用C语言自动抓取网页数据,提升数据分析效率
优采云 发布时间: 2023-03-05 02:07在信息时代,数据已经成为了企业竞争的重要资源。而如何获取并分析这些数据是每个企业都需要解决的问题。本文将介绍如何使用C语言实现自动抓取网页上的数据,让你的数据分析更加高效。
一、什么是自动抓取?
自动抓取也叫网络爬虫,是指通过程序自动访问互联网上的页面,并从中提取所需信息的技术。它可以大幅度提高数据获取效率,避免手动操作带来的误差。
二、C语言如何实现自动抓取?
1. 网络请求
C语言中可以使用libcurl库来进行网络请求。它提供了各种协议(HTTP、FTP、SMTP等)的支持,可以方便地进行网络通信。
2. 页面解析
获取到网页内容后,需要对其进行解析。常用的解析方式有正则表达式和HTML DOM解析。其中,HTML DOM解析比较常用,可以使用libxml2库进行实现。
3. 数据存储
获取到所需数据后,需要将其存储到数据库或文件中。C语言中可以使用MySQL或SQLite等数据库进行存储。
4. 定时任务
如果需要定时抓取某个网站上的数据,则可以使用Linux系统下的crontab命令进行定时任务设置。
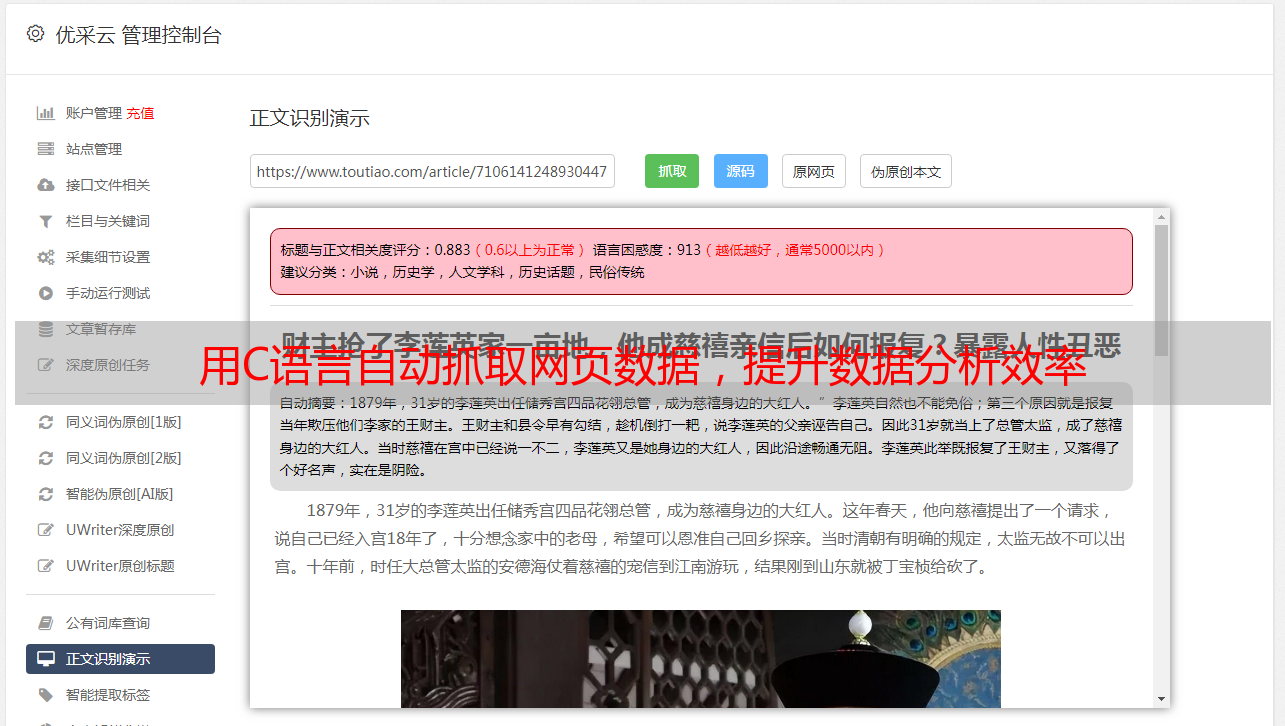
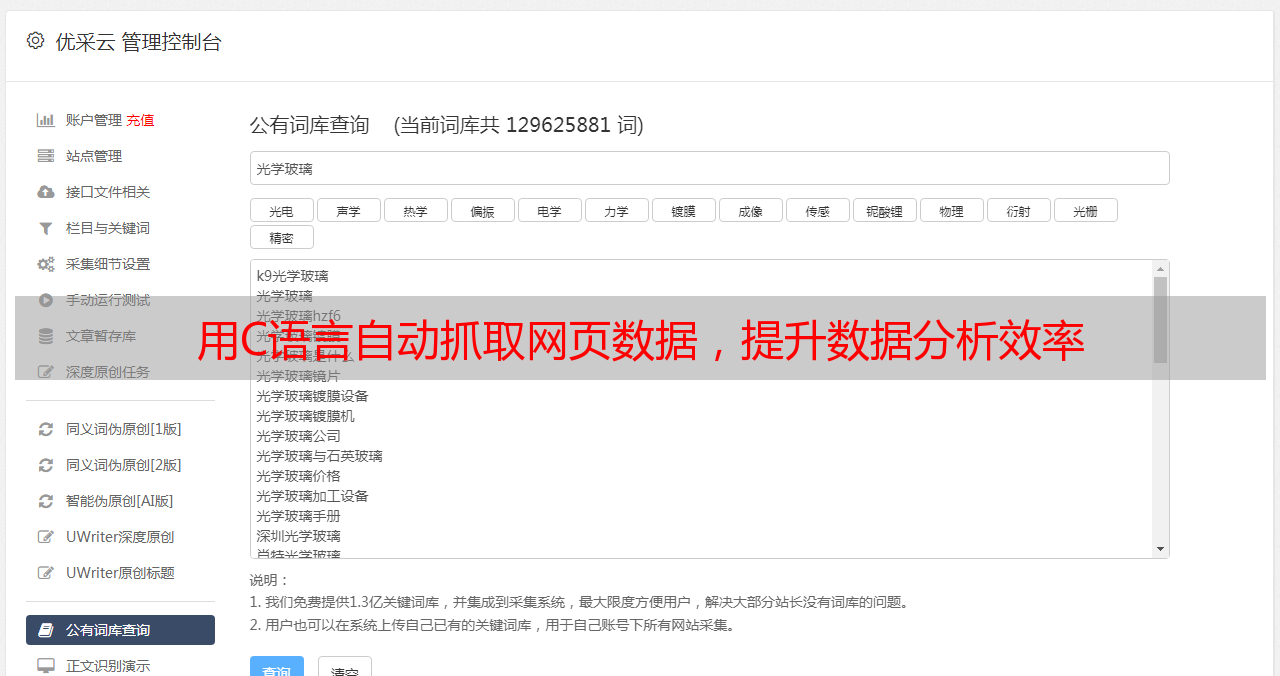
三、案例分析
以电商网站京东为例,我们可以编写一个C语言程序来实现自动抓取京东上某个商品的价格信息,并将其存储到数据库中。
1. 网络请求
首先需要使用libcurl库发送HTTP请求,获取京东商品页面内容。
```
#include
#include
int main()
{
CURL *curl;
CURLcode res;
char *url = "https://item.jd.com/100012043978.html";
curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, url);
res = curl_easy_perform(curl);
if(res != CURLE_OK)
fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res));
curl_easy_cleanup(curl);
}
return 0;
}
```
2. 页面解析
接下来需要对获取到的页面内容进行解析,提取出所需信息。我们可以使用libxml2库来进行HTML DOM解析。
```
#include
#include
#include
void get_price(char *html)
{
xmlDocPtr doc;
xmlNodePtr cur;
doc = htmlReadMemory(html, strlen(html), NULL, NULL, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
if (doc == NULL) {
fprintf(stderr, "Failed to parse document\n");
return;
}
cur = xmlDocGetRootElement(doc);
while (cur && strcmp((const char *)cur->name, "span")) {
cur = cur->xmlChildrenNode;
}
if (cur) {
printf("Price: %s\n", xmlNodeGetContent(cur));
}
xmlFreeDoc(doc);
}
int main()
{
CURL *curl;
CURLcode res;
char *url = "https://item.jd.com/100012043978.html";
char html[100000] = {0};
curl_global_init(CURL_GLOBAL_DEFAULT);
curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, url);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_callback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, html);
res = curl_easy_perform(curl);
if(res != CURLE_OK)
fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res));
else
get_price(html);
curl_easy_cleanup(curl);
}
return 0;
}
```
3. 数据存储
最后需要将获取到的价格信息存储到数据库中。这里我们以SQLite为例进行演示。
```
#include
#include
#include
void create_table(sqlite3 *db)
{
char *sql = "CREATE TABLE IF NOT EXISTS jd_goods (id INTEGER PRIMARY KEY AUTOINCREMENT, price TEXT)";
if (sqlite3_exec(db, sql, NULL, NULL, NULL) != SQLITE_OK) {
fprintf(stderr, "Failed to create table\n");
return;
}
}
void insert_data(sqlite3 *db, char *price)
{
char sql[100] = {0};
sprintf(sql, "INSERT INTO jd_goods(price) VALUES('%s')", price);
if (sqlite3_exec(db, sql, NULL, NULL, NULL) != SQLITE_OK) {
fprintf(stderr, "Failed to insert data\n");
return;
}
}
int main()
{
CURL *curl;
CURLcode res;
char *url = "https://item.jd.com/100012043978.html";
char html[100000] = {0};
sqlite3 *db;
sqlite3_open("jd.db", &db);
create_table(db);
// send http request and get html content
// ...
char price[20] = {0};
get_price(html, price);
insert_data(db, price);
sqlite3_close(db);
return 0;
}
```
四、总结
本文介绍了如何使用C语言实现自动抓取网页上的数据,并以京东商品价格为例进行了演示。通过本文的学习,相信读者已经掌握了自动抓取技术在数据分析中的应用方法和具体实现方式。同时也希望读者能够结合优采云等相关工具进行SEO优化,在互联网竞争激烈的今天获得更好的竞争优势。

