深入解析go采集器,揭秘九大细节!|实用干货
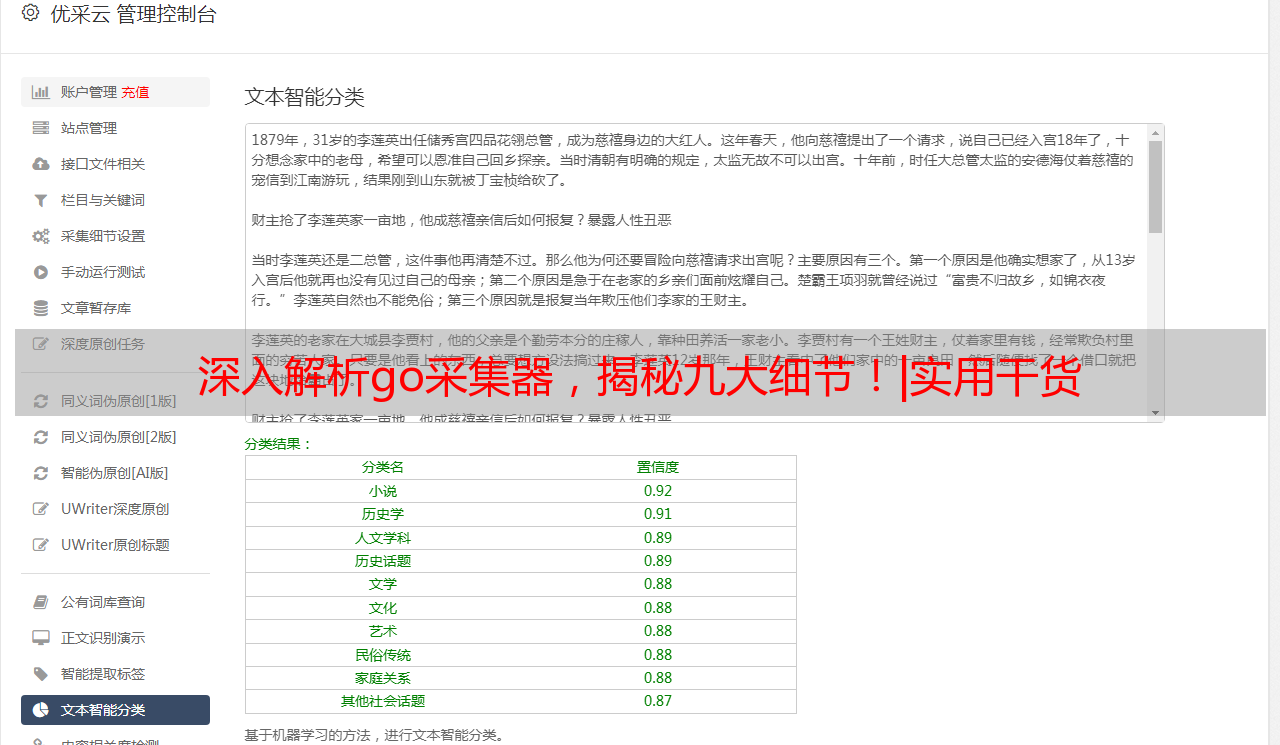
优采云 发布时间: 2023-03-10 23:10随着互联网的发展,数据已经成为了企业决策和业务发展的重要支撑。而数据采集是获取这些数据的基础,因此,如何高效地采集数据成为了企业面临的一个重要问题。在这个背景下,go采集器应运而生。本文将从以下九个方面对go采集器进行逐步分析讨论。
一、go采集器概述
go采集器是一款轻量级的开源网络爬虫框架,它基于Go语言开发,在速度、并发性能和资源占用等方面都有着很大优势。同时,go采集器还提供了一系列丰富的功能模块和插件,可以满足各种不同的爬取需求。
二、go采集器特点
相比于其他网络爬虫框架,go采集器具有以下特点:
1.高效稳定:基于Go语言开发,拥有非常高效的并发能力和占用少量资源的特点;
2.易用性好:提供了非常简单易用的API接口,无需深入学习复杂的爬虫技术;
3.功能丰富:提供了诸如代理池、限速、去重等多种功能模块和插件;
4.可扩展性强:支持自定义中间件、过滤规则等功能;
5.支持多种数据存储方式:支持MySQL、MongoDB等多种数据库存储方式。
三、go采集器应用场景
由于go采集器具有高效稳定、易用性好、功能丰富等特点,因此在各个领域都有广泛的应用,包括但不限于以下几个方面:
1.电商领域:通过爬取竞品价格、销量等信息来做出决策;
2.金融领域:通过爬取股票行情、财经新闻等信息来做出投资决策;
3.教育领域:通过爬取知识图谱、教材资源等信息来为学生提供更好的学习体验。
四、go采集器使用方法
使用go采集器进行数据爬取非常简单。首先需要安装go语言环境,然后在终端输入以下命令即可:
$ go get -u github.com/PuerkitoBio/goquery
安装完成后,在代码中引入相关包并编写相应代码即可实现数据爬取。
五、go采集器实战案例
以抓取豆瓣电影Top250为例。首先需要分析目标网站结构,并确定需要抓取哪些信息。然后,在代码中调用相关API接口即可实现数据爬取。
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"strings"
)
func main(){
url :="https://movie.douban.com/top250"
doc, err := goquery.NewDocument(url)
if err != nil {
panic(err)
}
doc.Find(".item").Each(func(i int, s *goquery.Selection){
title :=s.Find(".title").Eq(0).Text()
rating := strings.TrimSpace(s.Find(".rating_num").Eq(0).Text())
fmt.Printf("No.%d:%s, rating:%s\n",i+1, title, rating)
})
}
六、go采集器与SEO优化
对于企业而言,在进行SEO优化时需要收集大量关键词及其排名情况等信息。而这些信息又必须通过网络爬虫来获取。由于go采集器具有高效稳定、易用性好等特点,因此可以很好地满足这类需求。
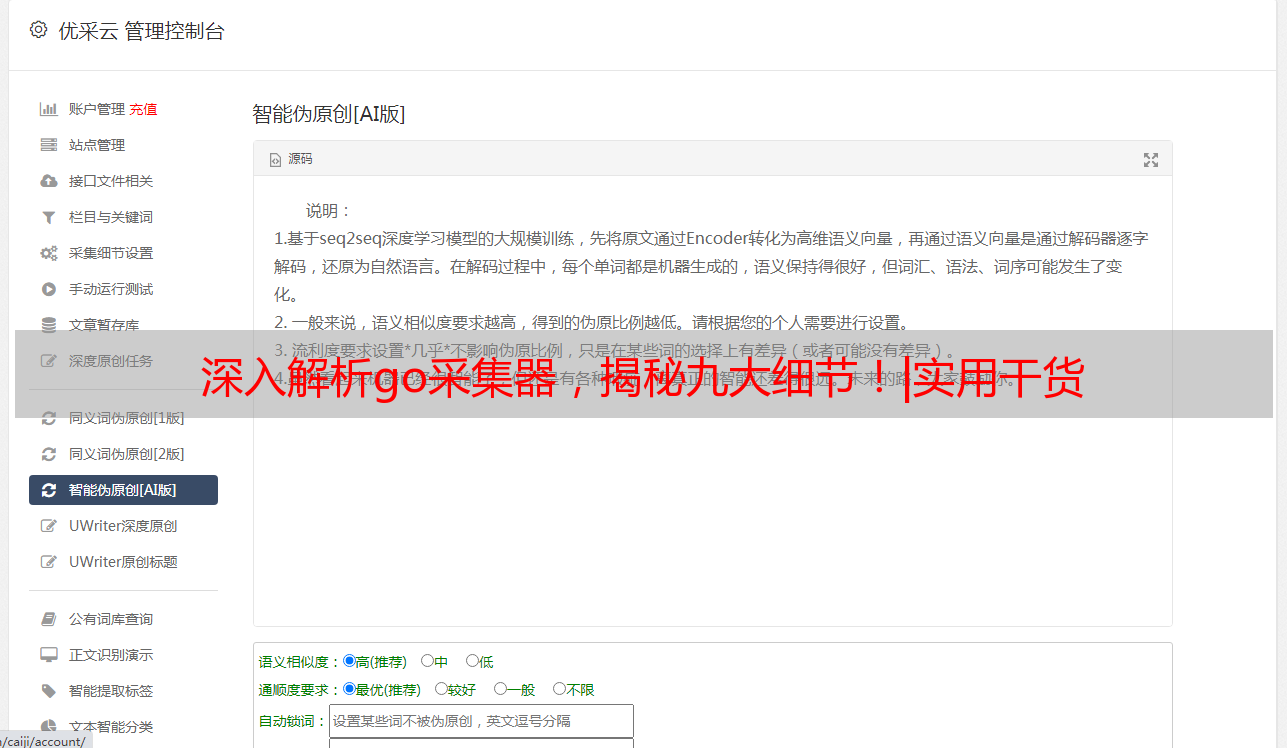
七、优采云与go采集器结合使用
优采云是一款专门针对SEO优化而设计的云平台产品。与go采集器结合使用可以更加高效地完成SEO优化任务。例如,在优采云上可以设置定时任务来定期执行关键词排名监控操作,并将监控结果自动发送至指定邮箱。
八、如何提高数据爬取效率
在进行*敏*感*词*数据爬取时,如何提高效率成为了一个重要问题。以下是几点提高效率的建议:
1.使用代理IP:避免被目标网站封禁IP地址;
2.使用缓存机制:避免重复请求已经获取过的页面;
3.多线程并发请求:利用Go语言强大的并发能力进行请求。
九、总结
本文对于网络爬虫框架中的一款轻量级开源网络爬虫框架——go采集器进行了详细介绍,并从多个方面对其进行了分析讨论。作为一款易用性好且功能丰富的网络爬虫框架,它已经被广泛应用于各个领域,并且在未来也将会有更加广泛的应用前景。

