分享文章:霏霏伪原创文章*敏*感*词*
优采云 发布时间: 2022-12-24 08:54分享文章:霏霏伪原创文章*敏*感*词*
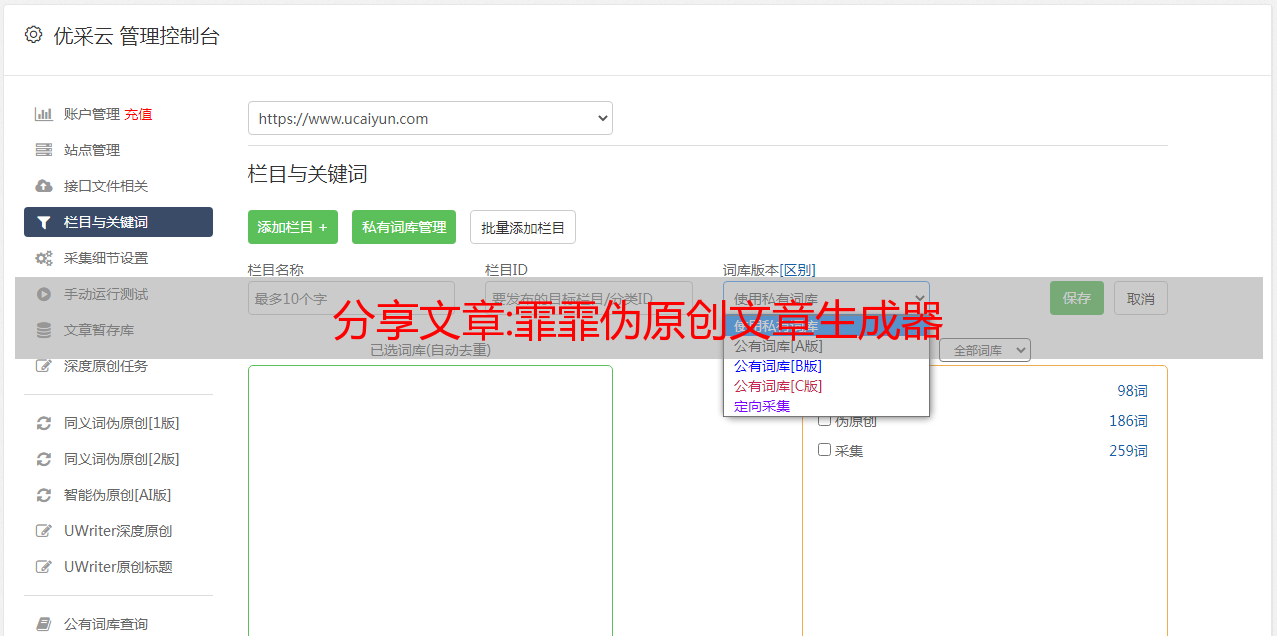
软件介绍
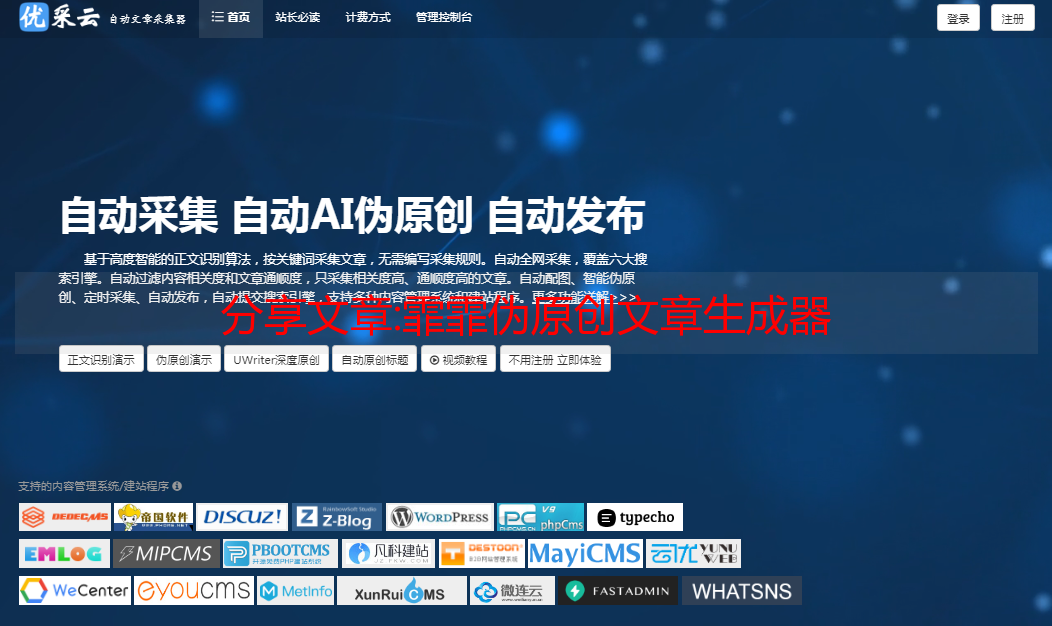
飞飞分类文章原创工具是一款seoer实用工具,是一款原创和伪原创文章生成工具。 借助伪原创工具,可以将网上复制的文章瞬间转化为原创文章。 本软件是一款专业的伪原创工具,专为谷歌、百度、雅虎、ask等大型搜索引擎设计,使用伪原创软件生成的文章会更好的被搜索引擎收录和收录。 这款伪原创软件是网络编辑、群用户、seoer的利器,也是网站优化工具中不可多得的利器。
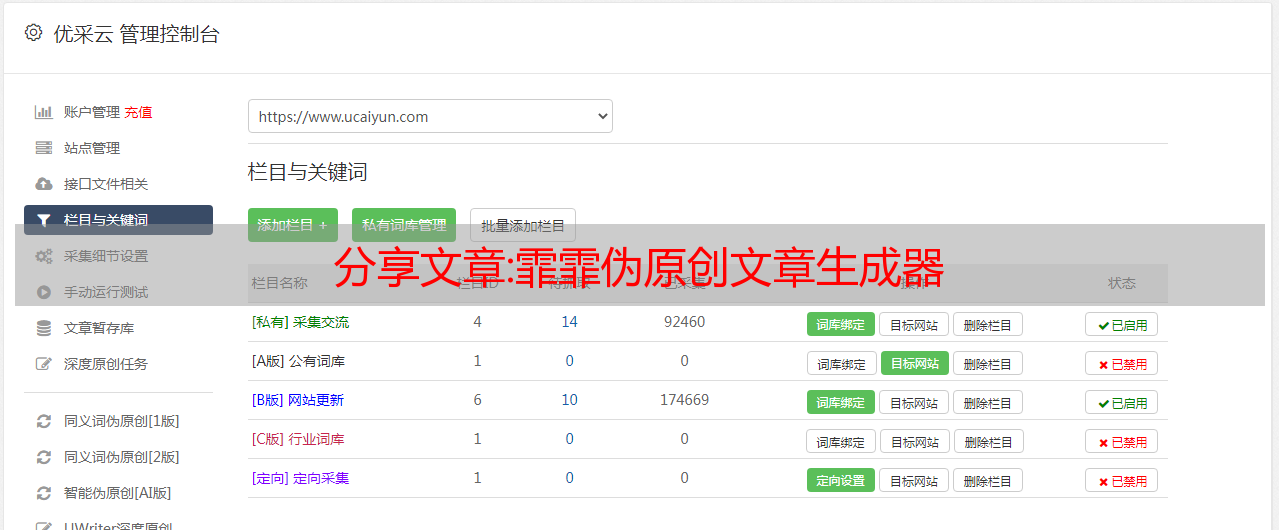
市面上没有的同类伪处理软件,最大优势:瞬间生成数万篇原创文章,也适用于英日法等多国语言的伪处理。
干货教程:Python实现批量采集美女视*频 <无水印>
前言
大家早安,午安,晚安❤~
我为您准备了一些资料,包括:
2022最新Python视频教程,Python电子书10G
(涵盖基础、爬虫、数据分析、Web开发、机器学习、人工智能、面试题)、Python学习路线图等。
文末名片领取即可!
环境使用: 模块使用:
卸载模块:pip uninstall selenium 卸载模块
安装python第三方模块:
win + R,输入cmd点击确定,输入安装命令pip install module name(pip install requests)回车
在pycharm中点击Terminal(终端)输入安装命令
基本思路: 1. 数据源分析:
明确要求:
通过浏览器内置工具:开发者工具、抓包分析
2.代码实现步骤:
发送请求,模拟浏览器发送请求url地址
获取数据,获取服务器返回响应数据
开发人员工具:响应
解析数据,提取出我们想要的数据内容
保存数据,将视频内容保存到本地文件夹
代码显示
导入模块
导入数据请求模块
import requests
# 导入正则表达式
import re
# 导入json模块
import json
# 导入格式化输出模块
from pprint import pprint
# 导入自动化测试模块
from selenium import webdriver
<p>
# 导入时间模块
import time
</p>
创建一个浏览器对象,并实例化该对象以自动打开浏览器
driver = webdriver.Chrome()
访问网址
"""执行页面滚动的动作"""
def drop_down():
for x in range(1, 40, 4): # 1 3 5 7 9 在你不断的下拉过程中, 页面高度也会变的
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js)
可以直接定位元素提取内容
lis = driver.find_elements_by_css_selector('.Eie04v01')
for li in lis:
url = li.find_element_by_css_selector('a').get_attribute('href')
发送请求,模拟浏览器发送请求url地址
print(url)
time.sleep(1)
确定请求链接
模拟迷彩
headers = {
# user-agent 用户代理 表示浏览器基本身份信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
发送请求
response = requests.get(url=url, headers=headers)
获取数据,获取服务器返回响应数据
开发人员工具:响应
解析数据,提取出我们想要的数据内容
正则表达式,你要获取什么数据,直接复制过来,然后用(.*?)表示你要的数据内容,直接返回对应的内容
.*? 表示可以匹配任何字符串,除了\n换行符
提取标题
title = re.findall('(.*?)', response.text, re.S)[0]
替换特殊字符
title = re.sub(r'[\/:*?"|\n]', '', title)
提取视频信息
<p> video_info = re.findall('(.*?)

