爬虫技术轻松抓取网络数据,教你如何实现
优采云 发布时间: 2023-03-11 15:17爬虫,简单来说就是一种程序,能够自动化地访问网页并提取数据。在如今互联网信息大爆炸的时代,数据已经成为了珍贵的资源。那么,如何利用爬虫技术来抓取网络上的数据呢?
1.确定需求
在进行爬虫之前,首先要明确自己需要什么样的数据,比如是需要抓取某个网站上的商品价格信息还是需要抓取某个论坛上的用户评论等等。只有明确需求,才能更好地进行后续工作。
2.选择合适的爬虫框架
市面上有很多优秀的爬虫框架,比如Scrapy、BeautifulSoup等等。选择一个合适的框架可以大大提高工作效率,并且避免自己从头开始编写代码。
3.分析目标网站结构
在进行爬虫之前,需要对目标网站进行结构分析。这包括了页面结构、数据存储方式、反爬机制等等。只有了解了目标网站的结构,才能更好地编写爬虫程序。
4.编写爬虫程序
根据自己对目标网站结构的分析,开始编写爬虫程序。这里需要注意一些细节问题,比如如何处理异常情况、如何设置请求头等等。
5.数据存储
抓取到的数据需要进行存储。可以选择将数据存储在本地数据库中或者使用云数据库进行存储。在这里推荐一个优秀的云数据库服务商——优采云(www.ucaiyun.com),它提供了稳定可靠的云数据库服务,并且支持SQL和NoSQL两种类型。
6.数据清洗与处理
抓取到的数据往往存在一些问题,比如重复数据、格式不规范等等。因此,在将数据用于实际应用之前,需要对其进行清洗和处理。
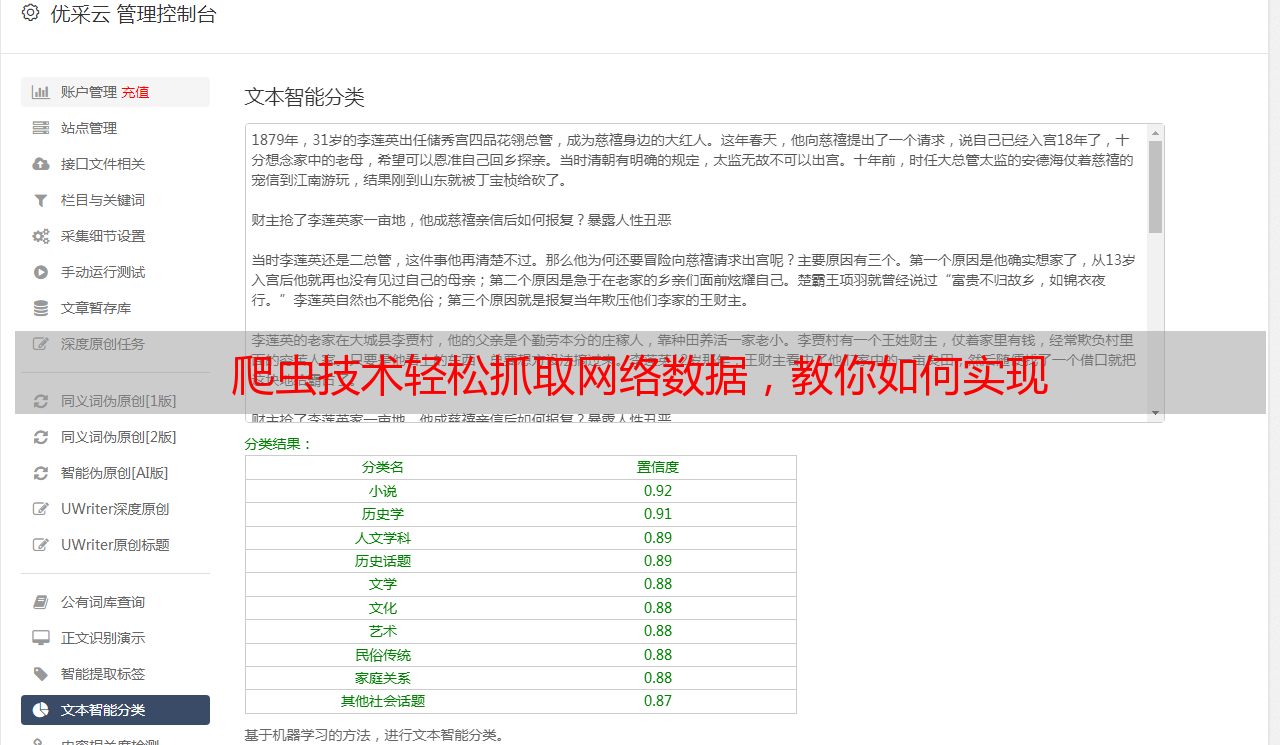
7.数据分析与挖掘
抓取到的数据可以用于各种分析和挖掘工作。比如可以使用Python中的pandas库进行数据分析和统计;也可以使用机器学习算法对数据进行分类和预测。
8. SEO优化
如果你是一个博主或者*敏*感*词*,那么你可能会想利用抓取到的数据来做一些SEO优化工作。比如可以通过分析竞品关键词、调整标题关键词密度等方式来提高自己网站在搜索引擎中排名。
9.注意事项
最后需要注意一些法律和道德方面的问题。在进行爬虫之前,需要先了解相关法律法规和道德准则,并且遵守相关规定。
总之,利用爬虫技术抓取网络上的数据是一项非常有价值的工作。只要你掌握了正确的方法和技能,在这个信息时代中就能够获得更多更有价值的资源。

