快速采集网站所有文章的实用技巧
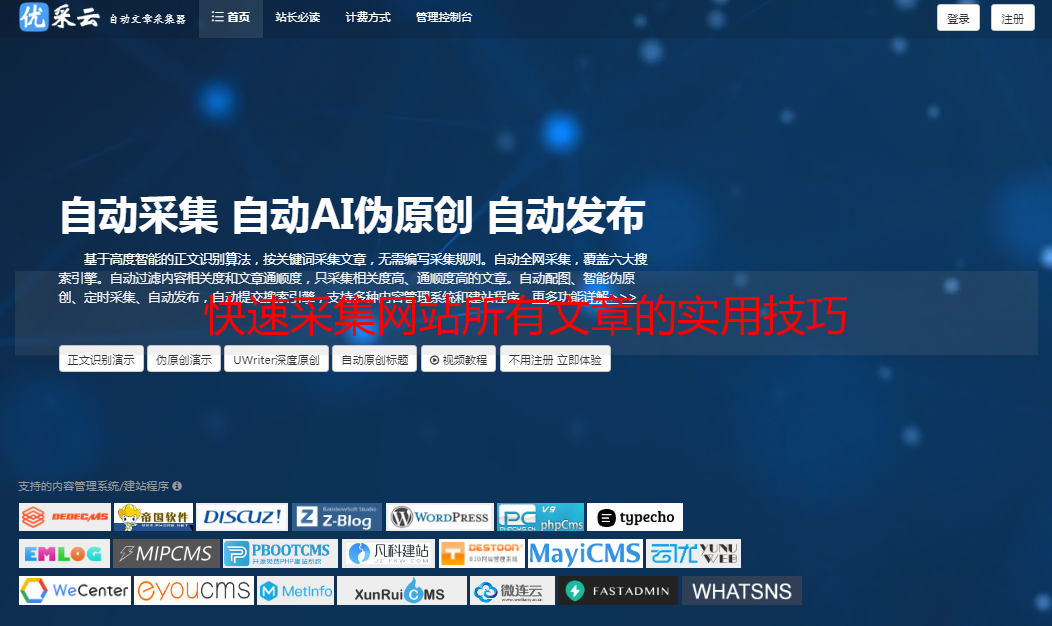
优采云 发布时间: 2023-03-04 08:10当我们在进行信息搜集时,常常需要采集某个网站的所有文章。但是,手动复制粘贴每篇文章显然是不现实的,那么怎样才能轻松、快速地采集一个网站的所有文章呢?本文将为您详细解答。
1. 确定采集工具
首先,需要找到一款专业的采集工具。市面上有很多免费或收费的采集软件,但是要选择可信赖、功能全面的软件。比如说,可以选择爬虫工具 Scrapy 或者免费开源软件 HTTrack。
2. 设定目标网站
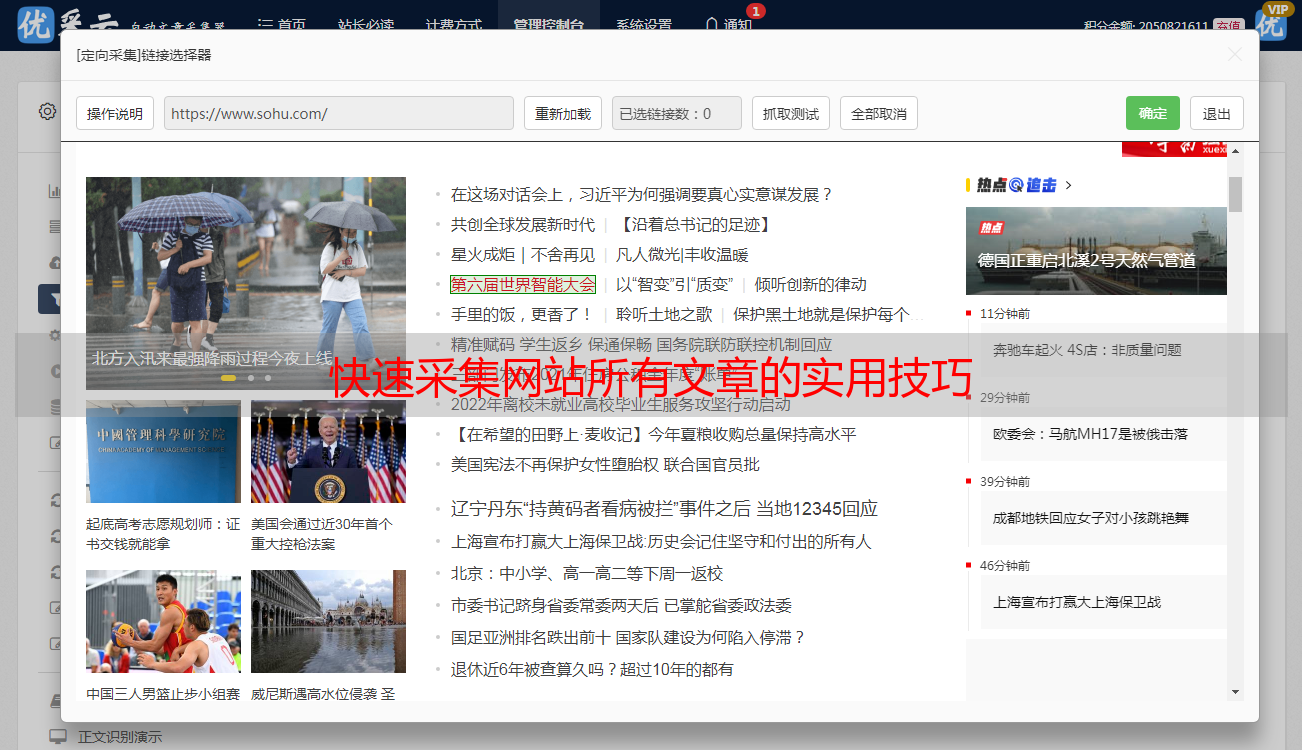
接下来,需要设定目标网站。在使用采集工具之前,需要先了解目标网站的结构和规律,并根据这些信息设置有效的规则。
3. 分析目标网站
分析目标网站是非常重要的一步。需要仔细观察目标网站的 HTML 结构、CSS 样式、JavaScript 脚本等内容,并根据实际情况设定相应规则。
4. 编写爬虫代码
在了解了目标网站并设置好规则后,就可以开始编写爬虫代码了。这部分内容比较技术性,需要有一定编程基础才能完成。
5. 运行爬虫程序
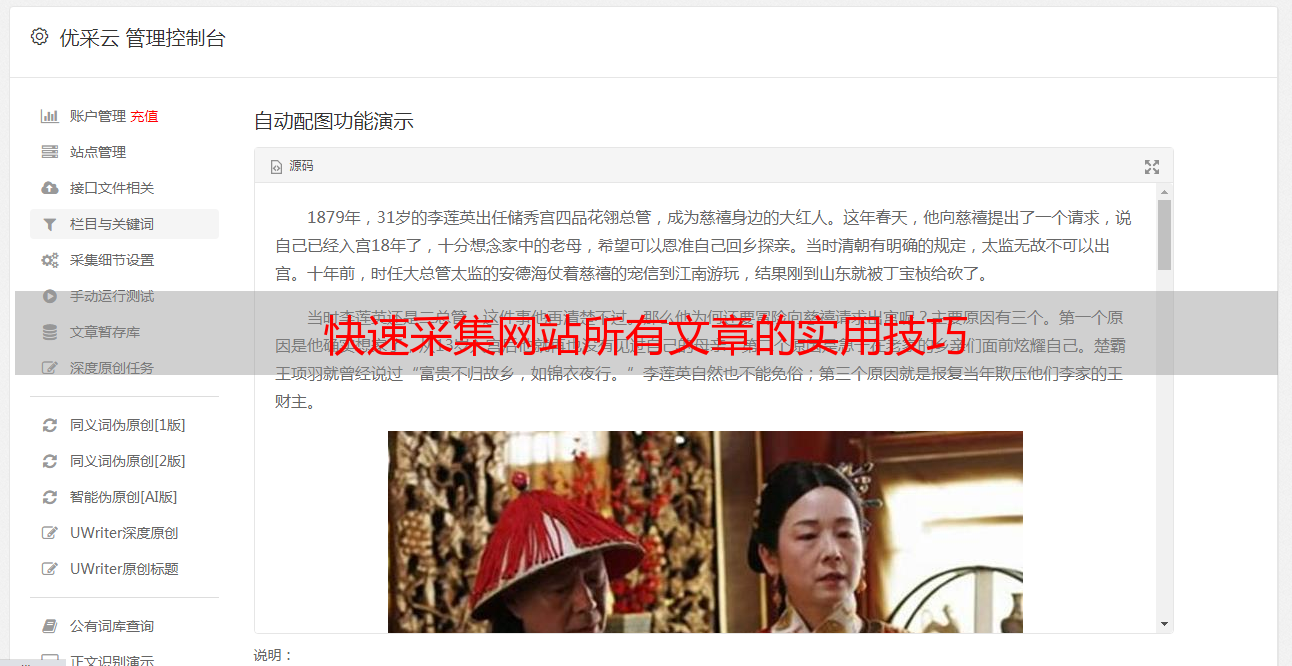
编写好爬虫程序后,就可以运行程序进行数据采集了。注意,在运行程序之前需要先测试程序是否可用,并进行必要的调整和优化。
6. 数据处理与存储
在数据采集完成后,还需要进行数据清洗和处理,并将数据存储到数据库或文件中以备后续使用。
7. 定期更新数据
如果需要定期更新采集数据,则需要设置相应的自动化任务或脚本来实现自动化更新。
8. 注意法律风险
在进行数据采集时,一定要注意遵守相关法律法规,不得侵犯他人权益。
9. 保证数据质量
对于采集到的数据,一定要保证其质量和准确性,并尽可能排除重复、错误等问题。
10. 总结与展望
通过以上步骤,我们可以轻松地采集一个网站的所有文章。未来随着技术进步和法律变化,数据采集领域也将面临更多挑战和机遇。

