SEO问题解答优化-网站SEO优化论坛问答(组图)
优采云 发布时间: 2021-06-10 23:12
SEO问题解答优化-网站SEO优化论坛问答(组图)
关于百度搜索引擎的工作原理,很多站长没有仔细阅读和理解SEO。本文讲解了Baiduspider爬取系统的原理和索引构建,让SEOer可以更多的了解百度蜘蛛的收录索引构建库。了解详情。
SEO问答SEO优化-网站SEO优化论坛问答交流-冉登SEO搜索学院 一、蜘蛛爬虫系统基本框架
互联网信息爆炸式增长,如何有效地获取和使用这些信息是搜索引擎工作的首要环节。数据采集系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,所以通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网蜘蛛等。
蜘蛛抓取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以看作是对这个有向图的一次遍历。从一些重要的*敏*感*词*网址开始,通过页面上的超链接关系,不断地发现和抓取新的网址,尽可能多地抓取有价值的网页。对于像百度这样的大型蜘蛛系统,由于网页随时可能被修改、删除或出现新的超链接,因此需要更新以往蜘蛛抓取的页面,并维护一个网址库和页面库。
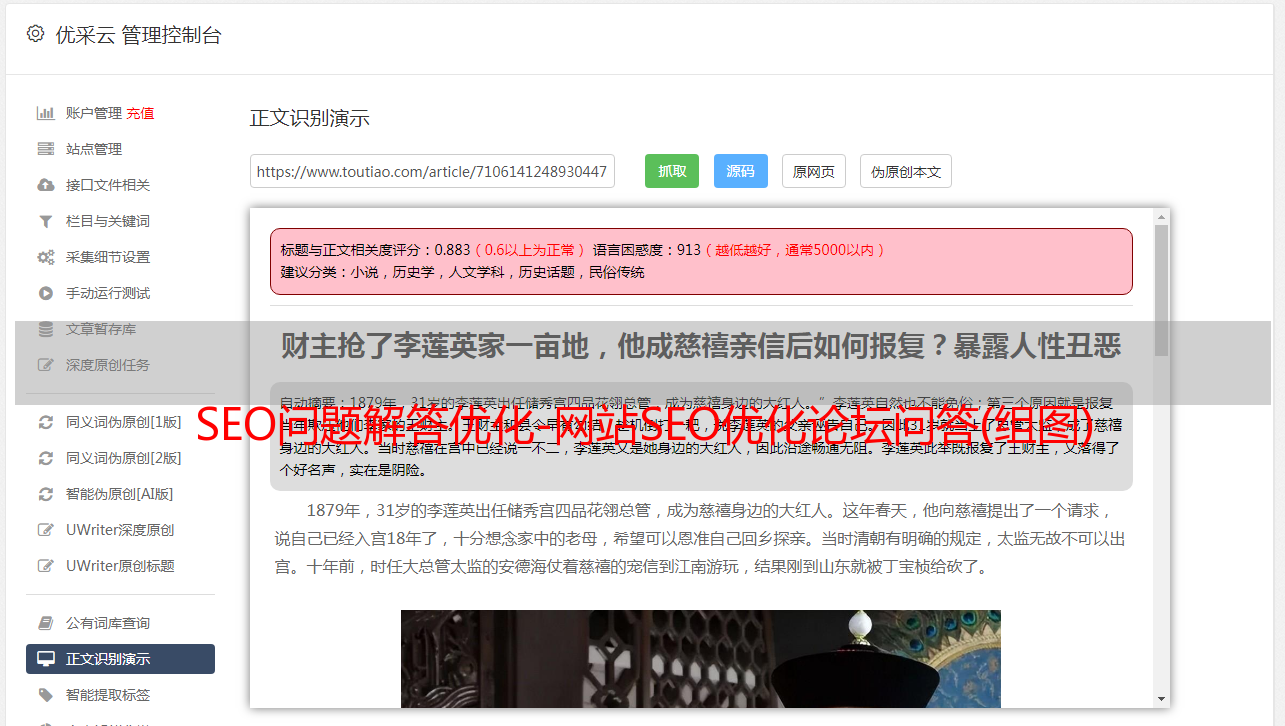
下图是蜘蛛抓取系统的基本框架,包括链接存储系统、链接选择系统、dns分析服务系统、抓取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成了对网页的抓取。
二、百度蜘蛛的主要爬取策略类型
上图看似简单,但Baiduspider在爬取过程中实际上面临着一个超级复杂的网络环境,为了让系统尽可能多的抓取有价值的资源,维护系统和实际环境中的页面。同时网站体验的一致性不会造成压力,会设计多种复杂的爬取策略。下面简单介绍一下:
1.爬虫友好
互联网资源具有巨大的数量级,这就要求抓取系统尽可能高效地使用带宽,在有限的硬件和带宽资源下抓取尽可能多的有价值的资源。这会导致另一个问题。捕获的网站带宽被消耗,造成访问压力。如果度数过大,会直接影响抓到的网站的正常用户访问行为。因此,在爬取过程中,必须控制一定的爬取压力,以达到不影响网站正常用户访问,尽可能多的抓取有价值资源的目的。
通常,最基本的是基于ip的压力控制。这是因为如果是基于一个域名,可能会出现一个域名对应多个ip(很多大网站)或者多个域名对应同一个ip(小网站share ip)的问题。在实际中,压力部署控制往往是根据ip和域名的各种情况进行的。同时,站长平台也推出了压力反馈工具。站长可以手动调整他的网站的抓取压力。此时百度蜘蛛会根据站长的要求,优先进行抓取压力控制。
对同一个站点的抓取速度控制一般分为两类:一类是一段时间内的抓取频率;二是一段时间内的爬取流量。同一个站点的爬取速度在不同的时间会有所不同。例如,在夜晚安静、月亮暗、风大的时候,爬行速度可能会更快。它还取决于特定的站点类型。主要思想是错开正常用户访问的高峰期,不断调整。对于不同的网站,也需要不同的抓取速度。
3.新链接重要性判断
建库链接前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断网页是否需要建索引库,通过链接分析找到更多的网页,然后抓取更多网页————分析——是否建库&发现新链接的过程。理论上,百度蜘蛛会检索到新页面上所有可以“看到”的链接。那么,面对众多的新链接,百度蜘蛛是根据什么判断哪个更重要呢?两个方面:
首先,对用户的价值是独一无二的。百度搜索引擎喜欢独特的内容突出。不要被搜索引擎误判为空洞和短小。页面未抓取。内容丰富的广告是合适的。二、链接重要性、目录级别——浅优先链接在站点中的流行程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页面数量并不是最重要的。重要的是一个索引数据库建了多少页,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。优质的网页会被分配到重要的索引库,普通的网页会留在普通的图书馆,更糟糕的网页会被分配到低级别的图书馆作为补充资料。目前60%的检索需求只调用重要的索引库就可以满足,这就解释了为什么一些网站的收录量超高的流量一直不尽人意。
那么,哪些网页可以进入优质索引库呢?其实总的原则是一个:对用户有价值。包括但不仅限于:
及时性和有价值的页面:在这里,及时性和价值是平行的关系,两者缺一不可。有的网站为了生成时间敏感的内容页面,做了很多采集的工作,结果是一堆毫无价值的页面,百度不想看到。优质内容的专页:专页的内容不一定都是原创是的,就是可以很好的整合各方内容,或者添加一些新鲜的内容,比如意见、评论等,给用户内容更丰富更全面。高价值原创内容页:百度将原创定义为文章经过一定成本和大量经验形成的。不要再问我们伪原创 是否是原创。重要的个人页面:这里只是一个例子。科比已经在新浪微博上开设了一个账户。即使他不经常更新,对于百度来说,它仍然是一个极其重要的页面。 5、哪些网页不能建索引库
上述优质网页均收录在索引库中。其实网上的网站大部分根本就不是百度收录。不是百度没找到,而是建库前的筛选链接被过滤掉了。那么一开始就过滤掉了什么样的网页:
内容重复的网页:对于已经在网上的内容,百度当然不需要收录。正文内容较短的网页
一些作弊页面
更多关于aiduspider爬取系统原理和索引构建,请到百度站长论坛查看文档。

