代码。这时候,我们可以考虑使用一些插件或软件来帮助我们完成任务。
5.通过服务器端渲染技术获取动态生成和渲染的网页源码
如果以上方法都无法满足你的需求,那么服务器端渲染技术就是最后一个选择了。服务器端渲染指的是在服务器端生成HTML代码并将其发送给客户端浏览器进行显示。相比于客户端渲染方式,服务器端渲染具有更高效、更稳定、更安全等优点。
至此,我们已经详细介绍了如何抓取加密的网页源码。无论你需要从哪种类型的页面中提取信息,在掌握了上述技术之后都能够轻松实现目标。希望本文对您有所帮助!

