学会Python爬虫,轻松导出网页表格!
优采云 发布时间: 2023-03-04 01:08当我们遇到一个网页表格,想要从中抓取数据时,常常会遇到一种限制:只能选择5项数据进行导出。这时候该怎么办呢?本文将为您详细介绍抓取网页表格的方法。
一、了解网页表格的结构
在进行抓取之前,我们需要先了解网页表格的结构。通常情况下,网页表格都是由HTML语言编写而成的。在HTML中,表格以table标签开始和结束,并包含多个tr标签(表示行)和td标签(表示单元格)。了解这些基本概念后,我们才能更好地理解如何抓取网页表格。
二、使用浏览器插件
为了方便抓取网页表格,我们可以使用一些浏览器插件。其中比较常用的插件是Table Capture和Web Scraper。这些插件可以帮助我们轻松地抓取整个表格,并将其保存为Excel或CSV文件。
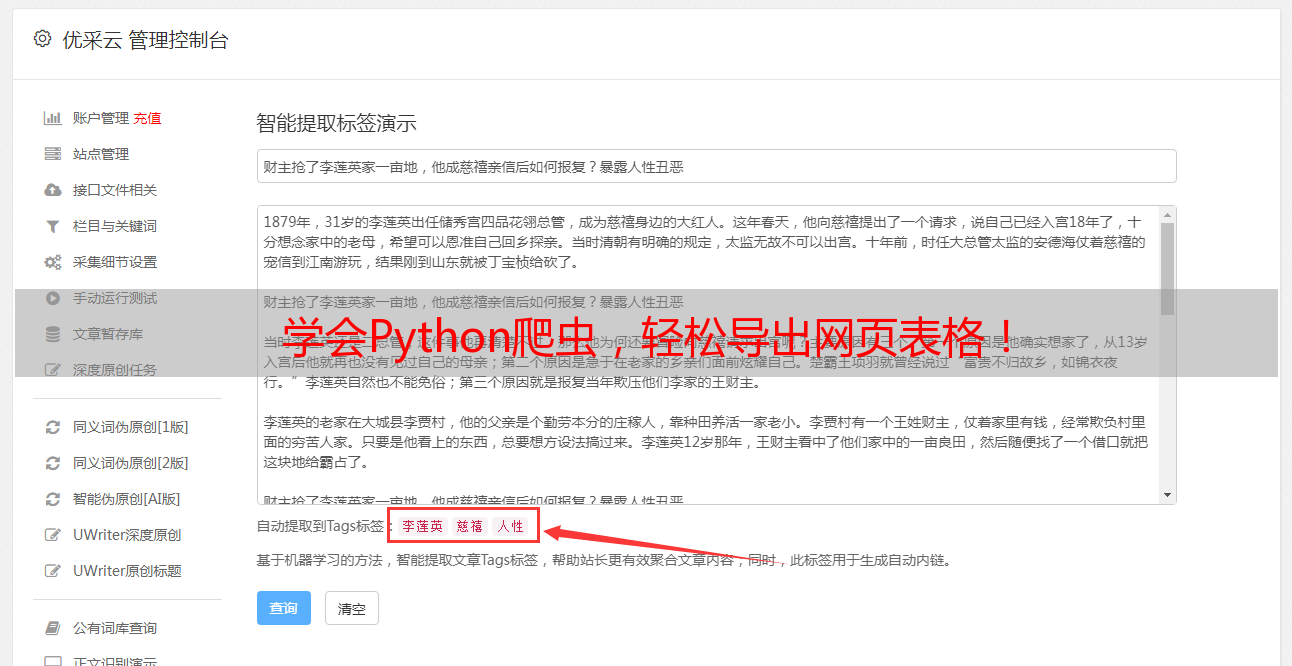
三、使用Python编写爬虫程序
如果我们需要对多个网站上的表格进行抓取,并且需要定期更新数据,那么手动复制粘贴数据显然不太现实。这时候我们可以考虑使用Python编写爬虫程序。通过分析HTML代码和CSS样式,我们可以编写出针对特定网站的爬虫程序。具体实现过程可以参考Python爬虫相关教程。
四、使用API接口
有些网站提供了API接口,允许我们通过简单的HTTP请求获取数据。如果目标网站提供了这样的接口,那么我们就可以直接调用API来获取数据,而无需进行复杂的页面解析和处理。
五、使用OCR技术
有些情况下,网页上的表格并不是真正的数字或文本格式,而是以图片形式展示。这时候我们就需要用到OCR技术(光学字符识别)。通过将图片转换为文字内容,我们就可以将表格中的数据提取出来。
六、处理JavaScript动态加载
有些网站采用JavaScript动态加载技术,在页面加载完成之前无法获取完整的数据。这时候我们需要借助一些工具来模拟浏览器行为,并等待页面加载完成后再进行数据抓取。
七、处理反爬虫机制
为了防止爬虫程序对其服务器造成负担,有些网站采用了反爬虫机制。比如设置验证码、IP封禁等措施。为了规避这些机制,我们需要采用一些技巧来隐藏自己的身份,并模拟人类操作行为。
八、处理异常情况
在进行数据抓取时,经常会遇到各种异常情况。比如网络连接超时、页面格式错误等。为了保证程序能够稳定运行,在编写代码时需要充分考虑各种异常情况,并做好相应的处理。
九、保护隐私和版权
在进行网页数据抓取时,也要注意保护隐私和版权问题。不要盗用他人信息或者商业机密,并合理使用所获得的数据。
十、总结
通过以上十个方面的讨论,相信大家已经对如何抓取网页表格有了更深入的了解。无论您是想要手动复制粘贴还是编写自动化脚本,请务必遵守相关法律法规和伦理道德标准。只有保持诚信和合法性才能让互联网更加美好!

