五种高效利用关键词爬取百度网页的方法
优采云 发布时间: 2023-03-03 11:43在当今信息时代,互联网已经成为了我们获取信息的主要途径。而百度作为国内最大的搜索引擎,自然成为了我们获取信息的重要平台。但是,百度上信息繁杂、杂乱无章,如何快速准确地找到自己需要的信息呢?这时候,按关键词爬取百度网页就成为了一种非常有效的方法。本文将从五个方面详细讨论如何按关键词爬取百度网页。
一、什么是按关键词爬取百度网页
按关键词爬取百度网页指的是通过编写程序,在百度上输入指定关键词,并获取与该关键词相关的网页链接和内容。这种方法可以快速准确地获取到与关键词相关的所有信息资源,方便用户查找所需信息。
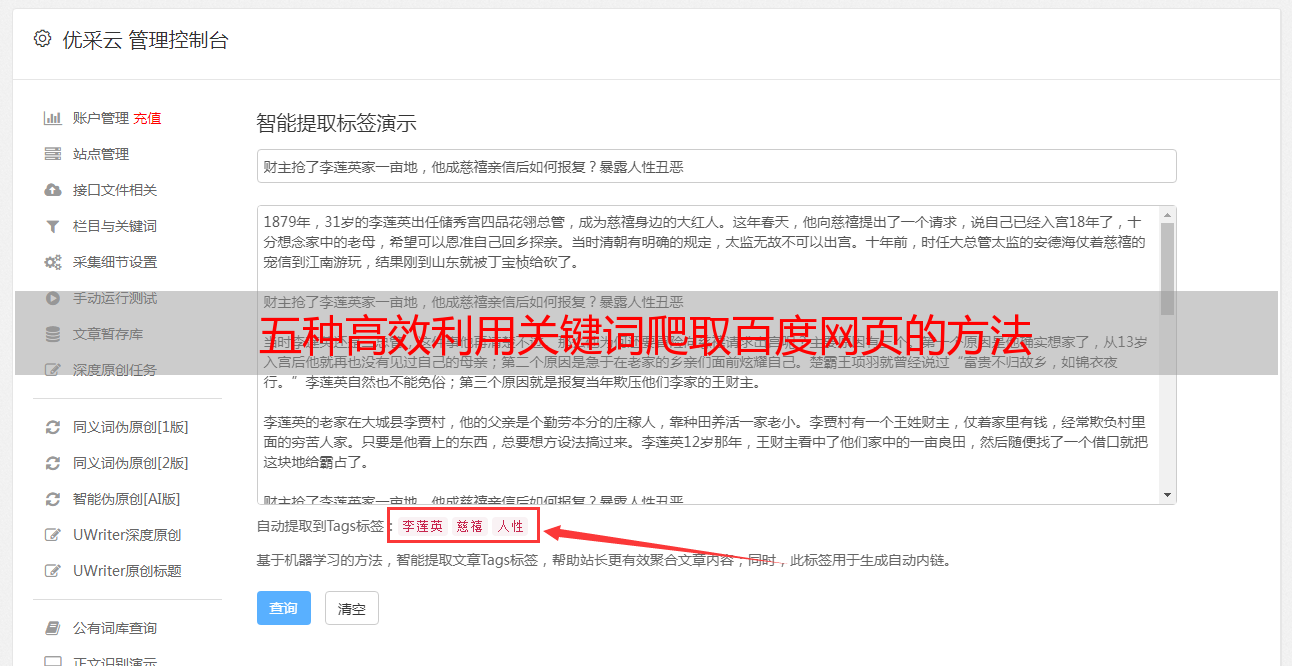
二、如何编写按关键词爬取程序
编写按关键词爬取程序需要具备一定的编程基础和网络知识。主要分为以下几个步骤:确定需要搜索的关键词;选择合适的编程语言和工具;编写程序代码;测试程序并进行优化。在编写过程中需要注意防止被反爬虫机制封禁账号等问题。
三、如何处理爬取到的数据
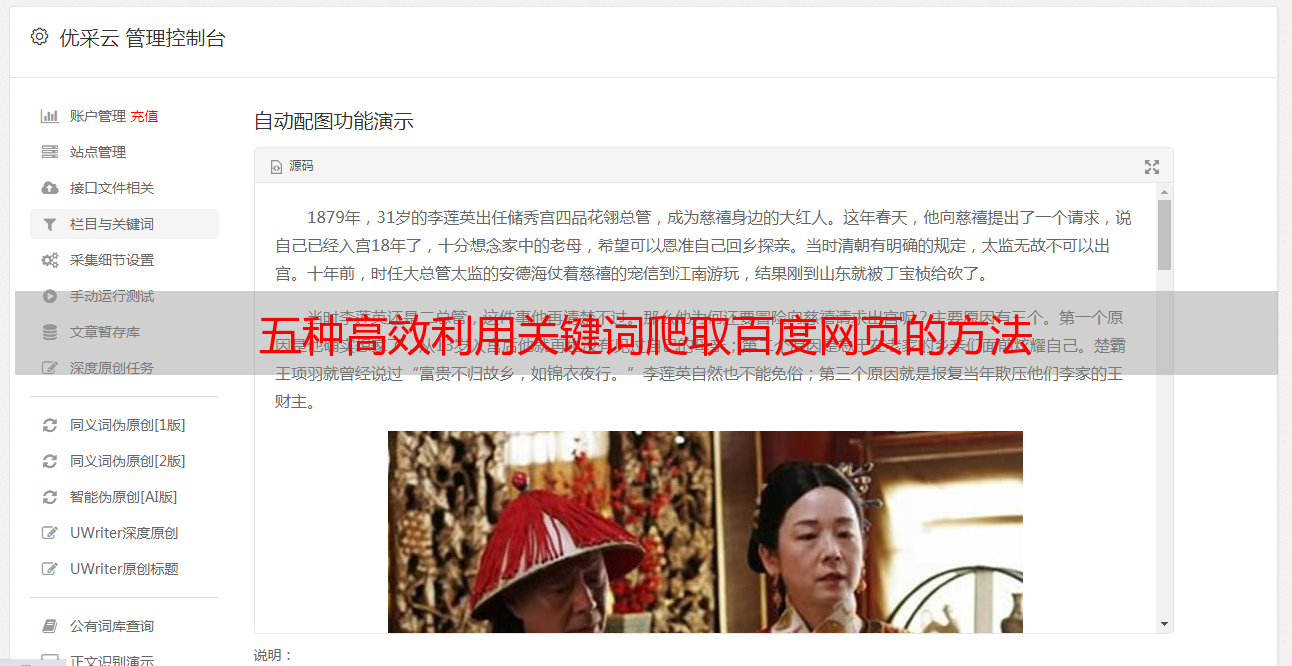
在进行网页爬取后,我们需要对获取到的数据进行处理和筛选。常用的处理方式包括:去重、过滤垃圾数据、提取有用信息等。同时,我们还可以利用机器学习等技术对数据进行分析和挖掘,以发现更多有价值的信息。
四、按关键词爬取在实际应用中的优势
按关键词爬取在实际应用中具有很多优势。首先,它能够快速准确地获取到与指定关键词相关的所有信息资源;其次,它可以根据用户需求定制搜索结果;最后,它可以帮助用户发现隐藏在海量数据背后的有价值信息。
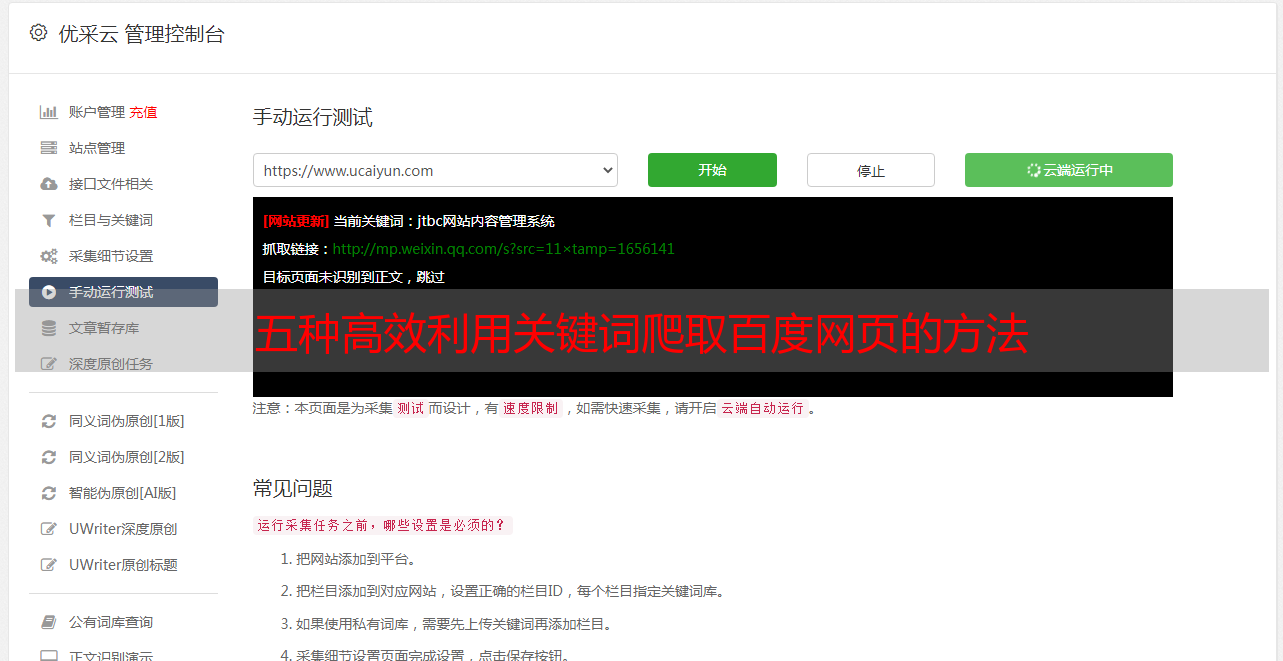
五、按关键词爬取面临的挑战及解决方案
虽然按关键词爬取具有很多优势,在实际应用中也面临着一些挑战。其中最主要的挑战就是反爬虫机制。针对这个问题,我们可以采用IP代理池、模拟浏览器等技术来规避反爬虫机制。
综上所述,按关键词爬取百度网页是一种非常有效和便捷的获取信息资源的方法。随着技术不断发展和完善,它将会在更广泛领域得到应用,并为人们带来更多便利和效益。

