掌握开源网页采集器的功能和使用方法,让你事半功倍!
优采云 发布时间: 2023-03-03 11:20在信息时代,信息获取已经成为人们日常生活中不可或缺的一部分。然而,要想从海量的网页中筛选出有价值的信息并非易事。此时,一个好用的网页采集器就显得尤为重要。开源网页采集器,作为一款免费且开源的工具软件,在信息采集方面有着很高的实用性和灵活性。本文将从6个方面详细介绍开源网页采集器的功能和使用方法。
一、功能概述
开源网页采集器是一款基于Python语言编写的爬虫程序,它可以自动化地爬取互联网上各种类型的数据,并将其保存到本地数据库或者其他数据存储介质中。它可以通过对目标网站进行模拟访问和解析HTML文档来获取所需数据,并支持多线程、分布式等高级特性。
二、支持的数据源类型
开源网页采集器支持多种类型的数据源,包括但不限于:HTML页面、RSS订阅、API接口、数据库查询等。这些数据源可以是任何互联网上公开可访问的资源,如新闻网站、社交媒体平台、在线论坛等。
三、配置方式
配置开源网页采集器非常简单,只需要根据需要设置好爬虫程序的参数即可。这些参数包括要爬取的页面URL地址、页面解析规则、数据存储方式等。用户可以根据自己的需求进行灵活配置,以达到最佳效果。
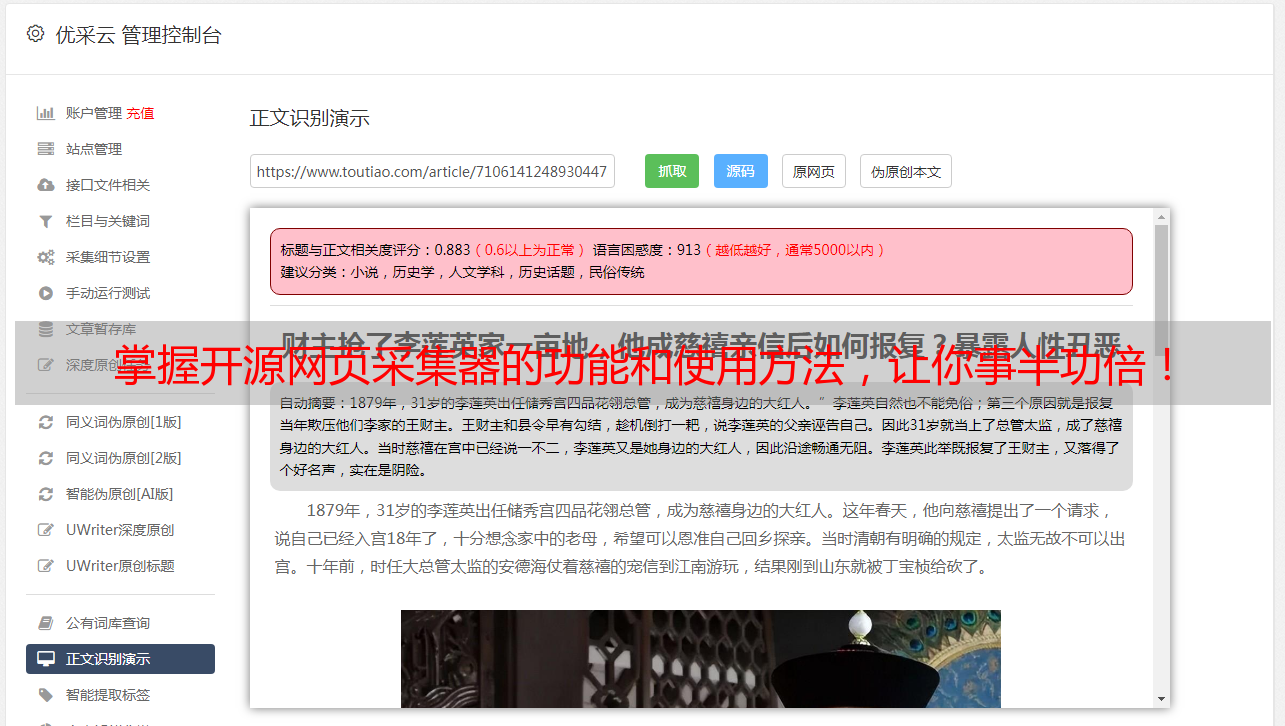
四、运行方式
开源网页采集器支持两种运行方式:命令行模式和GUI模式。命令行模式适合那些熟悉Linux命令行操作的用户,而GUI模式则提供了更加友好的图形界面操作方式。
五、优点与缺点
优点:
1. 开放源代码,免费使用;
2. 支持多种数据源类型;
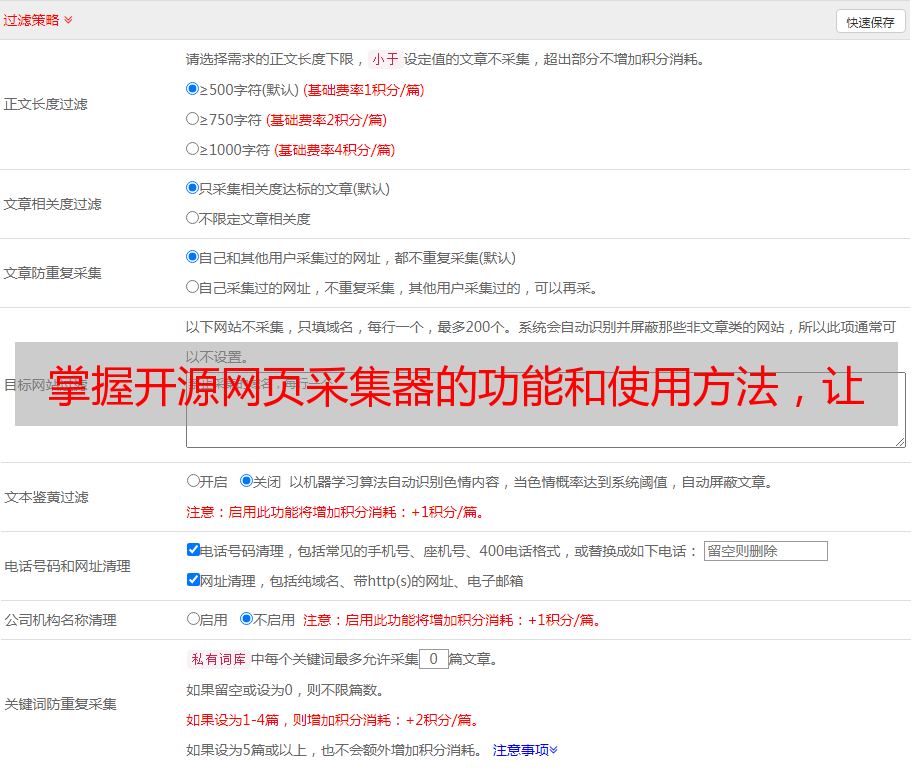
3. 支持多线程和分布式操作;
4. 灵活配置参数;
5. 可以自定义爬虫脚本;
6. 可以定时执行任务。
缺点:
1. 需要一定的编程能力;
2. 对于一些反爬虫技术可能无法有效应对;
3. 需要手动更新解析规则。
六、使用案例
以下是一个简单的使用案例:
假设我们需要从某个新闻网站上获取最新发布的10篇文章标题和链接地址,并将其保存到本地数据库中。
首先,在开源网页采集器中设置好目标URL地址和解析规则,然后启动爬虫程序即可开始抓取数据。完成后,将结果保存到数据库中即可。
总结:
开源网页采集器是一款实用性极高且灵活可扩展的工具软件,它可以帮助用户快速准确地从互联网上获取所需信息。不过,在使用过程中也需要注意一些安全问题,例如防止恶意攻击和保护隐私等。希望读者们在掌握了本文所介绍内容后,能够更加轻松地进行信息收集与处理工作。

