利用C#技巧快速采集网页,注意事项不容错过!
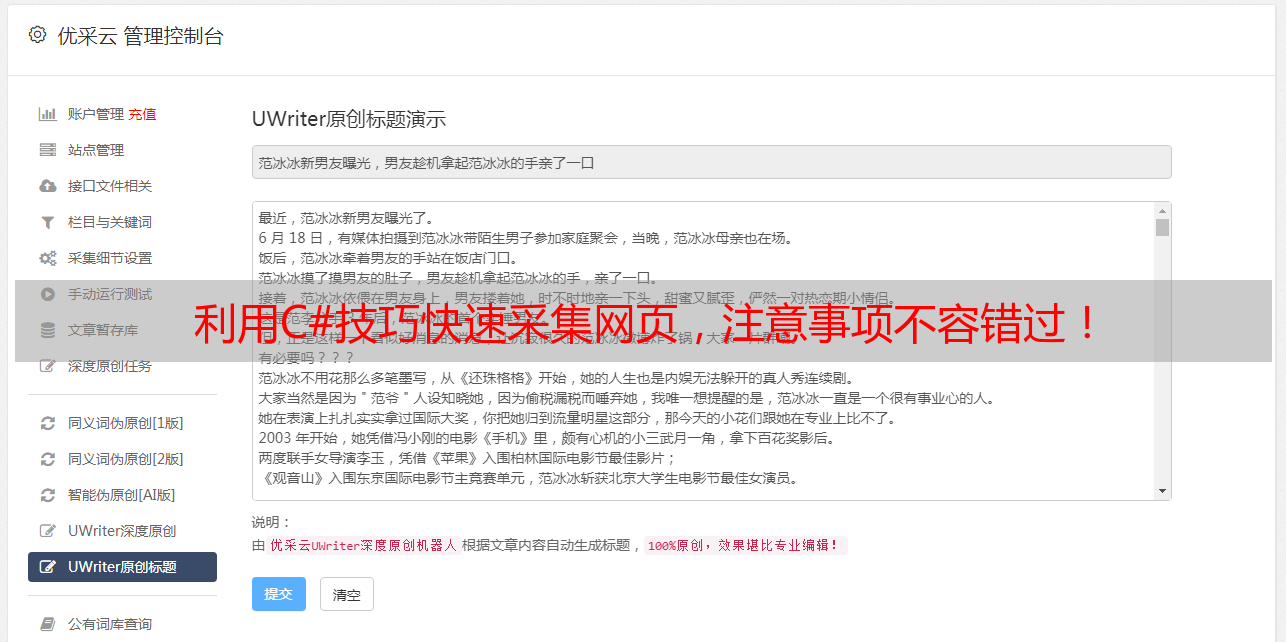
优采云 发布时间: 2023-03-14 19:12在当今数字化时代,数据是企业发展的重要驱动力。然而,如何高效地采集网络上的数据成为了一个现实难题。作为一种高效的编程语言,C#提供了许多优秀的解决方案来帮助我们更快速地采集网页数据。本文将从以下八个方面详细介绍C#采集网页的技巧和注意事项。
一、使用 HttpWebRequest 类发送 HTTP 请求
二、使用 WebClient 类下载网页资源
三、使用 HtmlAgilityPack 解析 HTML 文档
四、使用正则表达式提取目标数据
五、使用 Selenium WebDriver 模拟浏览器行为
六、使用代理 IP 避免被封禁
七、处理验证码识别问题
八、注意反爬虫策略
一、使用 HttpWebRequest 类发送 HTTP 请求
HTTP 请求是我们获取网页数据的第一步。HttpWebRequest 是.NET Framework 中专门用于发送 HTTP 请求的类,它提供了非常丰富的参数设置,可以满足我们各种请求方式(GET/POST/PUT/DELETE)和参数(Header/Cookie)的需求。以下是一个简单的示例:
HttpWebRequest request =(HttpWebRequest)WebRequest.Create("https://www.baidu.com");
request.Method ="GET";
request.UserAgent ="Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
request.ContentType ="application/x-www-form-urlencoded;charset=utf-8";
HttpWebResponse response =(HttpWebResponse)request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream());
string html = reader.ReadToEnd();
以上代码通过 HttpWebRequest 发送了一个 GET 请求,并获取了百度首页的 HTML 内容。需要注意的是,我们在请求头中设置了 UserAgent 和 ContentType,这可以帮助我们更好地模拟浏览器行为,避免被网站屏蔽。
二、使用 WebClient 类下载网页资源
WebClient 是另一个常用于下载网络资源的.NET Framework 类,它可以帮助我们更方便地下载图片、音频等文件。以下是一个简单示例:
WebClient client = new WebClient();
client.Headers.Add("User-Agent","Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
client.DownloadFile("http://www.ucaiyun.com/logo.png",@"D:\logo.png");
以上代码中,我们通过 WebClient 下载了优采云官网上的 Logo 图片,并保存到本地磁盘。
三、使用 HtmlAgilityPack 解析 HTML 文档
HtmlAgilityPack 是.NET Framework 中一个非常强大的 HTML 解析库,它可以帮助我们快速解析 HTML 文档,并提取其中的目标数据。以下是一个简单示例:
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://www.baidu.com");
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.Attributes["href"].Value);
}
以上代码中,我们使用 HtmlAgilityPack 加载了百度首页,并提取了其中所有链接地址。
四、使用正则表达式提取目标数据
正则表达式是一种通用的字符串匹配工具,在C#中也得到了广泛应用。当我们需要从 HTML 文档中提取特定信息时,可以使用正则表达式来实现。以下是一个简单示例:
string html ="<div><p>hello world</p></div>";
Match match = Regex.Match(html,"<p>(.*?)</p>");
if (match.Success)
{
Console.WriteLine(match.Groups[1].Value);
}
以上代码中,我们通过正则表达式从一个包含“hello world”文本内容的 div 元素中提取出 p 元素内部文本。
五、使用 Selenium WebDriver 模拟浏览器行为
有些网站可能会通过 JavaScript 实现异步加载或动态渲染页面内容,此时直接发送 HTTP 请求可能无法获取到目标数据。这时候可以考虑使用 Selenium WebDriver 来模拟浏览器行为。以下是一个简单示例:
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.baidu.com/");f1c7f2bc314a2d867297d4007e9beca4= driver.FindElement(By.Id("kw"));
element.SendKeys("Selenium");
element.Submit();
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(10));
wait.Until(ExpectedConditions.TitleContains("Selenium"));66127b562be3aaf552f42c50a407f0a8.WriteLine(driver.Title);
driver.Quit();
以上代码中,我们启动了 Chrome 浏览器,并打开百度首页;然后在搜索框中输入“Selenium”关键词,并提交搜索请求;最后等待页面标题包含“Selenium”关键词,并输出页面标题。
六、使用代理 IP 避免被封禁
有些网站会限制同一 IP 地址在短时间内发送过多请求或频繁访问相同2e9b5865537db47267991419e97f0ae9地址等情况。此时为避免被封禁或限制访问次数,可以考虑使用代理 IP 来发送请求。以下是一个简单示例:
WebProxy proxy = new WebProxy("http://127.0.0.1:8888");
HttpWebRequest request =(HttpWebRequest)WebRequest.Create("https://www.baidu.com/");
request.Proxy = proxy;
request.Method ="GET";
request.Timeout = 5000;
HttpWebResponse response =(HttpWebResponse)request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.UTF8);
string html = reader.ReadToEnd();
以上代码中,我们设置了代理 IP 地址为“http://127.0.0.1:8888”,并将其应用于 HttpWebRequest 对象中发送请求。
七、处理验证码识别问题
有些网站会通过验证码来防止机器人爬虫程序访问或提交数据。此时需要先识别验证码才能继续进行操作。针对不同类型验证码,可采用不同的识别方法和工具。例如:
-数字字母组合验证码:可通过 OCR 技术进行识别;
-滑块验证码:可通过模拟鼠标移动轨迹来绕过验证;
-声音验证码:可通过语音识别技术进行识别。
八、注意反爬虫策略
随着互联网技术和信息安全意识不断提高,越来越多网站开始采取反爬虫措施来保护自身利益和用户隐私。因此,在进行网络爬虫开发时必须要注意相关反爬虫策略和规范,并严格遵守相关法律法规和道德准则。
总结
C#是一种功能强大的编程语言,在网络爬虫开发中也有着广泛应用场景。本文从 HttpWebRequest、WebClient、HtmlAgilityPack、正则表达式等多个方面详细介绍了C#采集网页数据的技巧和注意事项,并给出了相应示例代码。同时还介绍了如何处理验证码识别问题以及如何遵守反爬虫策略等相关内容。希望本文能对读者在C#网络爬虫开发方面有所帮助。
优采云(www.ucaiyun.com)致力于为企业提供全方位 SEO 优化服务和解决方案,在搜索引擎排名和品牌曝光方*敏*感*词*备丰富经验和成功案例。如需更多 SEO 相关咨询,请联系优采云客服人员(400-800-8888)。

