高效信息收集体系建设:网页文档采集知识与技巧
优采云 发布时间: 2023-03-05 00:09在信息化时代,互联网上的信息量庞大,如何快速且准确地采集到所需信息成为了一项必备技能。而网页文档采集正是这一领域中最重要的一环。本文将从以下九个方面详细介绍网页文档采集的相关知识和技巧,帮助读者打造高效的信息收集体系。
1. 网页文档采集的基本概念和原理
2. 常见的网页文档采集工具及其优缺点
3. 如何选择适合自己的网页文档采集工具
4. 网页文档采集中需要注意的法律问题
5. 网页文档采集中需要注意的道德问题
6. 网页文档采集中如何应对反爬虫机制
7. 网页文档采集后如何进行数据清洗和预处理
8. 如何将网页文档采集应用于SEO优化
9. 优采云——一款高效、智能、安全的网页文档采集工具
网页文档采集是指通过程序或软件自动化地从互联网上抓取特定网站或页面上的数据,并将抓取到的数据保存到本地或数据库中。其基本原理是通过HTTP协议向目标服务器发送请求,获取服务器返回的HTML代码,并通过解析HTML代码来提取所需数据。
常见的网页文档采集工具包括Python中的BeautifulSoup、Scrapy、Selenium等,以及第三方工具如Apify、Octoparse等。每种工具都有其独特的优缺点,在选择时需要根据自身需求进行权衡。
在选择适合自己的网页文档采集工具时,需要考虑多个因素,包括所需数据类型、抓取频率、数据量等。同时还需要注意遵守相关法律法规和道德规范,避免侵犯他人权益。
在进行网页文档采集时,需要注意反爬虫机制可能对抓取过程造成影响。为了避免被封禁IP或验证码等情况,可以使用代理IP、伪装请求头等方法进行反制。
完成网页文档采集后,还需要进行数据清洗和预处理。这一步骤可以通过正则表达式、字符串替换等方式来实现。
将网页文档采集应用于SEO优化可以极大地提高搜索引擎排名。通过分析竞争对手关键词、页面结构等因素并结合抓取到的数据来进行优化。
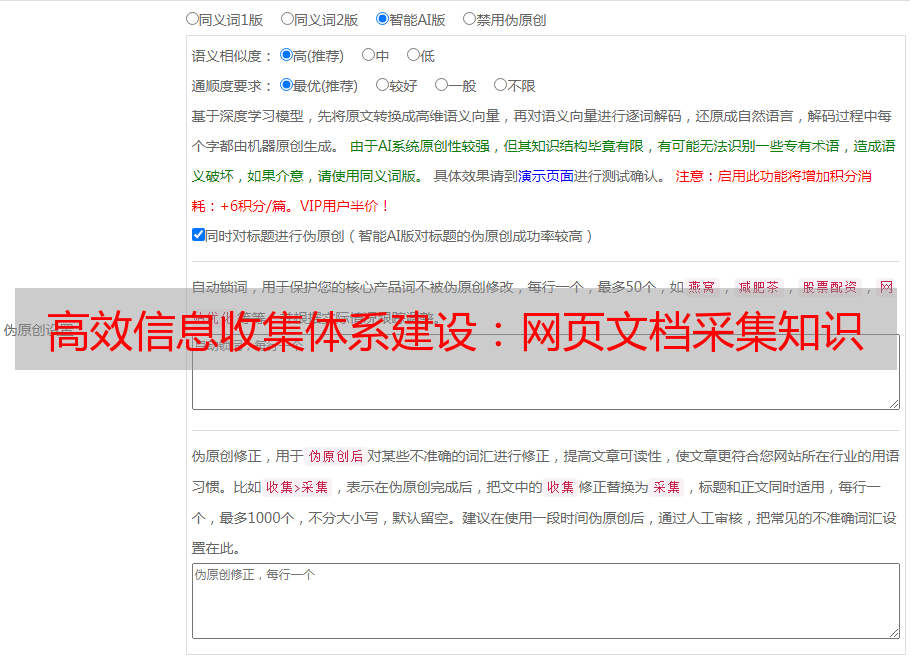
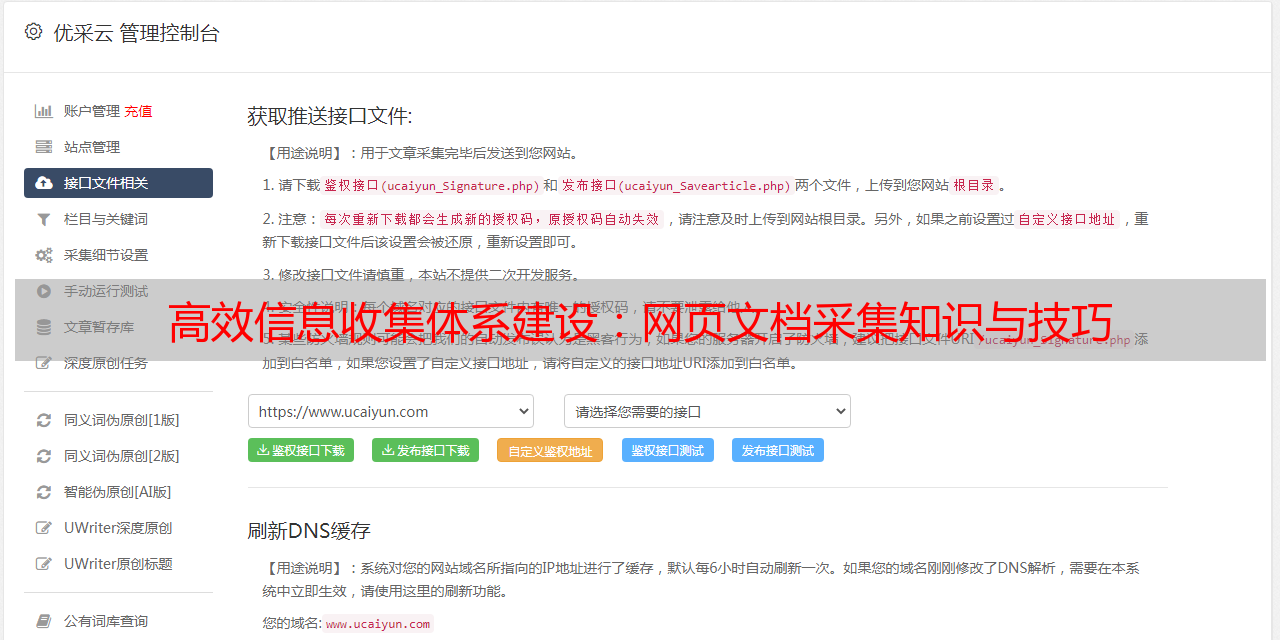
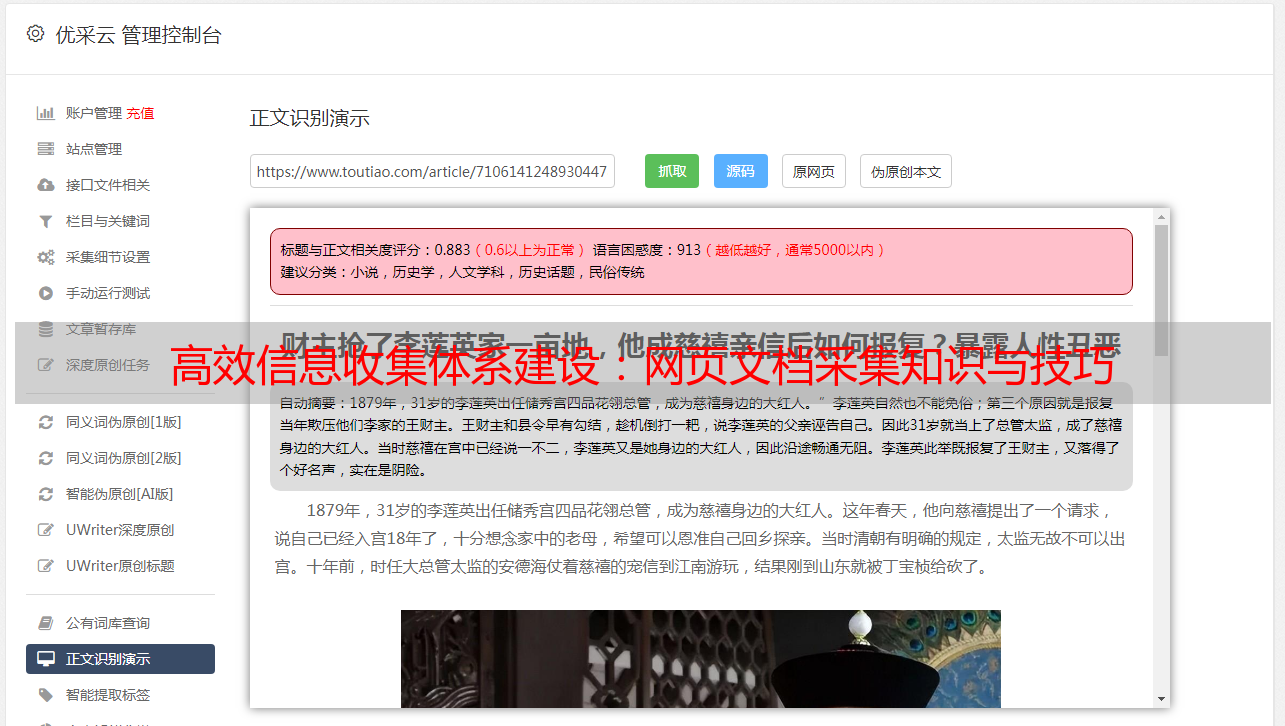
优采云是一款专业、高效、智能、安全的网页文档采集工具。它支持多种数据导出格式和自定义脚本,并且拥有强大而稳定的分布式架构和智能任务调度系统。使用优采云可以轻松实现海量数据爬取与处理任务。
总之,在学习和实践网页文档采集过程中,我们需要不断学习和探索新技术,并注重遵守相关法律法规和道德规范。同时也要选择适合自己需求并可靠稳定的工具来完成任务。

