学习使用for循环批量处理网页标题(干货)
优采云 发布时间: 2023-03-03 16:38作为一名程序员,我们经常需要从不同的网站上获取信息。而这些信息中,网页标题无疑是最基本、最重要的内容之一。那么如何使用for循环抓取多个网页标题呢?本文将详细介绍这一过程,帮助你轻松实现。
1. 获取网页链接
首先,我们需要获取要抓取的多个网页链接。可以通过爬虫程序、API接口或者手动输入等方式获取链接。这里以手动输入为例,假设我们要抓取三个网站的标题:www.baidu.com、www.sohu.com和www.qq.com。
2. 导入库文件
接下来,我们需要导入相关库文件。这里使用Python语言进行编写,所以需要导入requests和beautifulsoup4两个库文件。其中requests用于发送HTTP请求,beautifulsoup4用于解析HTML文档。
3. 编写for循环
有了链接和库文件之后,我们就可以编写for循环进行抓取了。以下是示例代码:
import requests
from bs4 import BeautifulSoup
urls = ['http://www.baidu.com', 'http://www.sohu.com', 'http://www.qq.com']
for url in urls:
r = requests.get(url)
soup = BeautifulSoup(r.content, 'html.parser')
title = soup.title.string
print(title)
在上述代码中,我们首先定义了一个列表urls,其中存放了三个要抓取的链接。然后通过for循环依次访问每个链接,并获取其响应内容。接着使用beautifulsoup4解析HTML文档,并提取其中的标题信息。最后将标题打印输出即可。
4. 处理异常情况
当然,在实际操作中可能会遇到各种异常情况,比如链接无法访问、HTML文档格式不规范等等。为了保证程序的稳定性和健壮性,在编写代码时需要考虑到这些情况,并加以处理。
5. 提高效率
如果要抓取大量的网页标题,单纯地使用for循环可能会比较慢。为了提高效率,可以考虑使用多线程或异步IO等技术。这里不再赘述,请读者自行查阅相关资料。
6. 注意事项
在进行网页抓取时,需要注意以下几点:
- 尊重网站所有者的权益和隐私;
- 遵守相关法律法规;
- 不要频繁访问同一个网站,以免给服务器造成负担;
- 不要过度依赖第三方库文件或工具。
7. 实际应用
网络爬虫技术在实际应用中有着广泛的应用场景。比如,在电商平台上搜索商品时,就是通过爬虫程序获取各家店铺的商品信息并进行展示;在媒体报道中,也常常利用网络爬虫技术收集新闻资讯等信息。
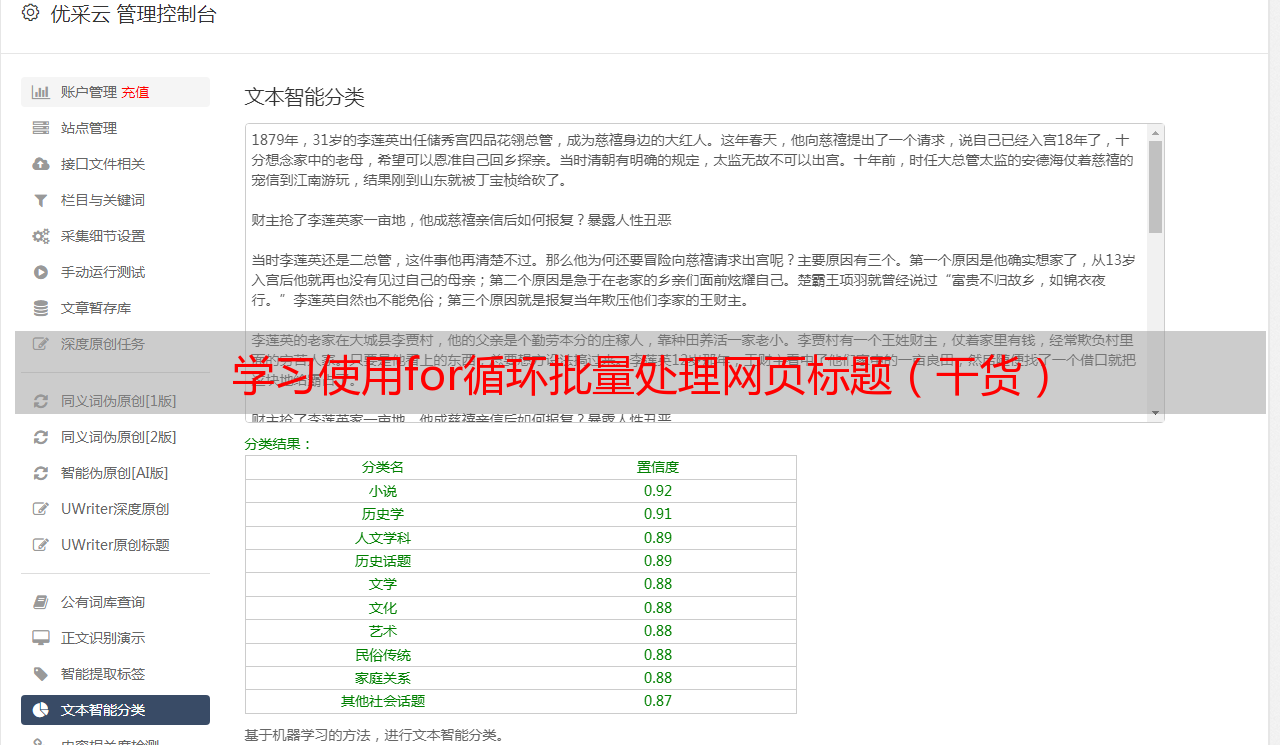
8. 总结
使用for循环抓取多个网页标题并不难,只需要掌握好相关知识点和技巧即可。同时,在实际操作中也需要注意一些细节问题,并遵守相关规定和法律法规。希望本文对大家有所帮助。

