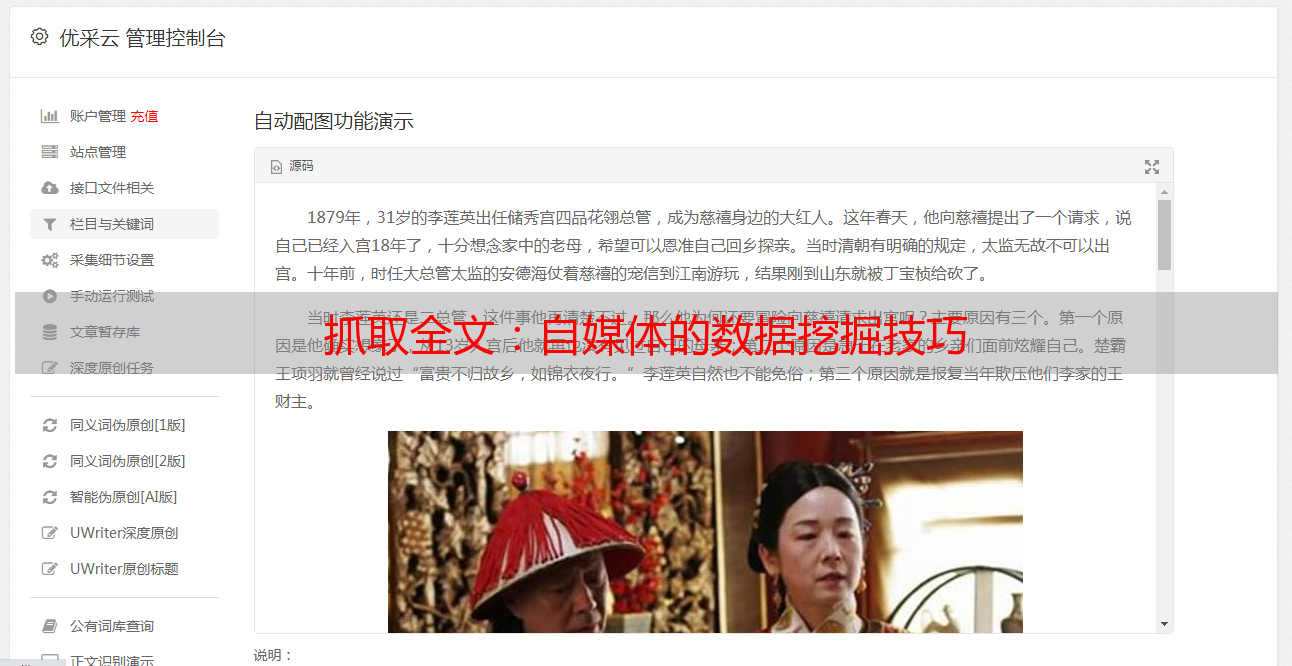
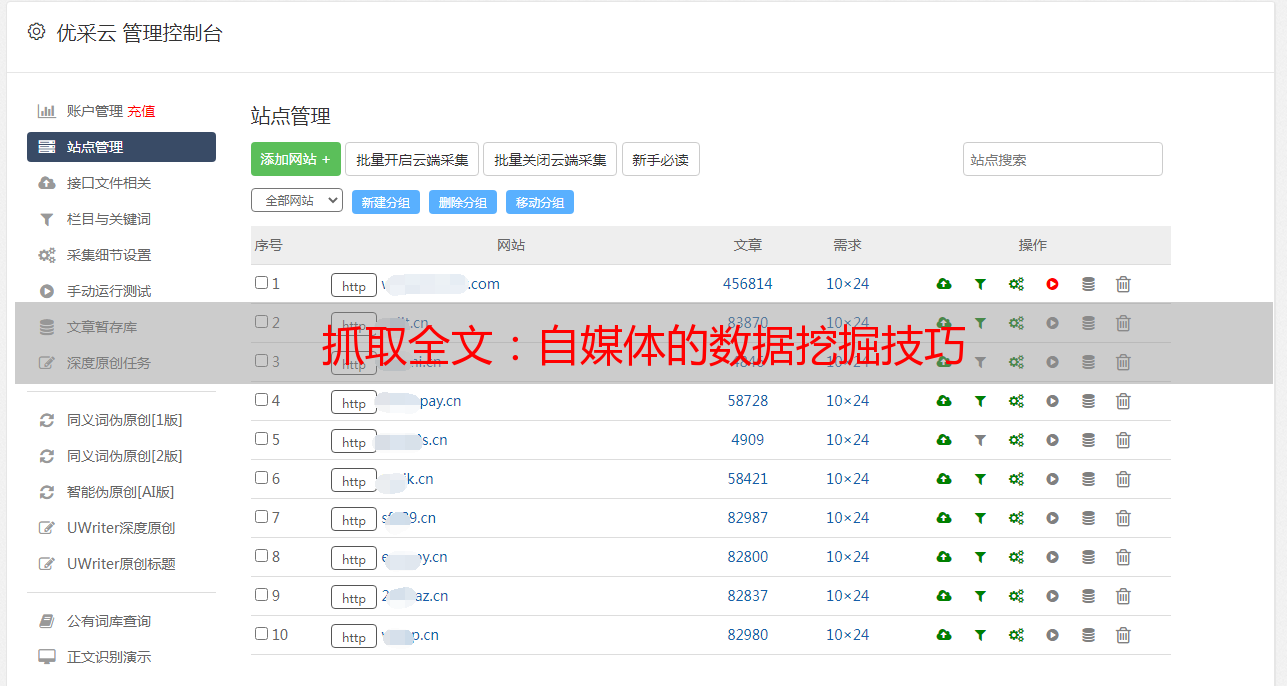
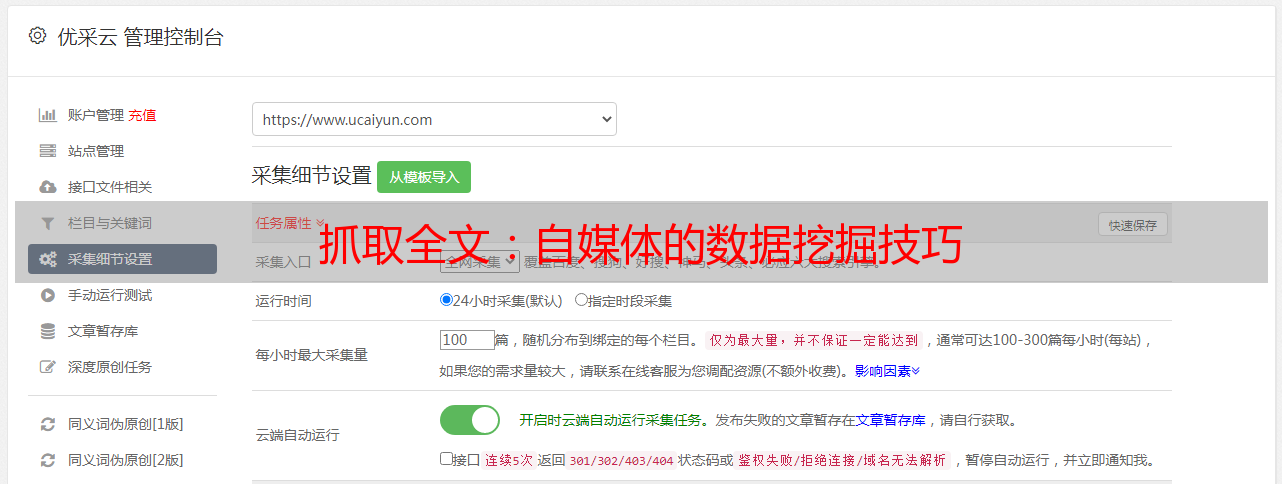
抓取全文:自媒体的数据挖掘技巧
优采云 发布时间: 2023-03-05 15:12在当今信息爆炸的时代,获取信息已经变得异常容易,但是真正有价值的信息却常常被埋没在海量数据之中。而作为一名自媒体从业者,如何从这些海量数据中抓取到有价值的全文,是我们必须掌握的技能之一。本文将从10个方面进行逐步分析讨论,帮助你成为抓取全文的高手。
一、明确目标
在抓取全文之前,你需要明确你想要获取哪些信息,并对这些信息进行分类整理。只有明确了目标,才能更加针对性地进行全文抓取。
二、选择合适的工具
全文抓取可以使用多种工具,如Python、Scrapy等。但是不同的工具适用于不同的网站和数据类型。因此,在选择工具时需要根据目标网站和数据类型进行选择。
三、了解网站结构
在进行全文抓取时,需要对目标网站的结构进行了解。包括页面布局、HTML结构等。只有了解了网站结构,才能更好地定位所需信息。
四、模拟浏览器行为
有些网站会对爬虫进行反爬虫处理,因此需要模拟浏览器行为来规避反爬虫策略。可以使用Selenium等工具来模拟浏览器行为。
五、设置请求头
设置请求头可以让我们更好地伪装成浏览器进行访问,并且在一定程度上规避反爬虫策略。请求头中应包含User-Agent、Referer等信息。
六、处理动态加载
有些网站采用Ajax等动态加载技术来提高用户体验,因此需要对动态加载进行处理。可以使用PhantomJS等工具来处理动态加载。
七、使用正则表达式提取信息
在获取到HTML源码后,需要使用正则表达式来提取所需信息。正则表达式是一种强大而灵活的匹配工具,在全文抓取中非常重要。
八、使用XPath提取信息
XPath是一种用于选择XML文档中特定部分的语言。在进行全文抓取时,可以使用XPath来提取所需信息,并且XPath比正则表达式更加精准。
九、保存数据
在完成全文抓取后,需要将所得到的数据保存下来。可以保存为txt、csv等格式,并且可以使用MySQL等数据库来存储数据。
十、SEO优化
最后,在完成全文抓取后,还需要对文章进行SEO优化。包括关键词密度、标题优化等。只有做好SEO优化,才能让文章更好地被搜索引擎收录和推荐。
总结:
以上10个方面都是进行全文抓取必不可少的技能点,在实践中需要灵活运用,并且不断学习和探索新的技术和方法。如果你想学习更多关于全文抓取和SEO优化方面的知识,请访问优采云官网www.ucaiyun.com。优采云致力于为自媒体从业者提供最专业的SEO优化服务和技术支持!

