解决网站爬虫获取数据问题,掌握相关技巧
优采云 发布时间: 2023-03-08 11:15在数字化时代,数据是企业和个人决策的重要依据。然而,如何获取大量、高质量的数据成为了一项挑战。网站爬虫技术应运而生,成为了一个高效的数据获取方式。本文将从以下十个方面深入探讨网站爬虫获取数据的相关问题。
1.什么是网站爬虫?
2.网站爬虫的分类及应用场景
3.网站爬虫的工作原理
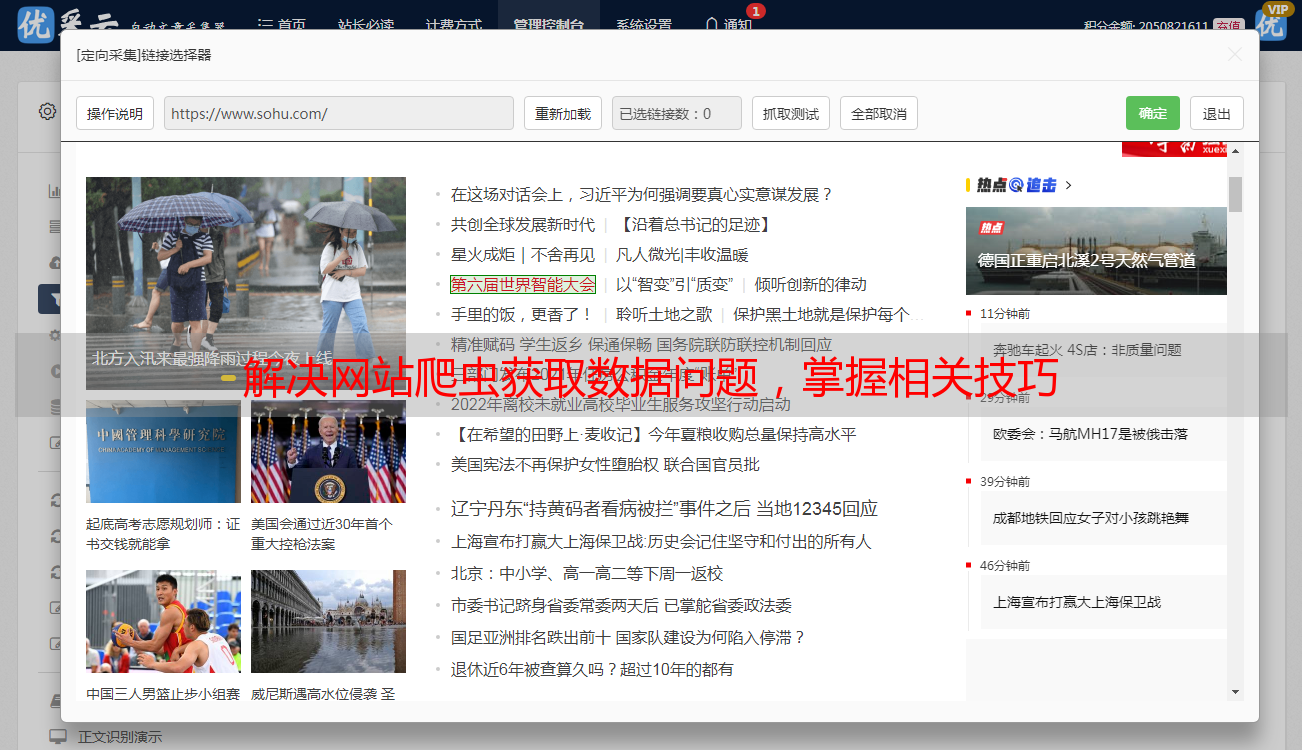
4.网站爬虫中遇到的问题及解决方案
5.如何规避法律风险
6.网站反爬虫机制及应对策略
7.如何优化网站爬虫效率
8.数据存储与处理
9.网站爬虫在SEO优化中的应用
10.优采云提供的网站爬虫服务
1.什么是网站爬虫?
网站爬虫是一种自动化程序,可以模拟人类在浏览器上访问网页,并从中抓取所需信息。它可以遍历整个互联网,并按照一定规则抓取目标网页上的数据并保存下来。
2.网站爬虫的分类及应用场景
根据其特点和用途,网站爬虫可以分为通用型、聚焦型、深度型、增量型等多种类型。它们广泛应用于搜索引擎、电商价格监控、社交网络分析、金融投资分析等领域。
3.网站爬虫的工作原理
网站爬虫通过HTTP协议向目标服务器发送请求,并获取服务器返回的HTML代码。然后,它会对HTML代码进行解析和处理,提取出所需数据并保存到本地或数据库中。
4.网站爬虫中遇到的问题及解决方案
在进行网站爬取时,可能会遇到IP封禁、验证码识别、反扒机制等问题。这些问题可以通过使用代理IP、验证码自动识别软件以及模拟人类操作等方式进行解决。
5.如何规避法律风险
在进行网站爬取时,需要注意遵循相关法律法规,如《计算机软件保护条例》等。同时,也需要尊重被抓取网页所属公司或个人的知识产权和隐私权。
6.网站反爬虫机制及应对策略
为了防止被不良行为者利用,很多网站都设置了反扒机制。这些机制包括IP限制、验证码识别、JS渲染等。针对这些机制,可以采用IP代理池、验证码识别软件以及PhantomJS等技术进行绕过。
7.如何优化网站爬虫效率
为了提高网站爬取效率,可以采用多线程技术、异步IO模式以及分布式架构等手段进行优化。
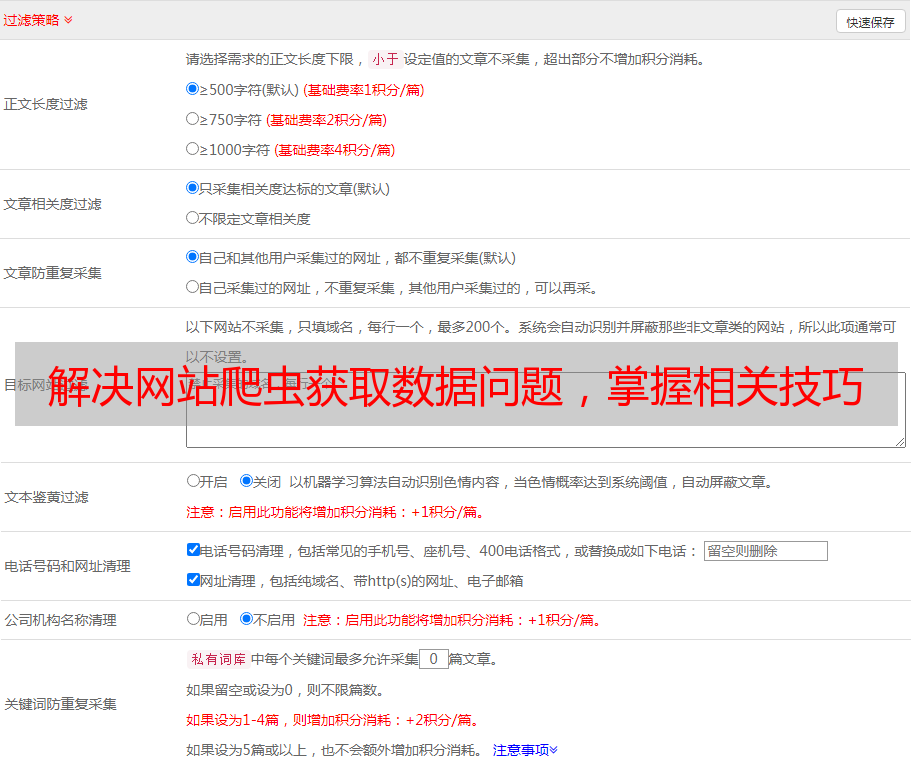
8.数据存储与处理
在进行*敏*感*词*数据抓取后,需要将数据存储到本地或数据库中,并进行清洗和处理。这些工作可以通过使用Python等编程语言来实现。
9.网站爬虫在SEO优化中的应用
通过对竞争对手关键词排名情况以及用户搜索习惯进行分析,可以为SEO优化提供有力支持。同时,在进行内容创作时,也可以借鉴竞争对手或同行业相关信息来提高内容质量。
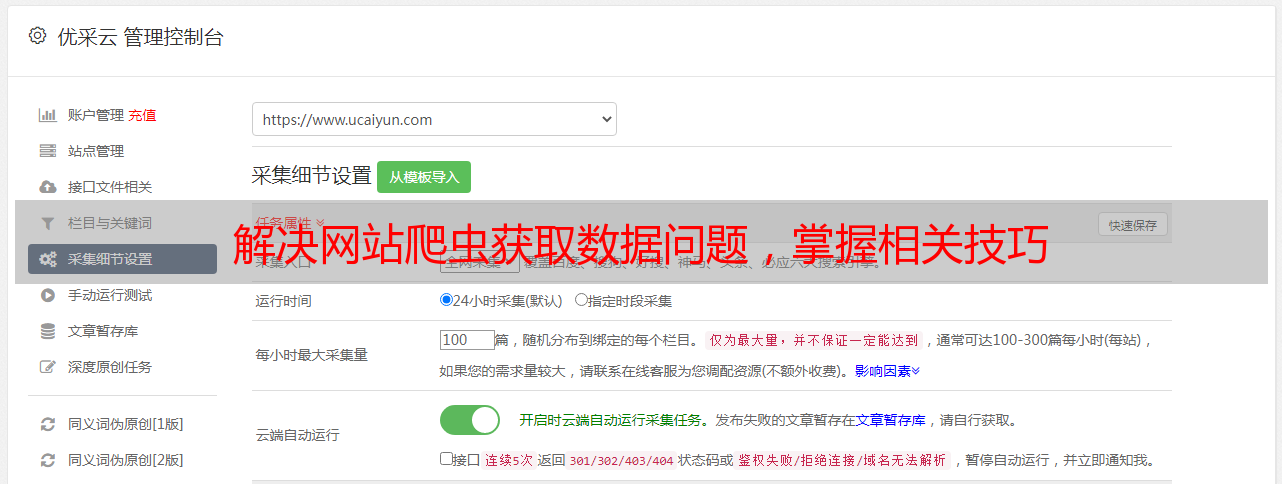
10.优采云提供的网站爬虫服务
作为国内领先的大数据服务商之一,优采云提供了多款专业级别的网络抓取工具和服务。无论您是需要进行市场调研还是产品价格监控,我们都能为您提供最好的解决方案。
总之,在当今信息化时代,利用网站爬虫技术获取大量高质量数据已经成为各行业不可或缺的手段之一。希望本文能够帮助读者更好地了解并运用该技术。如果您有更多关于此方面问题,请访问我们官方网址:www.ucaiyun.com,获取更多信息与帮助!

