轻松抓取动态网页数据,每一页都不漏!
优采云 发布时间: 2023-03-10 22:11随着互联网的不断发展,我们现在可以获得更多的信息。但是,许多有用的信息都包含在动态网页中,这对于爬虫来说是一个巨大的挑战。因此,本文将介绍如何抓取动态网页的每一页数据。
1.确定目标网站和数据结构
首先,我们需要确定要抓取的目标网站,并了解其页面结构和数据格式。这是非常重要的,因为不同的网站可能具有不同的页面结构和数据格式。
2.分析页面请求
一旦我们了解了目标网站的页面结构和数据格式,我们需要分析页面请求。这包括分析页面上的所有 AJAX 请求和参数。
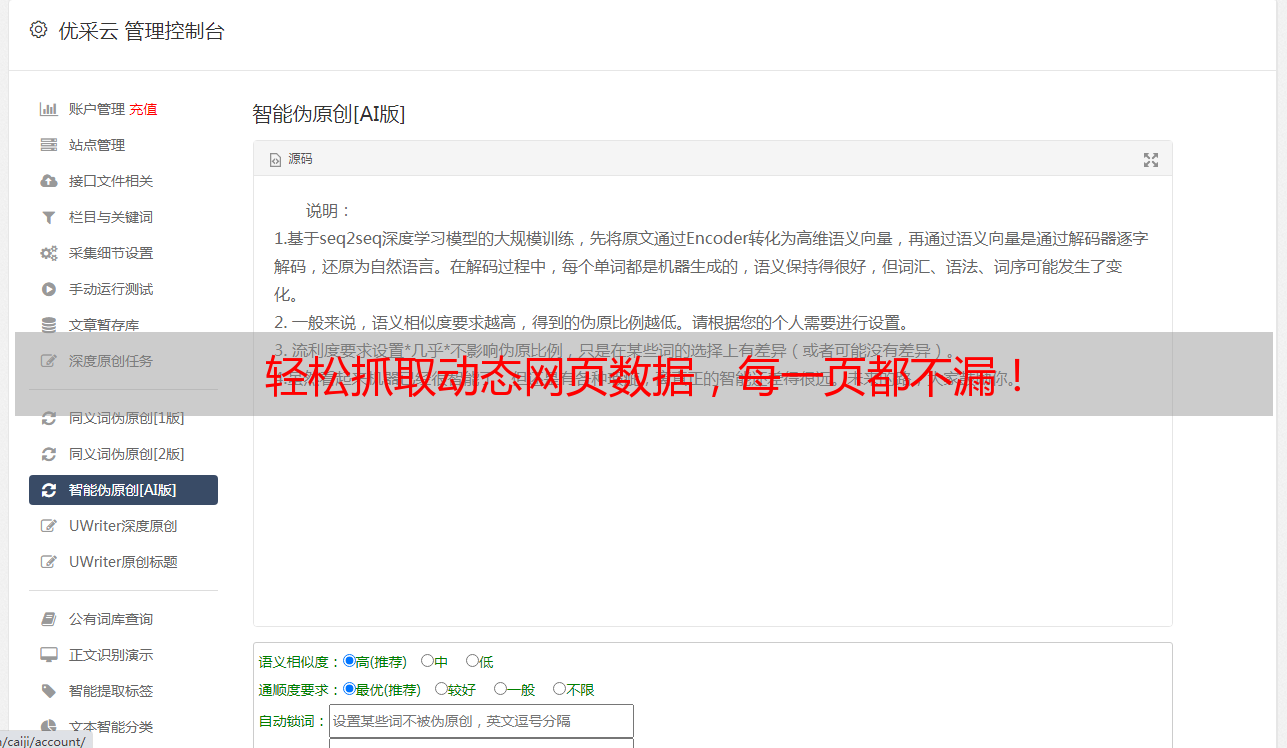
3.模拟请求并获取数据
接下来,我们需要模拟请求并获取数据。为此,我们可以使用 Python 中的 requests 库或 Scrapy 框架。这些工具可以帮助我们发送请求并获取响应。
4.解析 HTML 页面
一旦我们获得了响应,我们需要解析 HTML 页面以提取所需的数据。为此,我们可以使用 Python 中的 Beautiful Soup 库或 lxml 库。
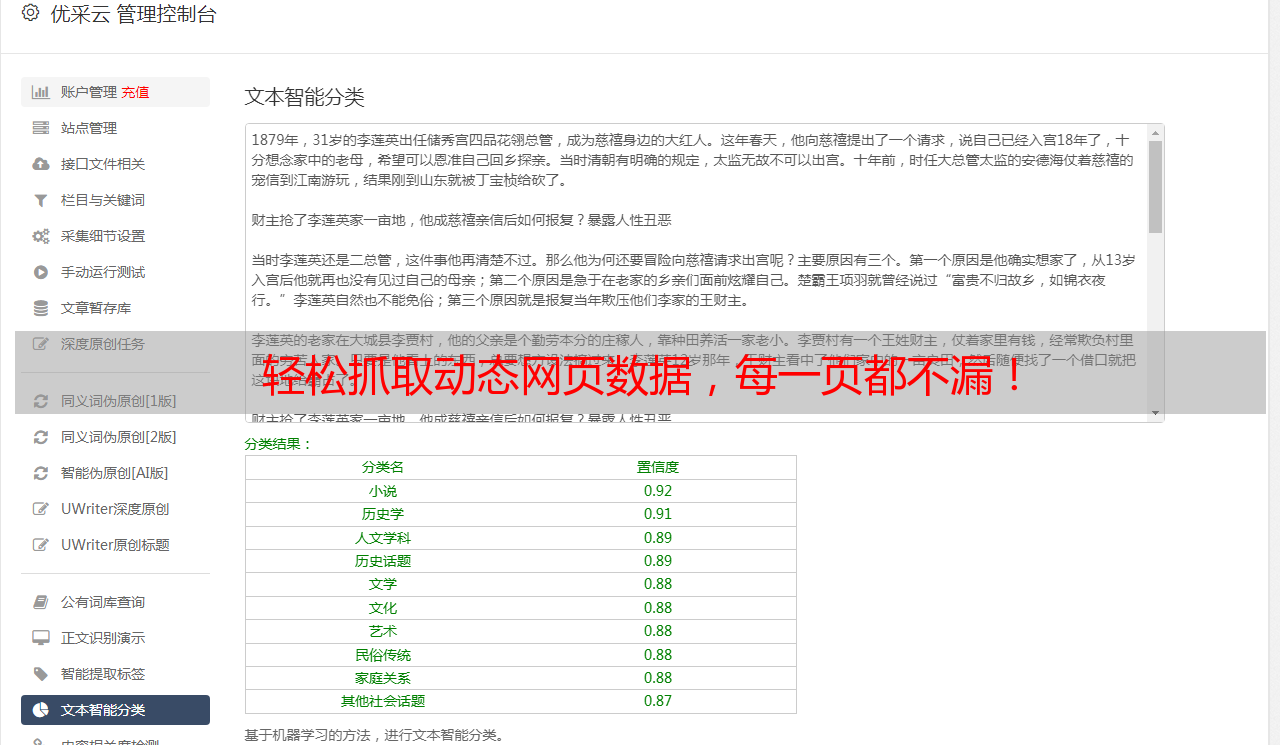
5.处理分页
如果目标网站具有分页功能,则需要处理分页。对于每一页,我们需要执行相同的操作以提取所需的数据。
6.存储数据
一旦我们提取了所需的数据,我们需要将其存储在数据库或文件中。这样,我们就可以随时访问它们。
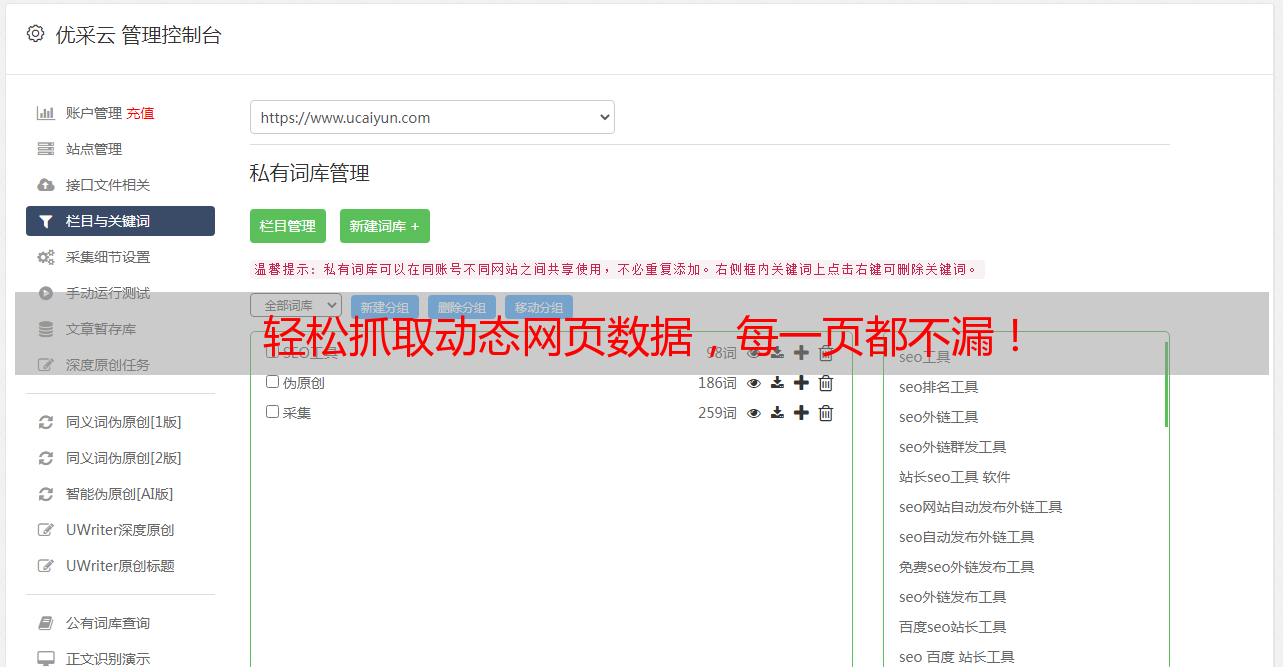
7.自动化脚本
如果您需要定期抓取动态网页上的数据,则可以编写自动化脚本来完成此任务。这样,您就可以自动执行所有步骤并定期更新数据。
8.注意事项
最后,请注意不要超过目标网站服务器的负载限制。如果您频繁地发送请求,则可能会对服务器造成过大负载压力。此外,请确保遵守相关法律法规和道德准则。
总之,抓取动态网页上的每一页数据可能比较困难,但如果您遵循上述步骤并仔细考虑每个步骤,则应该能够成功完成任务。
优采云是一家专业从事 SEO 优化服务和搜索引擎营销服务的公司。他们提供高效、专业、全方位、全周期、可持续发展等优质服务。www.ucaiyun.

