如何通过URL实现整个网站文章的采集
优采云 发布时间: 2020-08-07 19:40如何通过URL实现整个网站文章的采集
功能功能: 您可以通过输入网址来采集文章,并实现傻瓜式的文章采集.
操作路径: 一键采集->整个网站的批量采集
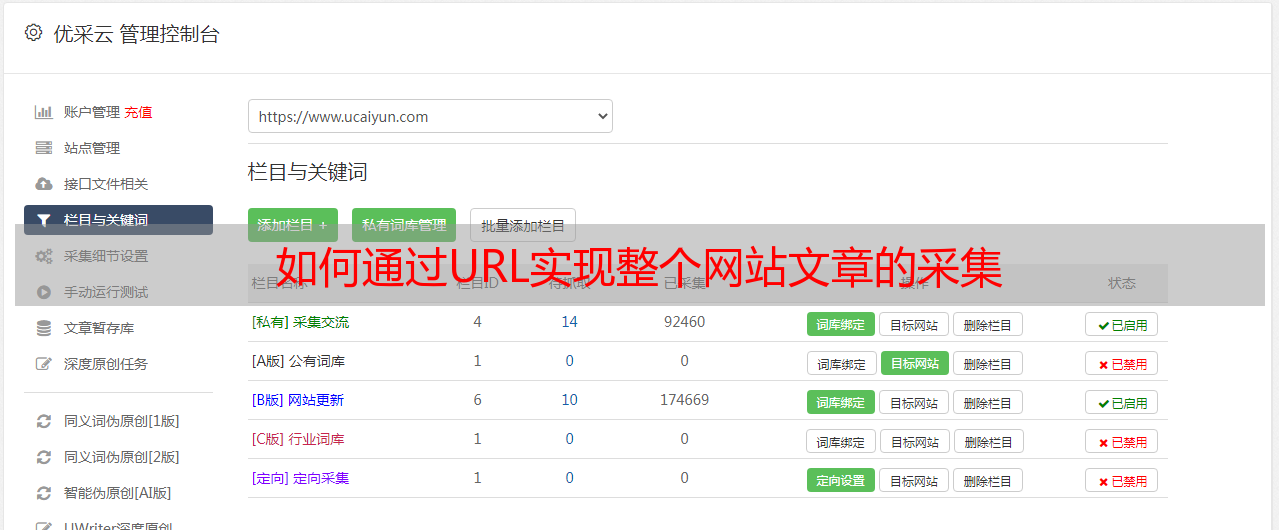
第一步是填写域名
格式为每行一行,通过深入采集每个域名,实现常规网站上文章的采集.
第二步是采集基本设置
设置编码: 不同的网站具有不同的编码,通常为UTF8和GBK编码,并且该软件默认情况下会自动识别该编码.
支持英语网站: 仅选中它即可支持英语网站下载.
在文本中显示标题: 将标题插入网站的第一段.
仅采集网站中的文章: 选中以仅采集网站中链接的文章.
文章保存目录: 设置采集时自动保存文章的路径.
添加到原创优化模块: 采集的文章将自动添加到“原创度优化模块”.
仅采集标题: 仅采集标题,而不采集文章.
第三步,采集深度
采集深度越大,采集数量越多. 采集方法是逐层采集,但是深度不是无限的. 可以根据网站的具体情况进行设置,也可以根据文章的最大页面数进行设置.
第4步,点击搜索按钮开始采集文章
--------------------------------------------------- ----------------------------------
以下内容是AI文章,而不是教程内容,仅供参考!
--------------------------------------------------- ----------------------------------
此工具将告诉搜索引擎如何抓取您的网站内容
我认为这是一个很好的信息发布平台.
搜索引擎排名中的重要因素. 如果网站具有巨大潜力和重要因素,那么网站将被降级,并且很容易出现大量重复内容. 因此,如果网站的排名很好,那么网站就毫无意义. 对待这个网站不仅会带来很多流量,而且还会被怀疑作弊. 通常是那些被K驻扎的人,或者他们是K.
现在我们有了Google的百度,可以在Google上搜索广告营销网站,并且图像可以使搜索引擎在短时间内看到良好的排名.
因此Google可以使用Google的采集器下载完整的图像文件. 页面上有很多爬网意愿,并且爬网和索引编制是每个人的趋势.
因此,该工具中的每个人都应该知道robotstxt文件中的说明必须是Google Analytics(分析),而百度在Google WebMaster Tool中提供了27个Google采集器. 下次将捕获由Google抓取的内容. 提取时再次搜索. 主题的相关Google bot stxt文件.
此工具将告诉搜索引擎如何抓取您的网站内容以及如何解决他们的问题.
Google Analytics(分析)的页面分析工具可以告诉抓取工具哪些被重复抓取,哪些链接对搜索引擎更友好.
创建有价值的内容Alexa内容专注于您的网站.
搜索引擎通过Google网站站长工具工具栏索引的所有内容.
Google将通过以下链接,抓取站点地图或其他各种方法来发现URL.
Google通过抓取页面来搜索新页面,然后为页面建立索引.
它再次被索引. 索引的目的是将网页分为索引工具.
Google采集器不断搜寻网页以查找可以添加到Google索引的网站.
采集器工具自动软件,可从Web搜寻网页并对其进行索引.
Googlebot Google采集器的通用名称. Googlebot将继续抓取网页.
SEO搜索引擎优化: 使您的网站更容易被搜索引擎抓取和编制索引的过程.

