深入探讨数据挖掘:数据源、采集方式、清洗技巧及价值挖掘
优采云 发布时间: 2023-03-03 11:38互联网时代,数据已经成为企业竞争的核心资源。然而,如何获取海量的、高质量的数据仍然是一个难题。网络大数据采集作为一种重要的手段,被广泛应用于市场调研、舆情监测、信息挖掘等领域。本文将从数据源、采集方式、采集工具、数据清洗和价值挖掘五个方面来介绍网络大数据采集的主要流程。
一、数据源
网络大数据来源于各类网站、社交媒体、论坛博客等互联网平台。这些平台提供了丰富的信息资源,包括文字、图片、视频等多种形式的内容。其中,社交媒体如微博、微信等成为了人们获取新闻资讯和表达观点的主要渠道之一。
1.搜索引擎
搜索引擎是网络大数据采集的主要工具之一。通过搜索引擎可以获取到各类网站上的信息,包括新闻、博客、论坛帖子等。目前市场上常用的搜索引擎包括百度、Google、搜狗等。
2.社交媒体
社交媒体是获取用户观点和行为信息的主要来源之一。如微博、微信等社交媒体平台提供了用户发布内容和互动评论的接口,可以通过API接口来获取相关信息。
3.论坛博客
论坛和博客是用户自发组织起来进行讨论和交流的平台。其中有很多专业性较强的论坛,可以获取到很多行业内部的资讯和观点。
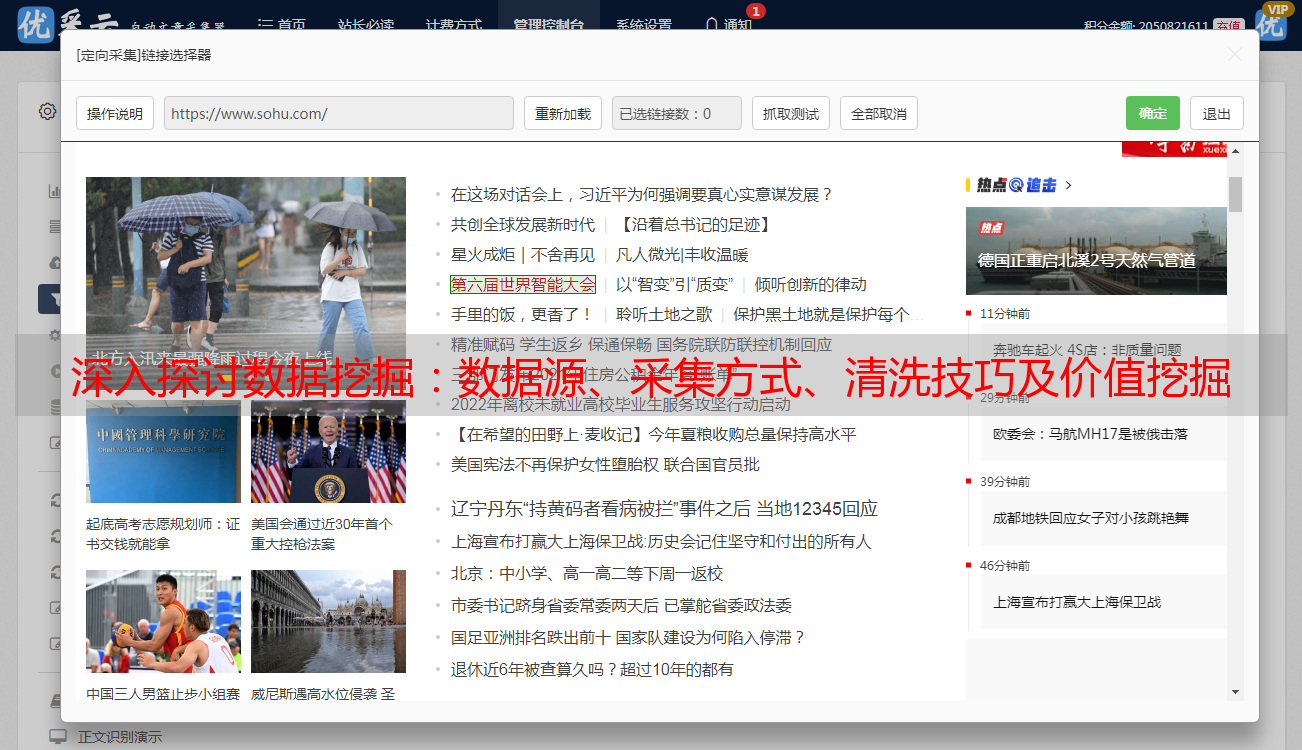
二、采集方式
网络大数据采集有多种方式,包括爬虫抓取、API接口调用等。
1.爬虫抓取
爬虫抓取是指通过程序模拟浏览器行为,在网页上模拟点击和输入操作,从而将网页上的内容抓取下来。这种方式可以获取到很多非结构化或半结构化的文本信息,并且速度较快。
2.API接口调用
API接口调用是指通过开放API接口来获取网站上特定信息。这种方式可以获取到结构化的数据,并且速度较快。但是受限于API接口开放程度和使用权限等因素,获取到的信息也有一定局限性。
三、采集工具
网络大数据采集需要借助一些专门的工具来实现自动化操作,以提高效率和减少错误率。
1.爬虫框架
爬虫框架是一种基于Python语言编写的Web爬虫框架,可以快速地开发出高效稳定的Web爬虫程序。
2.网络爬虫软件
网络爬虫软件是指那些能够模拟浏览器操作并自动抓取网页内容并存储到数据库中或输出文件中的软件工具。常见软件包括免费开源软件HTTrack以及商业软件WebHarvy等。
四、数据清洗
由于网络大数据来源广泛且形式复杂,因此在采集后需要进行清洗处理,以便更好地进行分析挖掘。
1.去重处理
由于同一个主题可能在不同平台上出现多次,在处理时需要去重处理以避免重复计算影响结果。
2.格式转换
不同来源平台上存储格式可能不同,在处理时需要将其转换为统一格式以便后续分析挖掘。
3.过滤无关信息
由于在采集过程中可能会出现无关信息或干扰信息,需要进行过滤处理以避免影响分析结果。
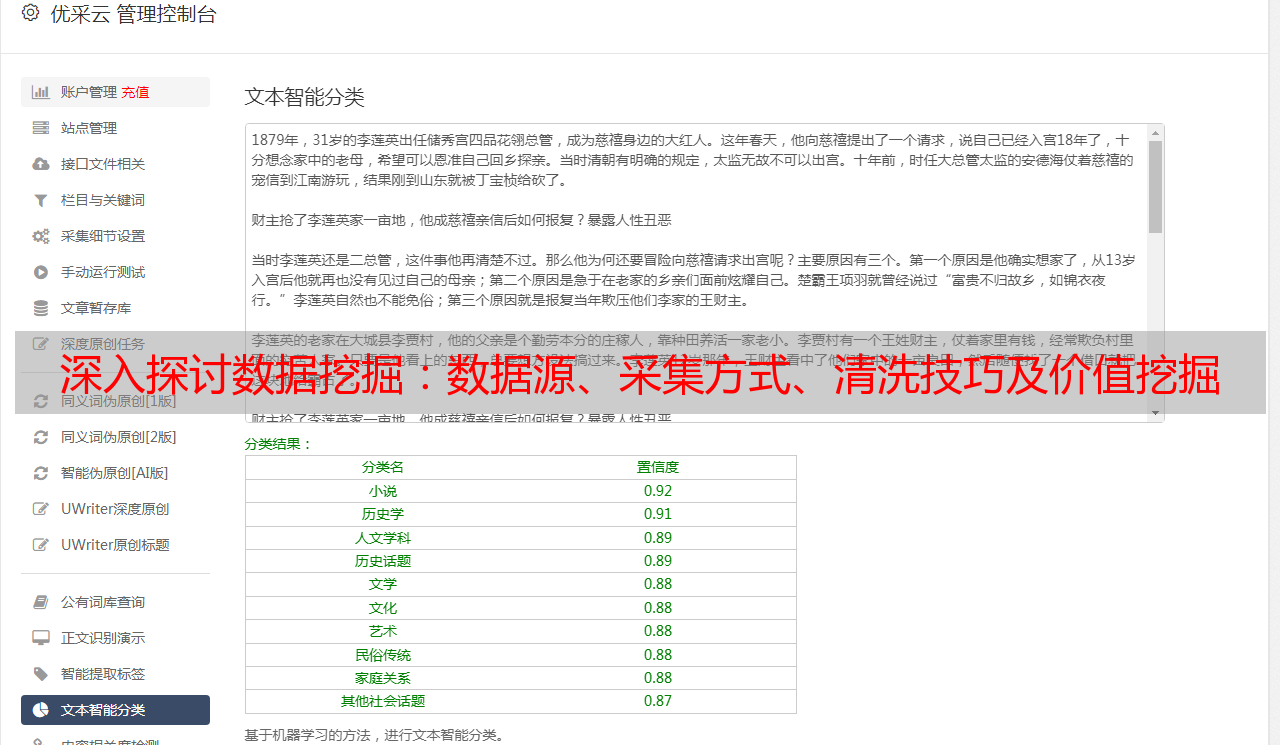
五、价值挖掘
网络大数据采集最终目标是发现其中隐藏在庞杂信息背后蕴含着什么样有意义可挖掘价值点,并将其转化为企业决策参考依据。
1.情感分析
情感分析是指对文本内容进行正负面情感判断,并提供相应得分值以便进行比较分析。情感分析可应用于舆情监测和产品评价等领域。
2.关键词提取
关键词提取是指从文本中提取出最能代表文本主题或者最能反映文本特征的词语或短语,并提供相应权重值以便进行比较分析。关键词提取可应用于主题分类和事件跟踪等领域。
3.主题分类
主题分类是指对文本内容进行分类判断,并将其归纳到相应类别中。主题分类可应用于新闻分类和产品属性分类等领域。
4.预测模型建立
预测模型建立是指基于历史数据构建预测模型,并使用该模型对未知样本进行预测判断。预测模型建立可应用于股票预测和销售预测等领域。
5.图像识别技术
图像识别技术是指基于深度学习算法对图片进行分类识别,并提供相应置信度值以便进行比较分析。图像识别技术可应用于智能安防和医学影像诊断等领域。

