轻松掌控网页代码:自己动手采集安装教程
优采云 发布时间: 2023-03-03 12:13随着互联网的不断发展,各种信息呈爆炸式增长,对于大量信息的处理和分析成为了亟待解决的问题。而采集网页代码则成为了一种非常有效的方式。但是,许多人对于如何采集网页代码却不是很了解,或者只知道使用别人已经开发好的软件进行采集,而缺乏自主控制和定制化的能力。本文将从7个方面详细介绍如何自己动手采集网页代码安装,并实现自主控制。
1. 什么是采集网页代码?
2. 为什么需要采集网页代码?
3. 如何安装Python环境?
4. 如何通过Python实现网页代码的采集?
5. 如何通过Python进行数据清洗和预处理?
6. 如何将采集到的数据存储到数据库中?
7. 如何进行数据分析和可视化?
1、什么是采集网页代码?
采集网页代码是指通过程序获取网页上的HTML、CSS、JavaScript等源码信息,并对其进行解析、提取所需信息。可以理解为是一种自动化地获取网站数据的方式。
2、为什么需要采集网页代码?
在日常生活中,我们需要大量的信息来支持我们做出决策。而这些信息很多时候都散布在各个网站上,如果每次需要手动去浏览每一个网站来获取所需信息,那将会非常耗费时间和精力。而利用采集技术可以快速地获取所需信息,提高效率。
3、如何安装Python环境?
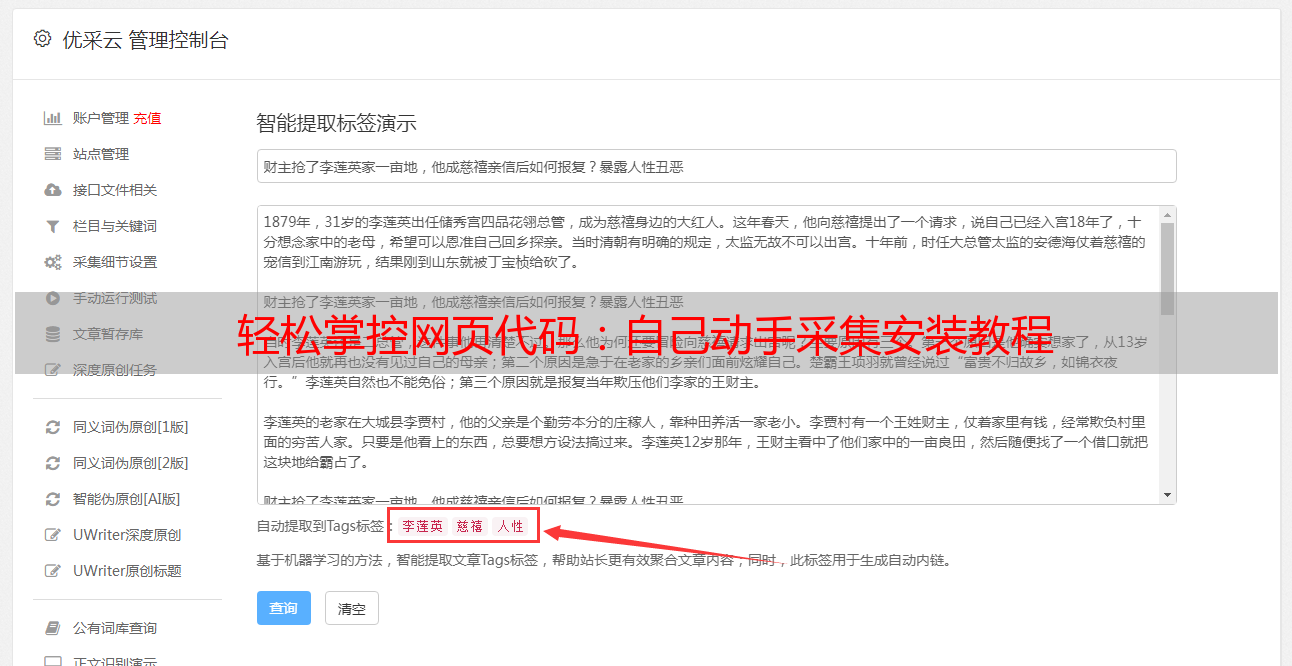
Python是一种广泛应用于科学计算、机器学习等领域的编程语言,在进行采集工作时也非常常见。因此,在开始学习如何采集网页代码之前,需要先安装并配置好Python环境。
详细论述:
1)下载并安装Python;
2)打开命令行窗口;
3)输入python -V 检查是否安装成功;
4)安装pip包管理工具;
5)使用pip install 命令安装所需依赖库(如requests、beautifulsoup4等)。
4、如何通过Python实现网页代码的采集?
在完成Python环境配置后,就可以开始学习如何使用Python实现网页代码的采集了。具体步骤如下:
详细论述:
1)导入requests库,并利用get方法获取目标页面;
2)利用beautifulsoup4库解析页面HTML源码;
3)利用选择器等方式定位目标元素;
4)提取所需信息并输出。
5、如何通过Python进行数据清洗和预处理?
在完成数据采集之后,往往需要对数据进行清洗和预处理才能更好地使用。下面是一些常见的数据清洗和预处理方法:
详细论述:
1)去除重复值;
2)去除缺失值;
3)替换异常值;
4)转换数据类型;
5)规范化数据格式。
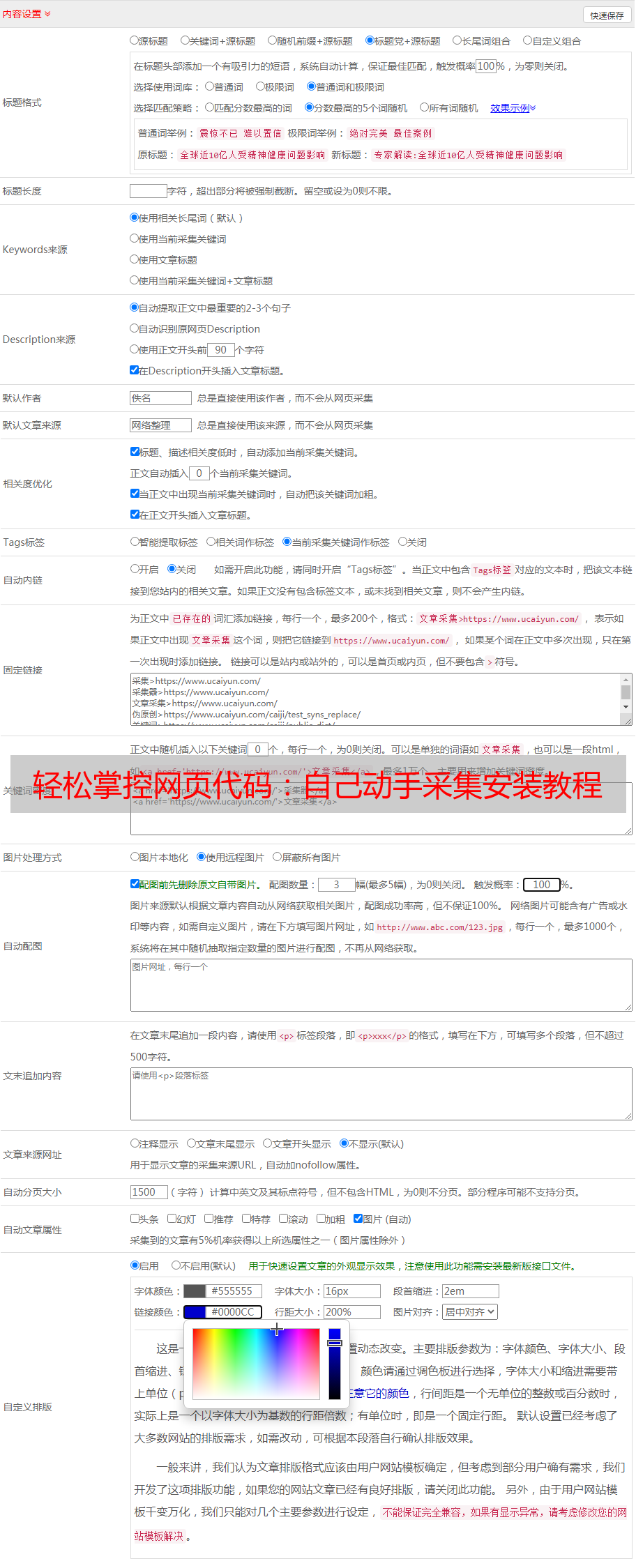
6、如何将采集到的数据存储到数据库中?
在完成数据清洗和预处理之后,通常需要将结果保存到数据库中以备后续分析使用。下面是一些常见的数据库操作方法:
详细论述:
1)连接数据库;
2)创建表格;
3)插入数据;
4)查询数据;
5)更新数据。
7、如何进行数据分析和可视化?
最后,在完成以上步骤之后,就可以开始进行数据分析和可视化了。下面是一些常见的分析和可视化方法:
详细论述:
1)利用pandas库进行统计分析;
2)利用matplotlib库进行图表绘制;
3)利用seaborn库进行更加美观的图表绘制。
总结:本文介绍了如何自己动手采集网页代码安装,并从多个方面详细阐述了相关内容。相信读者已经对于这一过程有了更深入地认识与理解。

