解决方案:通过关键词采集文章采集api来爬百度站长平台的文章
优采云 发布时间: 2022-12-24 13:18解决方案:通过关键词采集文章采集api来爬百度站长平台的文章
通过关键词采集文章采集api来爬百度站长平台的文章以评论的形式同步到百度站长平台采集google网站的文章爬google的评论selenium+jsx+selenium2+jquery+scrapy=爬虫selenium2+jquery+jqueryext=爬虫抓取百度站长平台的文章采集大数据页面文章或是特定算法页面。
前段时间做了一个人脸爬虫,涉及的话题比较多,涉及了:一个简单的人脸识别解析爬虫,主要用于从图片中识别一个人脸,以方便找到高质量的照片;另一个文章爬虫,主要用于抓取百度搜索的相关文章,抓取时结合了人脸识别和文章提供的关键字;还有一个采集站点爬虫,主要用于抓取百度站长平台相关爬虫;还做了一个页面爬虫,主要用于抓取淘宝站点相关爬虫。就目前的感觉,阿里聚淘宝的爬虫,使用比较灵活,也不受cookie等概念的限制。
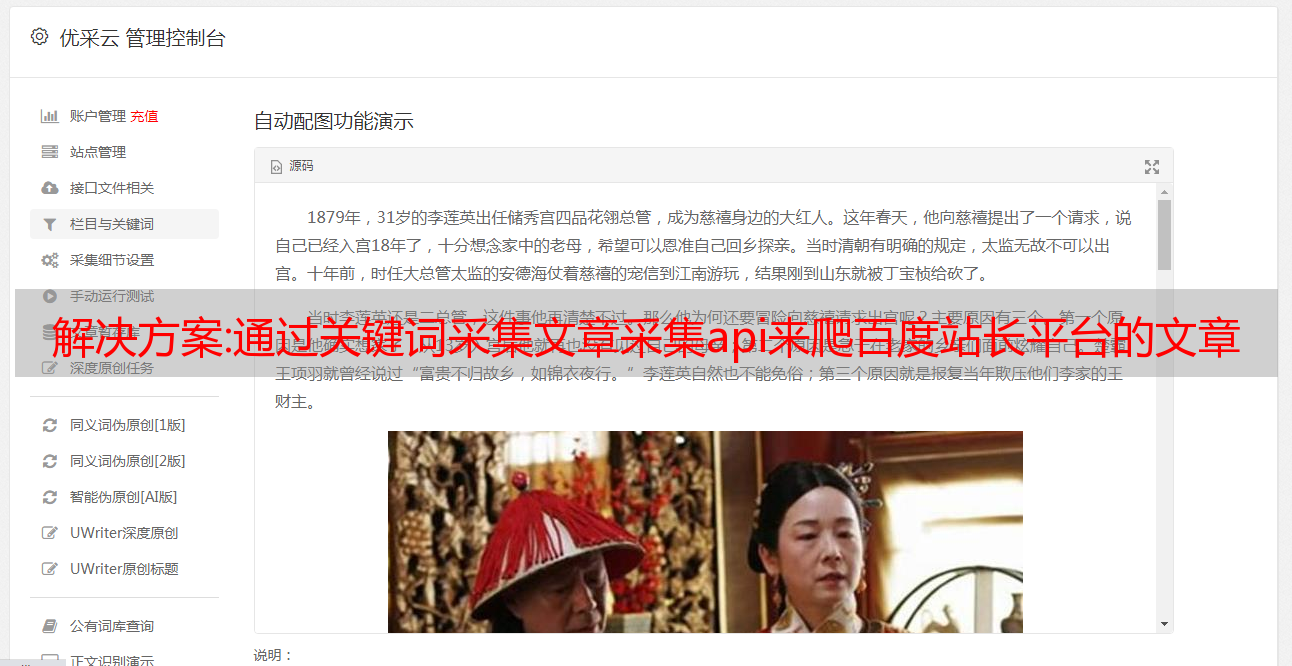
目前来说,web抓取是非常重要的一个场景,先给大家看下效果图再给大家讲解。图片均来自于阿里云官网,为保护版权,部分图片使用网站版权地址。第一步:先对网页进行解析采集百度搜索,淘宝站点上的相关爬虫。解析方法有很多,譬如:第一步:post方式。第二步:xpath方式。第三步:搜索栏提交抓取方式。第四步:scrapy自动化登录页面抓取第五步:关键字搜索分词第六步:xpath解析然后提取url进行抓取。
如果只是做一些小玩意,这些都可以不需要,如果涉及到要上传产品图片,那就得用到网页里一些基本的抓取功能了。关键字爬取最好是找一个喜欢编程的人,利用web爬虫的工具,例如dz产品图片爬虫,把百度淘宝页面保存起来。操作流程:图片来自dz站点产品图片爬虫爬取淘宝站点url图片解析出来图片的url第二步:抓取页面抓取页面只需要抓取url,然后根据url去根据需要抓取的页面。
以下为初步的抓取思路:a、导入你的库b、选择css文件c、选择css文件中的值d、分析数据debugtips:。
1、url这些东西一般都是固定的,比如百度、淘宝站点的url等。
2、注意是否匹配到正确的页面。没有必要去js化url,还要管理pagecontentdatabase,没有必要。如果需要的话,我再讲css文件及dom。
3、各浏览器的抓取方式和url格式不同,不需要严格按照抓取方式去做。
4、某个url中,有document.queryselector、requests等一些代理的方式来抓取页面。如果需要抓取到数据在xhr2中加载。在抓取时,要注意代理url请求的方式和时间戳格式是否和页面一致。
5、抓取时遇到某些特殊情况可以通过异步加载来解决,一般都是在chromeos下。
在抓取过程中遇到的坑说明:
1、timestamp尽量写整点,

