遵天市网页采集器(网页信息采集)v1.0.0.1绿色版
优采云 发布时间: 2020-08-07 20:04尽管Internet上有很多类似的网页采集器,但每个采集器都有其自身的优势. 在这里,我将与您分享具有完整功能和快速响应的Zuntian网页采集器. 最重要的是绿色和免费.
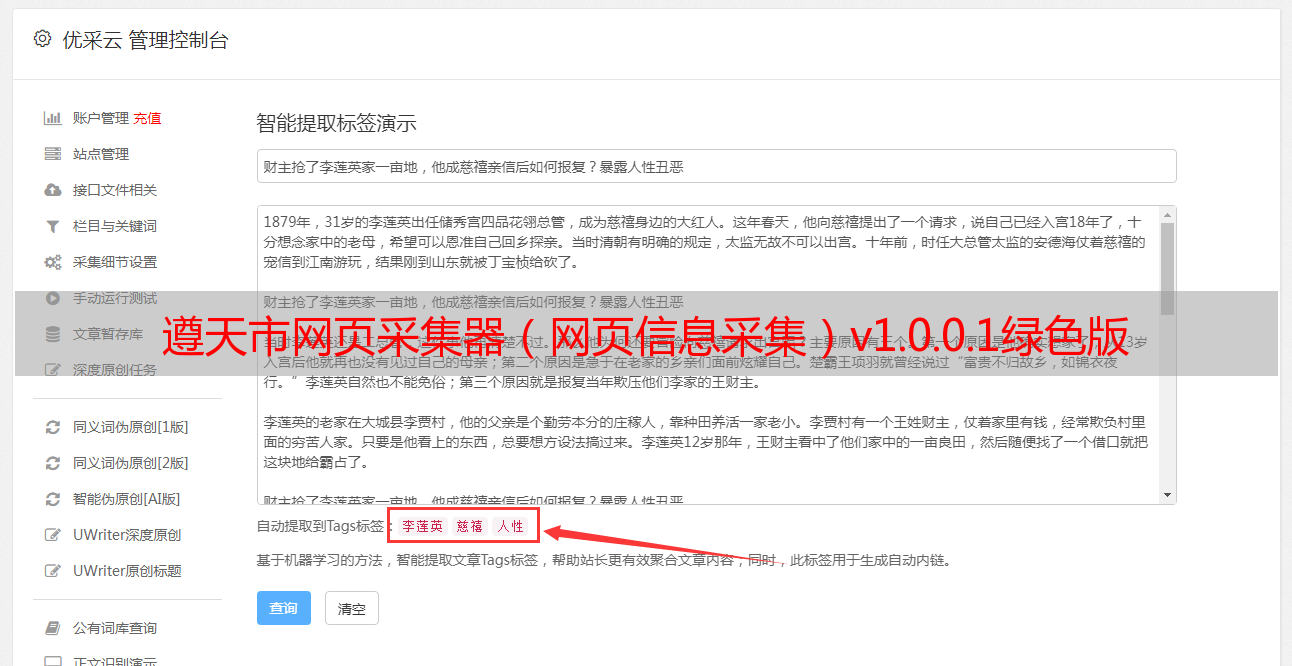
功能介绍
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
防止网页采集: 防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
使用步骤
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“查看js之后的源代码”图标,以在执行js后显示网页的内容. 如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确定是使用选项1还是使用选项2. 如果可以通过更改URL的页码来导航到下一页,请使用方案1;否则,请使用场景1. 如果您通过脚本动态更新网页的内容,请使用方案2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经具有选项1和2生成的downloadtotal.txt文件,则还可以选择选项3 . 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 单击对话框中的“取消”按钮以关闭对话框,而无需启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
注释
1. 不要在正则表达式中保留汉字,请尝试用. + ?;
替换汉字
2,时间间隔不应设置得太短,如果脚本时间太短,则可能无法执行脚本;
3,选项2如果正则表达式不匹配,则可能是由于时间间隔太短所致. 可能会增加时间间隔.
4,您可以忽略网页源代码中的换行符,采集器将忽略它.
5. 使用*表示网页URL表达式和js表达式中已更改的参数,就像上面示例中的pageid = *一样.
6. 当前,正则表达式仅支持. + ?,并且只能处理一个表达式.
7,方案1和方案2生成的downloadtotal.txt文件的第一行是. +?正则表达式中收录的信息,即采集的信息项的数量.
8. 不要在正则表达式中收录回车符和换行符.
9,如果程序提示配置不正确且无法运行,则只需下载并安装Microsoft的vcredist_x86.exe程序即可.
如何修改网页信息
如果仅更改静态页面,则可以直接打开该页面的源代码. 您可以只更改所需的文本. 如果您不了解,则可以做到.
应该为动态的后台管理. 如果涉及数据库,请用所需的内容替换要更改的部分
有关网络错误的详细信息
页面上错误的一般解决方案:
1. 点击“开始”菜单以打开“运行”.
2. 输入regsvr32 jscript.dll,然后选择“确定”. 出现提示时,单击“确定”.
3. 再次输入regsvr32 vbscript.dll,然后选择“确定”. 再次提示时,确认.
4. 在上述两个成功提示之后,这表示IE组件已成功修复,清除了浏览器的cookie和缓存,打开IE浏览器-上部工具-> Internet选项->删除cookie,然后删除临时文件.
安美旗网页采集器V2.0绿色中文版
类型: 网络相关大小: 123KB语言: 中文时间: 4-16评分: 5.0
PC正式版
Android官方移动版
IOS官方移动版

