深度剖析网页源代码:十个方面的采集技巧大揭秘
优采云 发布时间: 2023-03-04 05:07随着互联网的不断发展,信息获取的方式也在不断更新升级。其中,通过网页源代码采集已成为一种备受关注的新型信息获取方式。本文将从十个方面对其进行详细分析。
一、什么是网页源代码?
网页源代码是指浏览器中查看网页时所显示的HTML源码,它包含了网页所有的元素和标签。而通过采集网页源代码,我们可以获取到更加全面、详细的信息。
二、为什么要采集网页源代码?
通过采集网页源代码,可以获取到更加全面、详细的信息,而这些信息对于企业市场调研、竞品分析等方面都有着重要的作用。同时,也可以帮助个人用户快速获取所需信息。
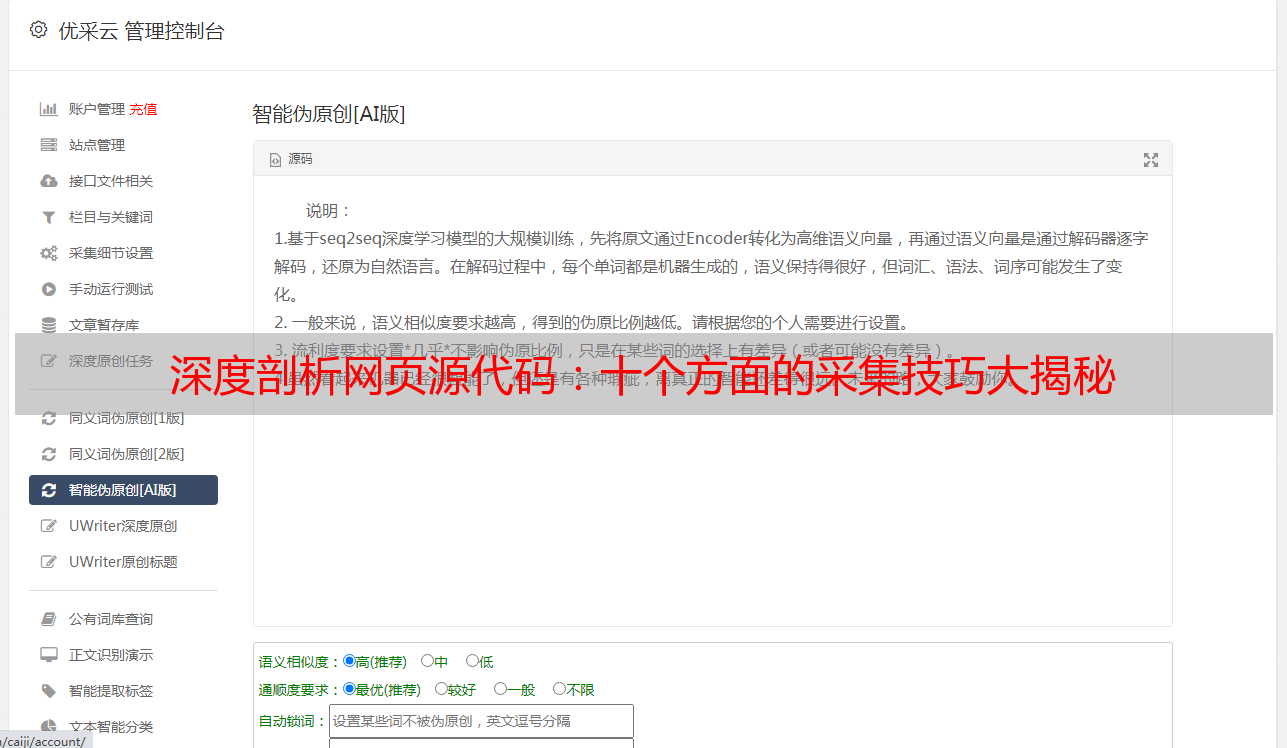
三、如何通过网页源代码采集?
通过编写爬虫程序可以实现网页源代码采集。爬虫程序可以模拟浏览器行为,访问需要采集的页面,并将其源代码保存下来。同时,还可以通过设置规则和过滤条件来筛选所需信息。
四、常用的爬虫框架有哪些?
常用的爬虫框架包括Scrapy、BeautifulSoup、Selenium等。其中Scrapy是一个高效、灵活的Python框架;BeautifulSoup是一个解析HTML和XML文档的Python库;Selenium则是一个自动化测试工具。
五、如何避免被反爬虫?
在进行网页源代码采集时,需要注意避免被反爬虫机制封禁。具体方法包括设置User-Agent头部信息、使用代理IP、降低访问频率等。
六、如何处理抓取到的数据?
在抓取到数据后,需要进行清洗和处理。具体方法包括去除HTML标签、去除重复数据、格式化数据等。
七、如何保证数据安全性?
在进行数据采集和存储时,需要注意保护用户隐私和数据安全性。具体方法包括加密传输数据、设置访问权限等。
八、法律法规对于网页源代码采集有何规定?
在进行网页源代码采集时,需要遵守相关法律法规。例如《中华人民共和国网络安全法》中规定“网络运营者应当*敏*感*词*保护用户个人信息和其他重要数据”。
九、如何应对反对声音?
由于一些人对于网页源代码采集存在质疑和反对声音,因此需要制定合理的沟通策略并积极回应相关问题。
十、未来发展趋势是什么?
随着互联网技术不断发展,未来网页源代码采集将会更加智能化和自动化,并且将会涉及更多领域和行业。

