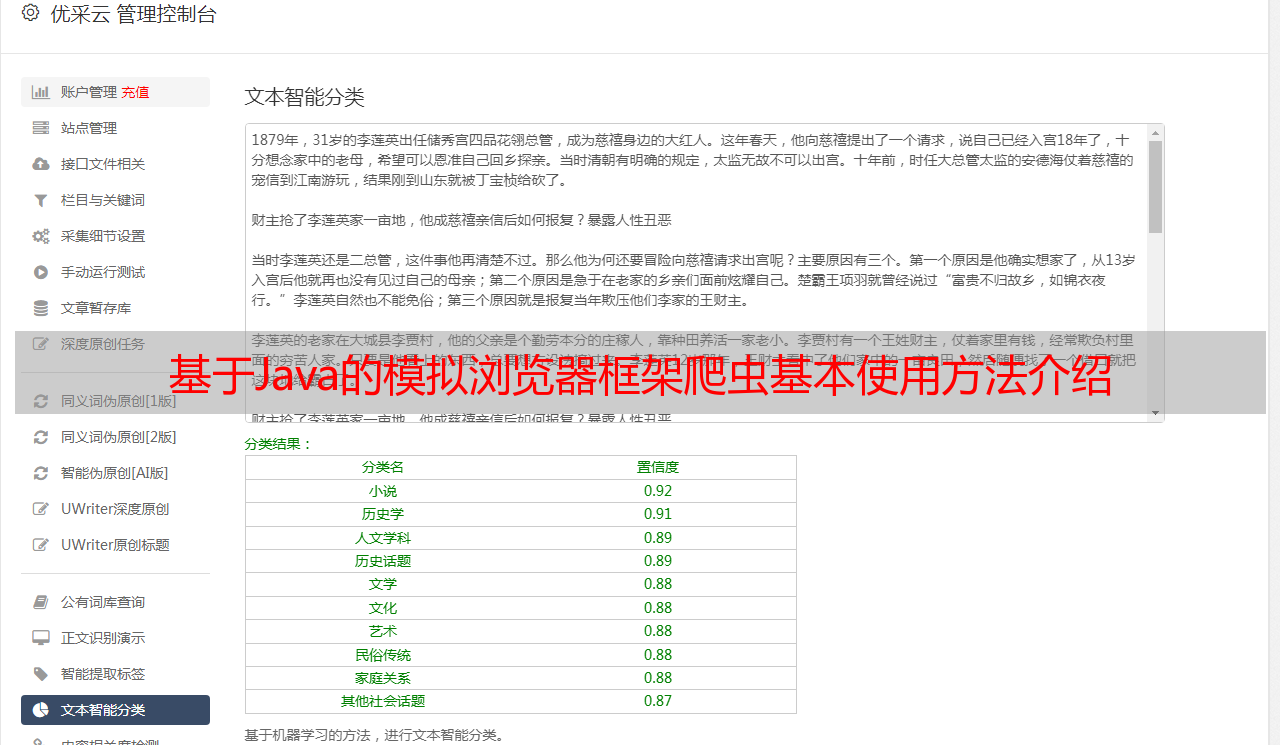
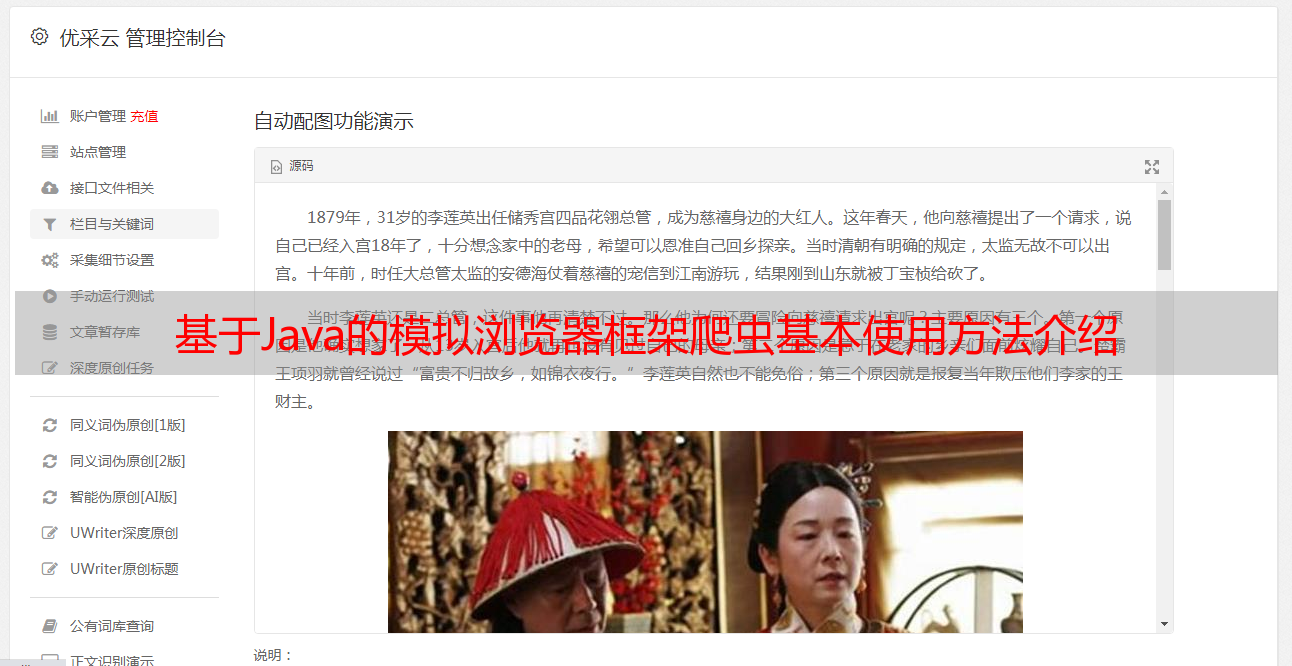
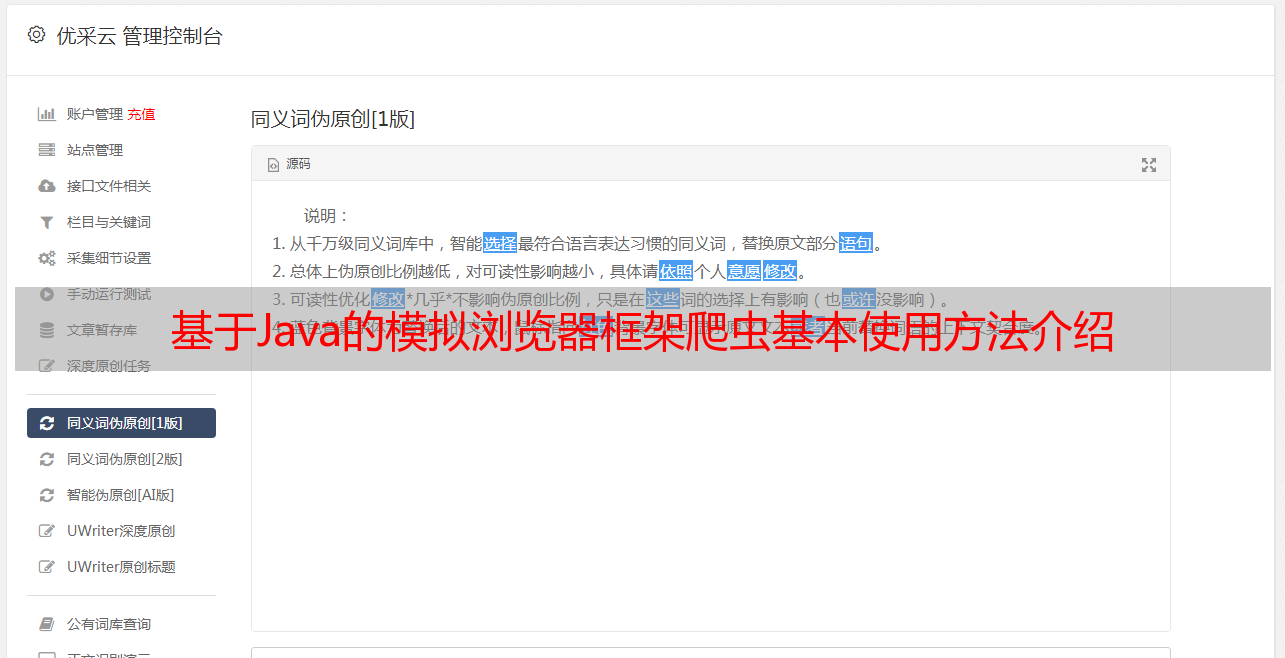
基于Java的模拟浏览器框架爬虫基本使用方法介绍
优采云 发布时间: 2023-03-03 22:11在当今信息化时代,获取各种信息已经成为人们的日常需求。而在这个过程中,爬虫技术无疑是一个非常重要的工具。而HtmlUnit作为一种基于Java的模拟浏览器框架,其强大的功能和便捷的使用方式,使得它成为了很多人心目中最好的爬虫之一。而本文将从以下十个方面详细介绍HtmlUnit爬虫如何轻松获取中文版信息。
一、HtmlUnit爬虫介绍
二、HtmlUnit爬虫原理
三、HtmlUnit爬虫安装
四、HtmlUnit爬虫基本使用方法
五、HtmlUnit爬虫进阶使用技巧
六、HtmlUnit爬虫应用案例分析
七、HtmlUnit爬虫注意事项及常见问题解决方法
八、HtmlUnit爬虫与其他爬虫工具比较
九、未来发展趋势及展望
十、总结
一、HtmlUnit爬虫介绍
HtmlUnit是一个基于Java的模拟浏览器框架,可以用来模拟浏览器访问网站,并获取网站上的各种信息。它是一个开源项目,可以自由下载和使用。由于其强大的功能和便捷的使用方式,因此被广泛应用于各种领域。
二、HtmlUnit爬虫原理
HtmlUnit实际上是一种浏览器内核模拟器,它可以模拟浏览器在访问网站时所进行的各种操作,例如点击链接、填写表单等等。通过这些操作,它可以获取到网站上的各种信息,并保存到本地文件或数据库中。
三、HtmlUnit爬虫安装
安装HtmlUnit非常简单,只需要下载最新版本的jar包,并将其添加到Java项目中即可。同时,在使用之前还需要安装一些必要的依赖库和插件,例如Apache HttpClient和JUnit等。
四、HtmlUnit爬虫基本使用方法
使用HtmlUnit进行网站抓取非常简单,只需要按照以下步骤即可:
1. 创建一个WebClient对象;
2. 设置相关参数(例如代理服务器地址等);
3. 调用WebClient对象的getPage()方法访问目标网站,并获取页面对象;
4. 使用页面对象进行相关操作(例如查找元素等);
5. 保存所需数据。
五、HtmlUnit爬虫进阶使用技巧
除了基本的使用方法外,还有很多高级技巧可以帮助我们更好地利用HtmlUnit进行数据抓取。例如:
1. 使用JavaScript引擎执行JS脚本;
2. 使用CookieManager管理Cookie;
3. 使用AjaxController处理异步请求;
4. 使用WebConnectionWrapper拦截请求并修改响应结果;
5. 使用CssErrorHandler处理CSS错误。
六、HtmlUnit爬虫应用案例分析
下面以某电商网站为例,介绍如何利用HtmlUnit进行数据抓取:
1. 首先创建一个WebClient对象,并设置相关参数(例如代理服务器地址等);
2. 调用WebClient对象的getPage()方法访问目标网站,并获取页面对象;
3. 使用页面对象查找目标元素(例如商品名称、价格等);
4. 将所需数据保存到本地文件或数据库中。
七、HtmlUnit爬虫注意事项及常见问题解决方法
在使用 HtmlUnit 进行数据抓取时需要注意以下几点:
1. 不要过于频繁地访问同一网站,否则可能会被封禁 IP 地址;
2. 对于动态生成内容的网站需要特别注意异步请求和 JavaScript 执行问题;
3. 对于反扒措施比较严格的网站需要采取相应措施(例如伪造 User-Agent 等)。
八、 HtmlUnit 爬虫与其他爬虫工具比较
与其他常见的 Python 爬虫工具相比, HtmlUnit 具有以下优点:
1. 支持 Java 编程语言,适合 Java 开发者使用;
2. 支持 JavaScript 执行和 Ajax 请求处理等高级功能。
九、未来发展趋势及展望
随着互联网技术不断发展和完善, HtmlUnit 爬虫也将不断更新迭代并加入更多新功能。同时,在大数据时代背景下,对海量数据进行快速准确地提取也将成为 HtmlUnit 爬虫发展方向之一。
十、总结
通过以上分析我们可以看出,在当前阶段 HtmlUnit 爬虫已经成为了一种非常重要和实用的网络抓取工具。而对于那些想要从海量网络数据中获取有价值信息的人们来说,则更是必备利器。

