抓取文章数据软件:操作简易,优劣分析一网打尽
优采云 发布时间: 2023-03-11 03:10随着互联网时代的到来,数据已经成为了一种重要资源。但是,如何获取这些数据却成为了许多人头疼的问题。为此,现在有一些从文章中抓取数据的软件可以帮助我们快速地获取所需数据。下面就让我们一起来看看这些软件的具体使用方法及其优缺点吧。
1.什么是从文章中抓取数据的软件?
从文章中抓取数据的软件是一种可以自动化地从网络上的文章中提取出所需信息并进行处理的工具。它们通常可以识别出文章中的关键词、标题、正文、图片等内容,并将其转化为结构化的数据格式,以便于后续分析和利用。
2.从文章中抓取数据的软件有哪些?
目前市面上比较流行的从文章中抓取数据的软件包括但不限于以下几种:
(1) BeautifulSoup:是一个Python库,可以用来解析HTML和XML文档,并提供了许多方便的方法进行信息提取。
(2) Scrapy:也是一个Python库,主要用来爬取网站并提取出其中的信息。它支持异步IO和分布式爬虫,并且拥有良好的扩展性。
(3) Selenium:是一个自动化测试工具,主要用来模拟用户在浏览器上的操作。通过Selenium可以实现对JavaScript生成内容的爬取。
(4) PyQuery:也是一个Python库,它类似于jQuery,可以方便地对HTML/XML文档进行解析和处理。
3.如何使用从文章中抓取数据的软件?
使用从文章中抓取数据的软件通常需要以下几个步骤:
(1)首先需要确定所需信息在哪些网站或页面上,并找到相应的URL地址。
(2)接着需要将URL地址传入到相应的爬虫程序中,并设置好爬虫规则。例如,在Scrapy中可以通过编写Spider类来定义爬虫规则。
(3)爬虫程序运行之后会自动地向目标网站发送请求,并获取到网页源代码。接下来就可以利用相应库提供的方法进行信息提取了。
4.从文章中抓取数据的软件有哪些优缺点?
使用从文章中抓取数据的软件有以下几个优点:
(1)可以快速地获取大量信息,避免了手工复制粘贴等繁琐操作。
(2)可以自动化地处理数据,并将其转化为结构化格式,方便后续分析和利用。
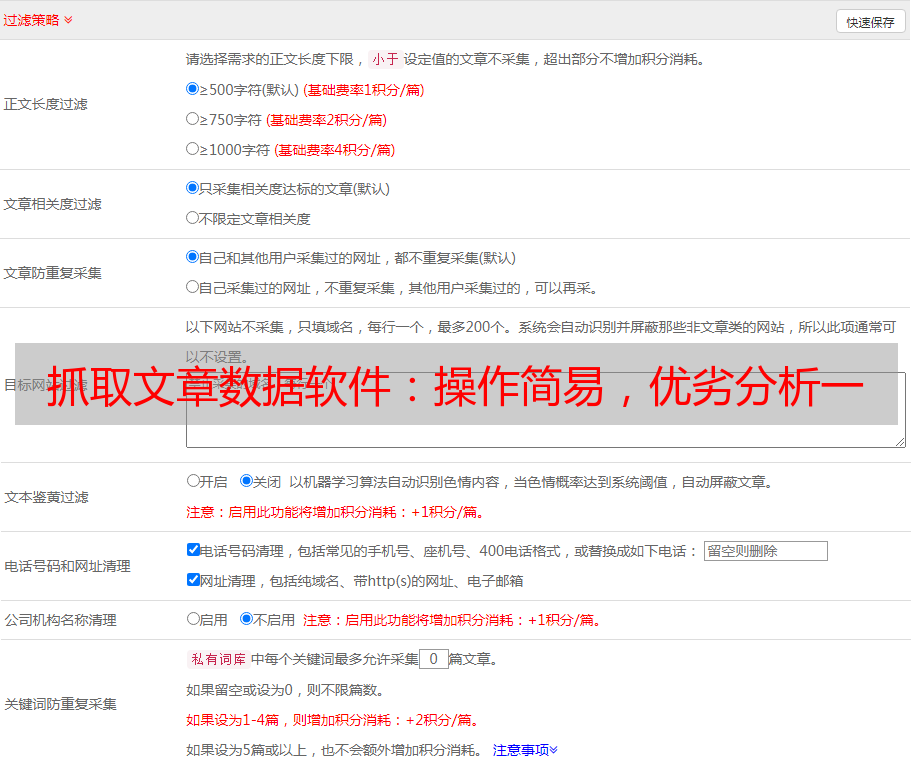
(3)可以针对不同类型、不同格式的文档进行处理,并且扩展性较好。
然而,也存在以下几个缺点:
(1)爬虫程序可能会被目标网站屏蔽或封禁,导致无法正常运行。
(2)爬虫程序可能会产生大量请求并占用目标网站资源,导致目标网站负载过高。
(3)爬虫程序可能会因为页面结构变化等原因而失效,需要不断更新维护。
5.如何避免被封禁?
为避免被封禁或屏蔽,我们建议采用以下几个方法:
(1)控制请求频率:合理控制请求频率可以降低被封禁或屏蔽的概率。例如,在Scrapy中可以通过设置DOWNLOAD_DELAY参数来控制请求间隔时间。
(2)使用代理IP:使用代理IP可以有效地隐藏真实IP地址,并且避免被目标网站屏蔽或封禁。例如,在Scrapy中可以通过设置DOWNLOADER_MIDDLEWARES参数来添加代理IP池。
(3)随机UA:随机User-Agent可以有效地模拟浏览器行为,并且避免被目标网站识别出爬虫程序。例如,在Scrapy中可以通过设置RANDOM_UA_TYPE参数来随机UA字符串。
6.什么情况下不适合使用从文章中抓取数据的软件?
虽然使用从文章中抓取数据的软件能够快速地获取大量信息,但并不适用于所有情况。以下几种情况不适合使用该方法:
(1)目标网站反爬虫技术较强:如果目标网站采用了较强的反爬虫技术,则很难通过简单地修改请求头等方式绕过其检测。
(2)数据量较小或需求定制化:如果所需获取的信息量较小或者需要定制化处理,则使用手工方式复制粘贴可能更加方便快捷。
7.优采云如何帮助我们进行SEO优化?
优采云是一款专业的SEO优化工具,它能够帮助我们进行关键词排名监测、竞争对手分析、关键词挖掘等功能。通过优采云,我们可以更加精准地了解用户搜索意图和竞争对手情况,并且针对性地进行SEO优化策略制定。如果您想要进一步了解优采云,请访问www.ucaiyun.com获取更多信息。
8.总结
总之,在当前大数据时代下,利用各种工具快速获取关键信息已经成为必备技能之一。使用从文章中抓取数据的软件能够帮助我们快速地获取所需信息,并将其转化为结构化格式以便后续分析和利用。当然,在使用该方法时也需要注意遵循相关法律法规和道德规范,并且注意防范风险和保护隐私安全。

