爬虫采集百度排名的10个实用技巧详解
优采云 发布时间: 2023-03-16 08:13在当今信息化时代,企业的网络推广已经成为了必不可少的一部分。而搜索引擎优化(SEO)则是网络推广的重要手段之一,其中百度排名则被视为一个企业网站是否能够得到更多曝光的重要指标。因此,如何利用爬虫采集百度排名成为了企业SEO优化中的重要一环。本文将从以下10个方面对如何利用爬虫采集百度排名进行详细讨论。
一、什么是爬虫
二、爬虫原理及分类
三、爬虫的使用场景
四、爬虫采集百度排名的意义
五、百度排名的计算方法
六、如何利用Python编写爬虫程序
七、如何抓取百度搜索结果页面信息
八、如何解析HTML文档
九、如何将数据存储到数据库中
十、注意事项及风险提示
一、什么是爬虫
爬虫是指模拟浏览器行为,按照一定规则自动抓取互联网上的信息。在互联网上,我们常常需要获取某些特定的信息,比如抓取某个网站上的文章内容或者抓取搜索引擎上某个关键词的相关信息等,这时候就可以使用爬虫来实现。
二、爬虫原理及分类
爬虫原理主要包括请求发送和响应接收两个步骤。其中请求发送是指向目标站点发送HTTP请求,响应接收则是指获取目标站点返回的HTML文档,并对其进行解析和处理。
根据不同需求和功能,爬虫可以分为通用型爬虫和聚焦型爬虫两类。通用型爬虫是指能够自动遍历整个互联网并抓取所有遇到的页面信息,而聚焦型爬虫则是针对特定领域或者特定网站进行信息抓取。
三、爬虫的使用场景
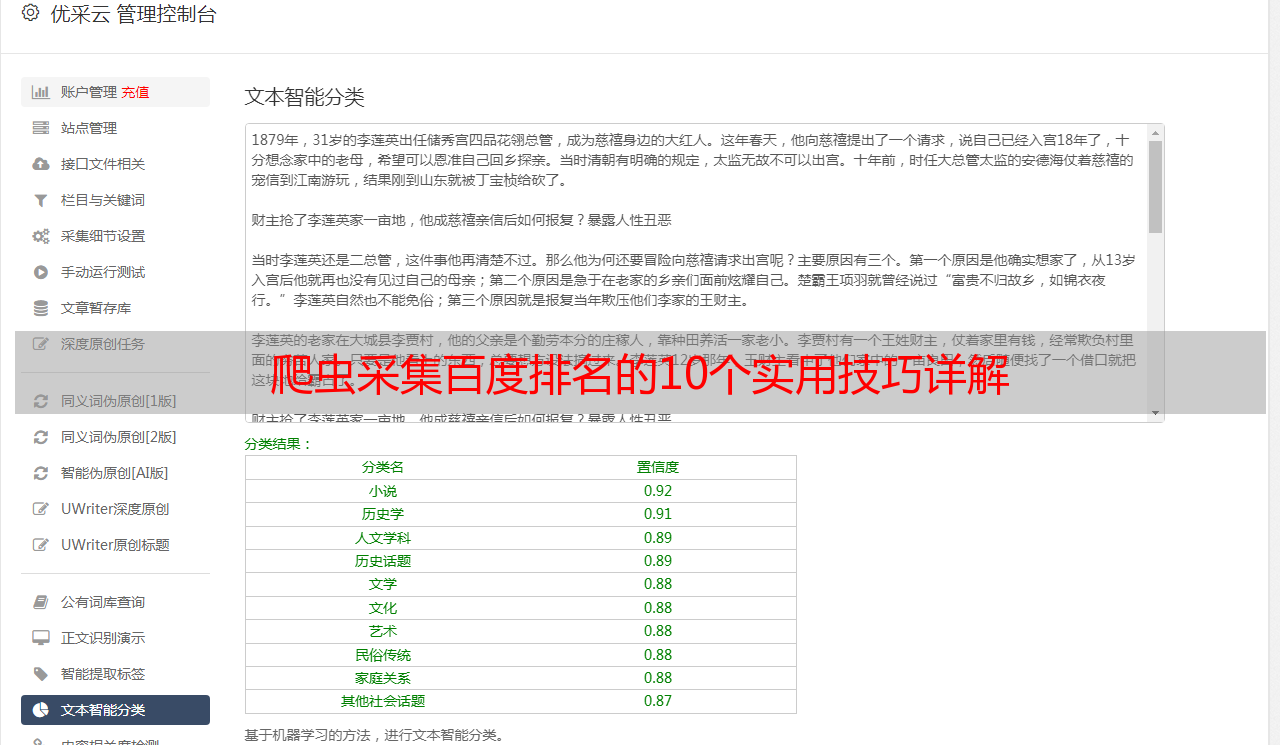
除了SEO优化中采集百度排名外,还有很多其他场景可以使用到爬虫技术。比如:
1.网络舆情监测:通过抓取各大社交媒体平台上用户发布的内容,识别出热点话题并进行分析;
2.数据挖掘:通过抓取各类数据源中的数据,并对其进行处理和分析,发现其中蕴含的规律;
3.电商价格监测:通过对竞争对手价格进行实时监测来调整自己产品价格;
4.金融市场分析:通过抓取新闻资讯和市场数据来预测股票走势等。
四、爬虫采集百度排名的意义
百度搜索引擎是中国最大的搜索引擎之一,在企业网络推广过程中占有非常重要地位。而百度排名则是衡量一个企业SEO优化效果是否良好的重要指标之一。因此,通过利用爬虫技术采集百度排名数据可以帮助企业了解自己在搜索引擎中所处位置,并作出相应调整以提高曝光率和流量。
五、百度排名计算方法
百度搜索结果页面通常会展示10条左右的搜索结果,并且会显示每个结果所处位置(即排名)。而百度排名则是根据一个网页在某个关键词下所处位置计算得出的。
具体计算方法包括以下几个方面:
1.百度算法:百度算法将关键词与网页内容相关性作为评判标准之一;
2.网页质量:包括网页内容质量、页面结构布局等方面;
3.外链数量:被其他网站链接到该网页数量越多,则其权重也会越高;
4.内部链接:内部链接也会影响该页面权重;
5.用户行为:用户点击该页面或停留时间长短等行为也会影响该页面权重。
六、如何利用Python编写爬虫程序
Python语言具有易学易用等特点,在网络数据采集领域也得到了广泛应用。下面我们以Python语言为例介绍如何编写简单易用且高效稳定的网络数据采集程序。
1.安装Python环境:下载安装Python环境(建议使用3.x版本);
2.安装必要库文件:安装requests库和BeautifulSoup库;
3.编写代码:编写代码实现请求发送和响应接收功能;
4.运行程序:运行程序并查看结果。
七、如何抓取百度搜索结果页面信息
在编写采集程序之前需要先了解目标数据存储方式及其结构,然后根据结构设计相应代码实现数据采集功能。在本例中,我们需要抓取每一页搜索结果列表中每条搜索结果标题及URL地址信息。
1.分析目标页面结构:打开Chrome开发者工具查看HTML结构;
2.发送HTTP请求获取HTML文档:使用requests库发送HTTP GET请求获取HTML文档;
3.解析HTML文档:使用BeautifulSoup库解析HTML文档并获取所需信息;
4.数据处理与存储:将所需数据保存至文件或数据库中。
八、如何解析HTML文档
在实际开发过程中,我们需要从HTML文档中提取出所需数据。而BeautifulSoup库则提供了丰富强大的API函数来帮助我们完成这项任务。
1.根据标签名称查找元素节点对象: soup.find_all('tagname')或soup.select('tagname');
2.根据元素属性查找元素节点对象: soup.find_all(attrs={'attrname':'attrvalue'})或soup.select('[attrname="attrvalue"]');
3.根据CSS选择器查找元素节点对象: soup.select('cssselector')。
九、如何将数据存储到数据库中
在本例中我们需要将每条搜索结果标题及URL地址信息保存至MySQL数据库中。具体操作步骤如下:
1.安装MySQL数据库;
2.安装PyMySQL库;
3.创建数据库及表格;
4.编写代码连接数据库并插入数据;
5.运行程序并查看结果;
十、注意事项及风险提示
在进行网络数据采集时需要注意以下几点:
1.遵守相关法律法规;
2.尊重网站版权;
3.不过度频繁访问一个站点;
4.不泄露隐私信息.
同时,在进行网络数据采集过程中还存在以下风险:
1. IP被封禁;
2.网络防火墙屏蔽;
3.网站反扒机制限制.
总之,在进行网络数据采集时需要谨慎操作,并遵守相关规定和法律法规。
本文介绍了如何利用Python编写简单易用且高效稳定的网络数据采集程序,并以SEO优化领域里面最基础也最核心——如何利用爬虫技术采集百度排名为例详细介绍了实现步骤及注意事项以及风险提示等相关内容。

