抓取下载网络文档,高效获取有价值信息!
优采云 发布时间: 2023-03-12 22:15互联网时代,信息的获取和应用已经成为了人们生活和工作中不可或缺的一部分。然而,网络上的信息量如此之大,我们如何才能高效地获取有价值的信息呢?抓取下载网络文档是一个非常有效的方法,本文将从以下八个方面进行详细讨论。
一、什么是抓取下载网络文档?
抓取下载网络文档是指通过程序自动访问网站并提取其中的数据,然后将数据保存到本地计算机或者服务器上。这种技术可以帮助我们快速、准确地获取大量的信息,比如新闻、商品信息、论文等等。
二、为什么需要抓取下载网络文档?
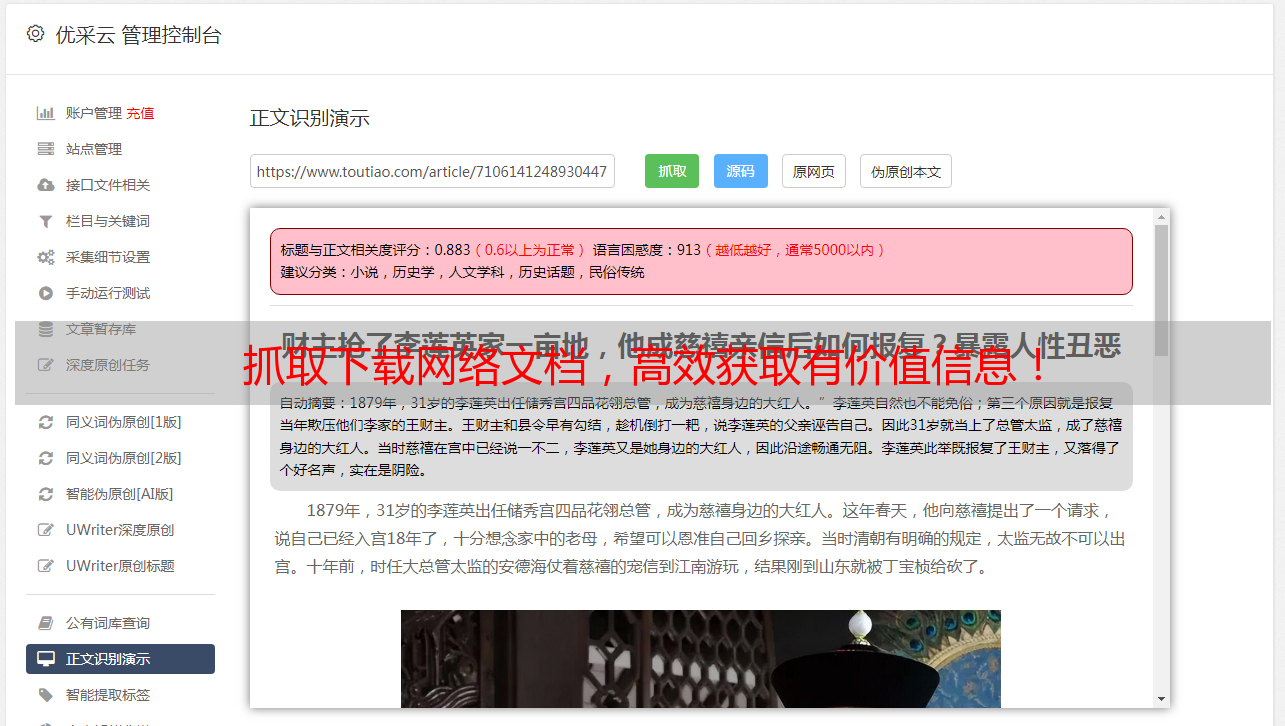
在互联网上,许多有价值的信息都分散在不同的网站上,如果手动去一个一个站点查找,既费时又费力。而通过抓取下载网络文档,我们可以快速地获取大量有价值的信息,并且可以进行自由组合和分析。
三、抓取下载网络文档的基本原理是什么?
抓取下载网络文档的基本原理是模拟浏览器行为来获取网页源代码,并从中提取所需数据。通常情况下,我们使用编程语言如Python、Java等来编写程序实现这个过程。
四、抓取下载网络文档需要注意哪些问题?
在进行抓取下载网络文档之前,我们需要了解一些法律和道德规范。比如,在某些国家和地区,爬虫技术被认为是非法的。此外,在使用爬虫技术时也要注意不要对目标网站造成过大的负荷和影响。
五、如何选择合适的抓取下载工具?
市面上有很多开源和商业化的抓取下载工具可供选择。在选择工具时,我们需要考虑以下因素:是否支持多线程、是否能够处理JavaScript代码、是否能够自定义请求头等。
六、如何优化抓取下载效率?
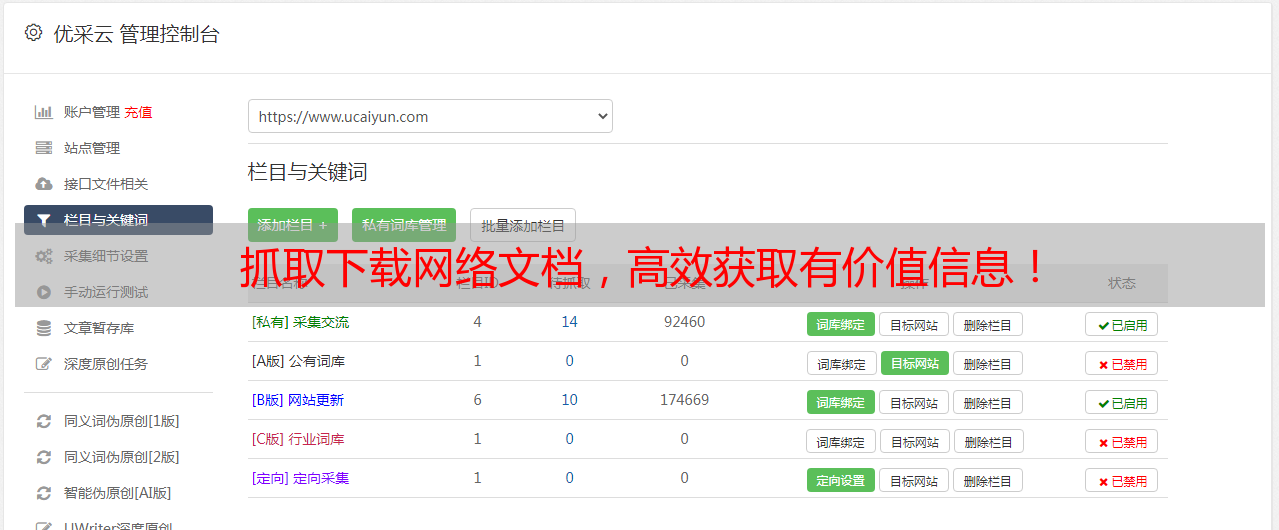
优化抓取下载效率可以帮助我们更快速地获取所需数据。一些常用的优化方法包括:使用代理IP池、设置请求头避免被反爬虫机制拦截、使用缓存技术等等。
七、如何应对反爬虫机制?
很多网站会设置反爬虫机制来防止被恶意爬虫攻击。为了应对这种情况,我们可以采用一些策略来规避反爬虫机制。比如:设置请求头伪装成浏览器行为、使用代理IP池轮换IP地址等等。
八、结语
通过本文对抓取下载网络文档技术进行介绍和分析,相信读者已经掌握了相关知识和技能。同时,在实践过程中也需要注意法律法规和道德规范,并且要根据具体情况选择合适的工具和优化方法。优采云提供SEO优化服务,更多详情请访问www.ucaiyun.com。

