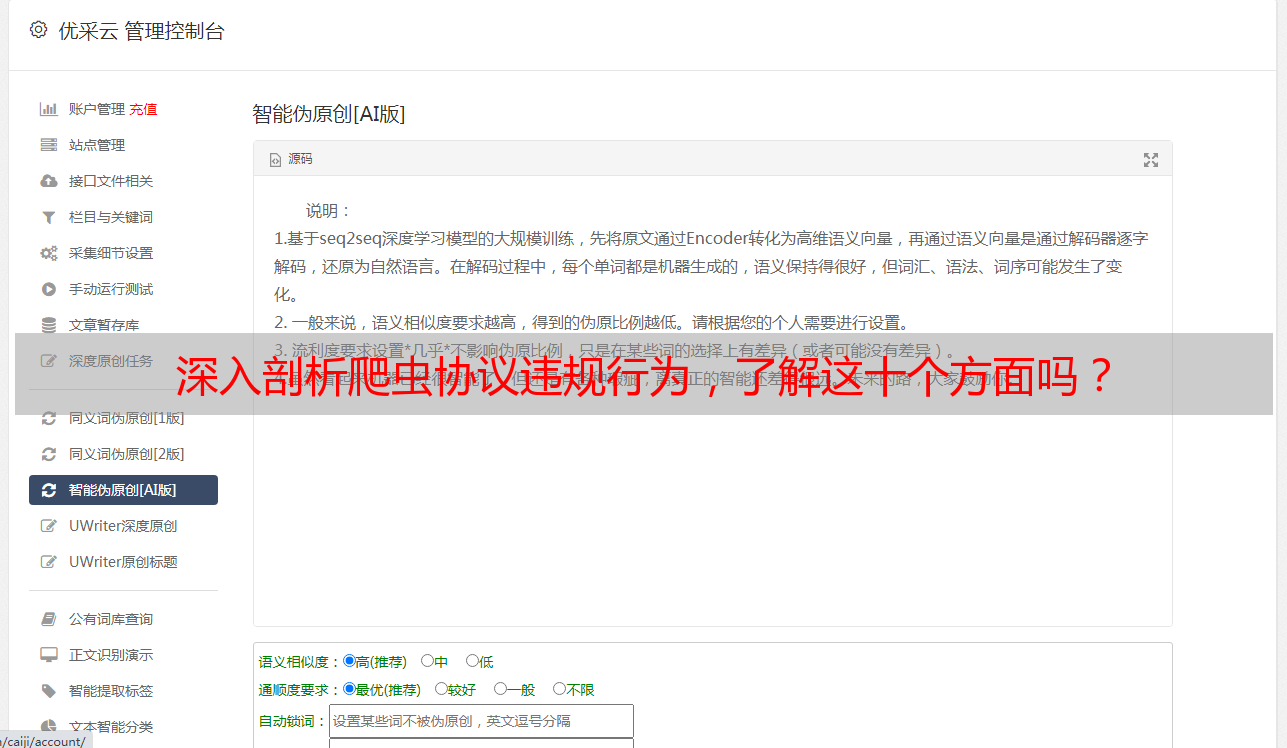
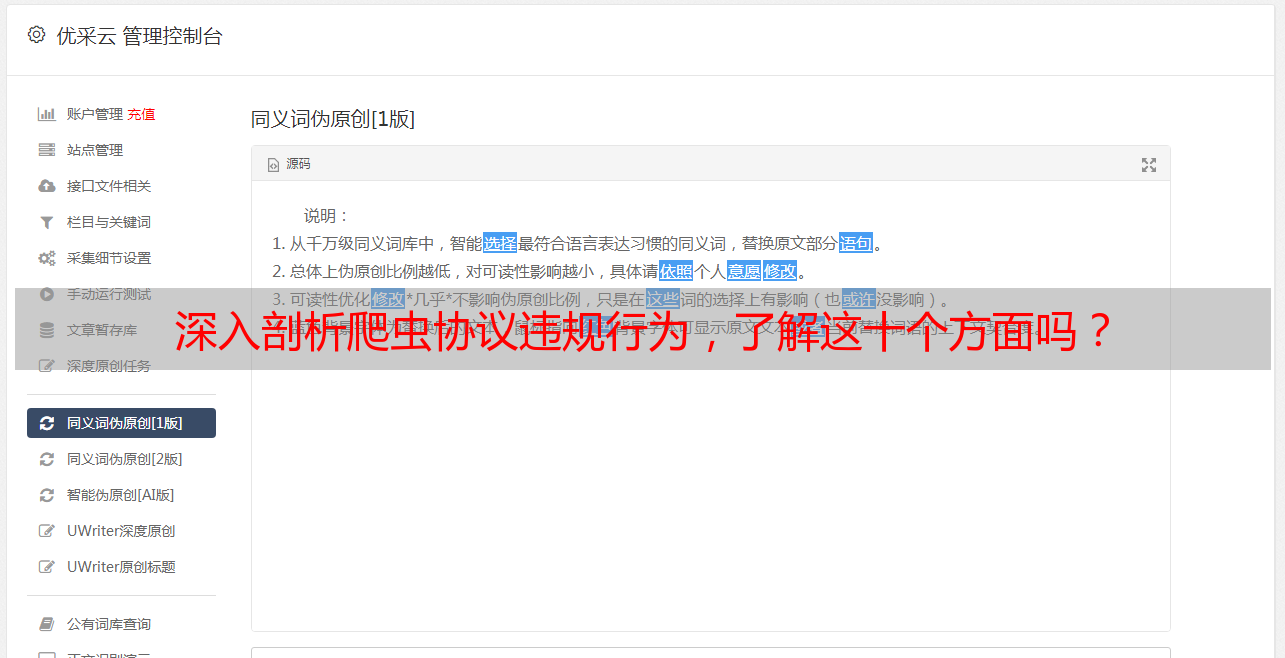
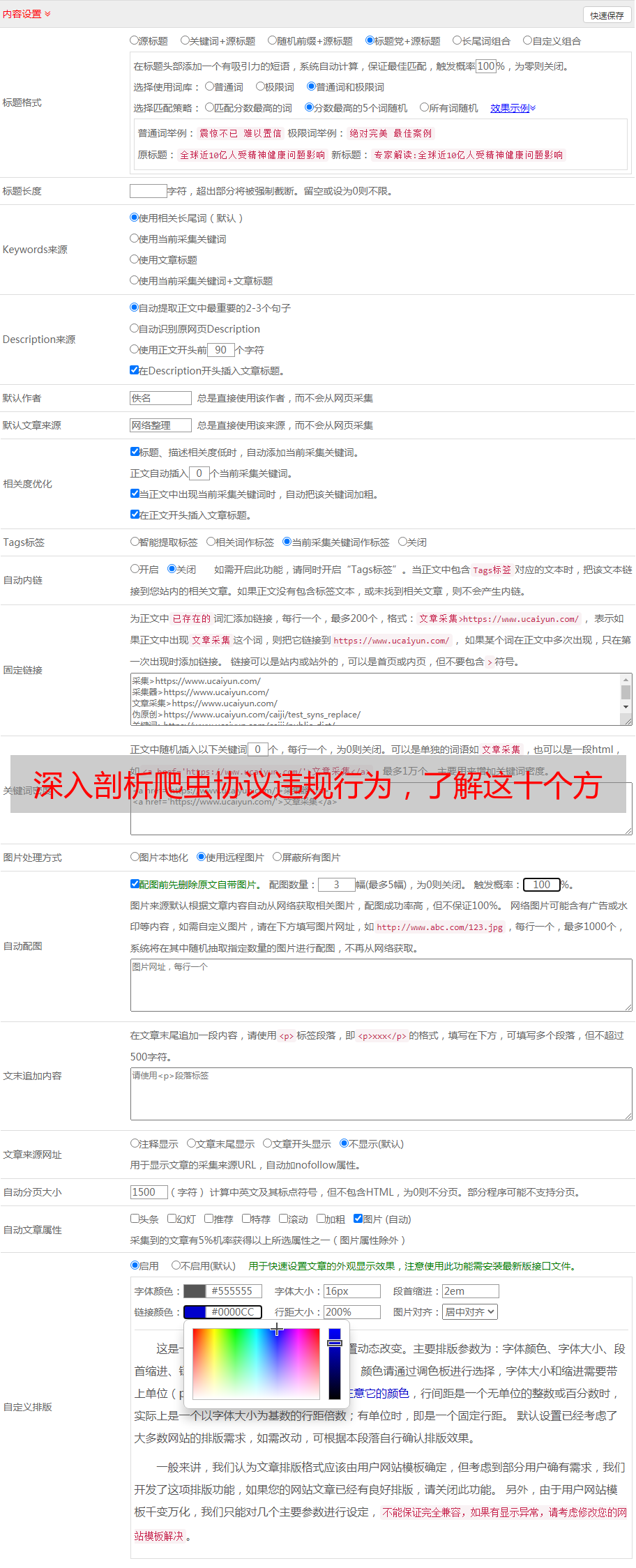
深入剖析爬虫协议违规行为,了解这十个方面吗?
优采云 发布时间: 2023-03-04 07:08近年来,随着互联网技术的不断发展,网络爬虫在信息抓取和数据分析方面扮演着越来越重要的角色。但是,在这个过程中,却有一些爬虫程序不遵守相关协议规定,侵犯了用户的合法权益,造成了不良后果。本文将从十个方面对爬虫协议违反进行详细分析。
第一、什么是爬虫协议?
爬虫协议是指网站主为了保护自己的数据而发布的一种规范性文件,一般为robots.txt文件。其中包含了该网站允许或禁止被搜索引擎或其他爬虫访问的页面或目录等信息。遵循爬虫协议可以保证爬虫程序不会抓取到网站主不希望公开的信息。
第二、为什么要遵循爬虫协议?
遵循爬虫协议可以确保你的数据安全。如果你的爬虫程序不遵循相关规定进行抓取,可能会被网站主视为攻击行为,并采取相应措施进行防范,甚至可能会面临法律诉讼。
第三、哪些行为属于违反爬虫协议?
以下行为都属于违反爬虫协议:
1.未经允许直接抓取禁止访问的页面或目录;
2.未经允许直接抓取需要登录才能访问的页面;
3.未经允许直接抓取带有验证码的页面;
4.使用伪造IP地址等手段绕过网站对某些IP地址限制的措施;
5.使用多线程同时进行大量请求,导致服务器瘫痪等后果;
6.使用恶意代码攻击目标网站等。
第四、违反爬虫协议会带来哪些后果?
违反爬虫协议可能会带来以下后果:
1.被禁止访问目标网站;
2.被封IP地址;
3.被列入黑名单,影响以后的搜索排名和曝光率;
4.面临法律诉讼等。
第五、如何遵守爬虫协议?
遵守爬虫协议需要注意以下几点:
1.在开始抓取前查看目标网站是否有robots.txt文件,并按照规定进行操作;
2.尽量使用合法手段获取数据,如通过API接口获取数据等;
3.设置合理的请求间隔时间和请求次数限制,以避免对目标网站造成负担。
第六、如何处理因违反爬虫协议而被封禁IP地址?
如果因为违反了某个网站的规定而被封禁了IP地址,可以通过以下几种方式解决:
1.暂停使用该IP地址并更换其他IP地址进行操作;
2.与网站管理员联系并说明情况,争取解除封禁。
第七、如何处理因违反爬虫协议而被列入黑名单?
如果因为违反了某个网站的规定而被列入黑名单,可以通过以下几种方式解决:
1.向网站管理员提交申请并说明情况,并承诺以后遵守相关规定;
2.积极参与社区活动,并提供有价值的信息和建设性意见;
3.加强自身品牌建设和口碑管理。
第八、如何处理因违反爬虫协议而面临法律诉讼?
如果因为违反了相关法律法规而面临法律诉讼,应当积极配合调查,并寻求专业法律援助。
第九、如何保障自己在网络环境下的合法权益?
保障自己在网络环境下的合法权益需要注意以下几点:
1.了解相关法律法规及其适用范围和实施细则;
2.加强自身知识产权保护和品牌建设,并及时发现和处理侵权行为;
3.与网络服务提供商签署相关合同并明确双方权利义务。
第十、结语
网络空间是一个开放共享、互惠互利的空间,在这里我们需要相互尊重、相互信任、共同发展。作为网络从业者,在开展工作之前务必要仔细阅读相关条款并切实遵守相关规定,做到合法合规经营。只有这样才能够实现长期稳定地发展,并在竞争中获得更多机会。

