最新版本:网页数据全自动采集,wps怎么自动采集网站上的数据
优采云 发布时间: 2022-12-24 08:43最新版本:网页数据全自动采集,wps怎么自动采集网站上的数据
看完文章,你要知道文章讲的是什么,有多少段,按照哪些段落划分的。 这一步的重点之一就是按照步骤来。 所谓“循序渐进”,就是制定合理的计划,按章推进。 这个时候校对主要是看有没有错别字,有没有错误的句子,或者是一些错误的方法和观点。 这是SEO最重要的部分。 网站结构符合搜索引擎的爬虫偏好,有利于SEO。 这也是友谊链接活动开始的时候。 为了更好的实现与搜索引擎的对话,推荐使用数据采集站长工具。 页外搜索引擎优化通常处理网站的权威和知名度。 这些因素通常是数据采集无法直接影响或控制的因素。 今天关于数据采集的讲解就到这里,下一期分享更多SEO相关的知识和经验,我们下期再见。
如何使用Excel采集网页数据
有才优采云采集采集器配置采集任务,然后可以关闭。 这些任务可以在云端执行。 大量企业云可以24*7不间断运行。 即使被打断,也能瞬间采集大量数据。
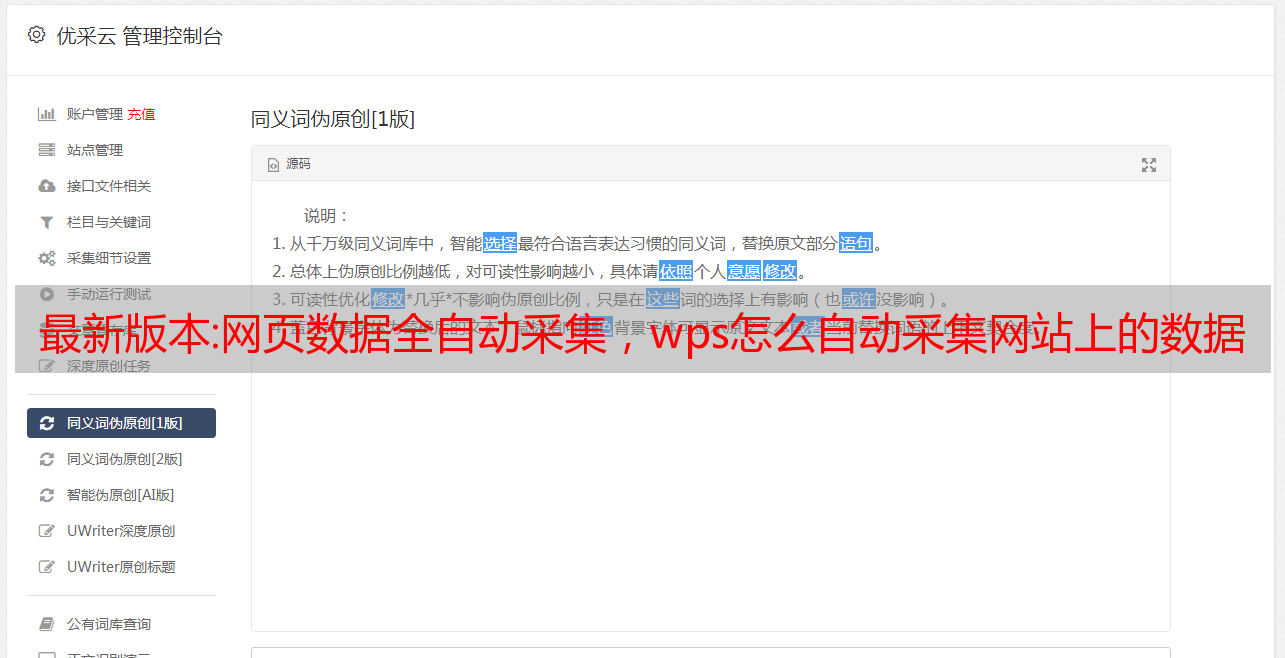
数据采集。 最近有很多站长问我有没有什么好用的数据采集软件。 每天手动更新网站太费时间了。 可同时批量管理不同的CMS网站,批量采集伪原创并批量发布,并可自动一键推送至搜狗、百度、神马、360,对网站SEO优化非常重要网站收录和排名。 谈谈数据采集。 【详情见图片】
数据采集可以批量伪原创采集文章。 资料采集要做的不是“抄袭作者的文章”,而是“换种方式解读作者的话”。 理解文章的内容和结构。 看完文章,你要知道文章讲的是什么,有多少段,按照哪些段落划分的。 【详情见图片】
采集采集伪原创发表的文章,知道了原文的排版,就可以开始写作了。 这一步的重点之一就是按照步骤来。 所谓“循序渐进”,就是制定合理的计划,按章推进。
这个阶段很微妙:你刚刚看完伪原创,对原文还有很深的印象,只是现在比较放松。 修改后的文章可以快速浏览。 这个时候校对主要是看有没有错别字,有没有错误的句子,或者是一些错误的方法和观点。 【详情见图片】
具体来说,数据采集的内容,“打磨”可以分为三种。 一是润色文字,比如适当加一些介词,打通关键环节,减少原文的生硬; 二是润色文体,换上更适合自己文体的词句。 当然,前提是要保证意思不偏离; 网站文章自动采集的,用什么软件发帖?
另外就是润色文章的意思。 比如像“长尾关键词”这样的词可以直接改写成“蓝海关键词”之类的,让别人觉得你比原作者更专业。
这是SEO最重要的部分。 关键词分析包括:关键词关注度分析、竞争对手分析、关键词-网站相关性分析、关键词布局和关键词排名预测。
网站结构符合搜索引擎的爬虫偏好,有利于SEO。 网站架构分析包括:剔除糟糕的网站架构设计,实现树形目录结构、网站导航、链接优化。
采集资料,做SEO,不仅仅是为了让网站首页在搜索引擎中排名靠前,更重要的是让网站的每一页都带来流量。 【详情见图片】
搜索引擎喜欢定期更新网站内容,因此采集资料并合理安排网站内容发布时间表是SEO的重要技能之一。 该布局将整个网站有机地链接在一起,让搜索引擎了解每个网页的重要性和关键词。 实现参考是第一点的关键词布局。 这也是友谊链接活动开始的时候。
数据采集可以与搜索引擎对话。 看搜索引擎SEO的效果,通过站点:你的域名了解站点的收录和更新。 为了更好的实现与搜索引擎的对话,推荐使用数据采集站长工具。
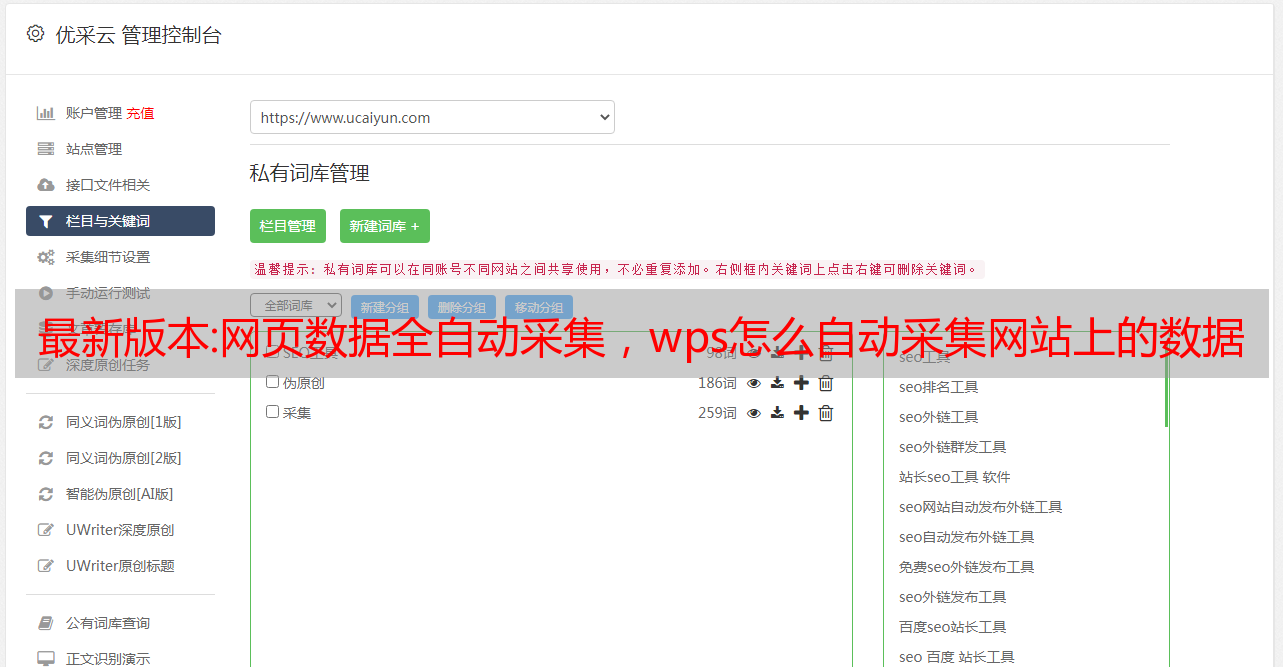
数据采集可以从SEO结果对网站流量分析指导下一步SEO策略,对网站用户体验的优化也有指导意义。 【详情见图片】
为了使新网站能够被成功抓取和收录,百度资源平台提供了自动提交链接的代码。 将相关代码放在网站中即可,非常方便,对于后续的优化工作也很重要。
页外搜索引擎优化通常处理网站的权威和知名度。 这些因素通常是数据采集无法直接影响或控制的因素。
另一方面,数据采集,正如我们刚刚了解到的,您可以控制和影响驻留在您的网页或网站上的页面 SEO 因素。
站外 SEO 最重要的方面是采集。 要了解有关数据采集、数据采集类型的更多信息。 今天关于数据采集的讲解就到这里,下一期分享更多SEO相关的知识和经验,我们下期再见。
Excel采集互联网信息 用EXCEL采集网页信息并不难。 需要启用宏功能,用VBA编写采集代码,将信息采集到表单中。
首先,舆情系统类似于Doric的舆情数据分析站系统,可以自动采集任意网站的数据。 如果你想要全网的数据,可以直接使用这个舆情系统,也可以针对单个网站进行定制。
最新版本:【开源】类似百度文库的文库网站系统
最近看到一个类似百度文库的开源图书馆系统。 它可用于建立和运营您自己的图书馆网站。
虽然像百度图书馆这样的综合性图书馆站点已经建成,但是如果打算建设一个综合性的图书馆站点,还是不太现实,因为空间太小了。
但是,如果专注于某个方向的库站,比如课后习题答案库站、IT行业库站、教育库站等,如果专注于一个行业领域,还是有很大空间的为了成长。 就像图片网站一样,现在很多搜索引擎都可以搜索图片,但是Pinterest、花瓣网等还没开始做吗?
主要技术栈
后端:Go语言框架Beego
前端:Flat-UI,基于Bootstrap的前端框架
数据库:MySQL,数据存储
依赖环境:Libreoffice(或Openoffice),用于office文档转PDF
pdf2svg,用于将PDF转换成svg矢量图供阅读。
Calibre,用于将mobi、chm、epub等文档转成PDF,然后将pdf转成svg
阿里云OSS,存放office文档、PDF文档和svg文件
功能特性文档在线阅读
DocHub库通过svg矢量图形实现文档阅读体验。 在我知道的图书馆网站中,新浪爱文通过png等图片提供文档阅读体验。
与png、jpeg等图像格式相比,SVG有很大的优势。 至少在放大的时候不会变形。 svg相对于JPEG和GIF图片,体积更小,压缩性更好。 DocHub 通过 gzip 压缩 svg 文件。 在正常情况下,它可以将文件大小减少 70%。 例如,一个 200kb 的 svg 在 gzip 压缩后只有大约 60kb。
使用svg大大提高了加载速度,优化了内容的阅读体验。
办公文档在线阅读
这需要两个转换:
office --> pdf --> svg
在线阅读PDF文档
通过pdf2svg转换PDF文档并提供在线阅读
在线阅读mobi、epub、chm文档
使用 calibre 将文档转换为 PDF,然后将 pdf 转换为 svg。
研究所有
全文搜索功能之前是用coreseek开发实现的,现在coreseek官网已经挂了。。。打算用elasticsearch重新实现这个功能。
文档采集功能[TODO]
在建站初期,网站内容的填写是一个很大的难点。
不过GitBook、ReadTheDoc等站点上有很多开源技术文档,提供mobi、pdf、epub离线文档下载。
据初步统计,GitBook 有超过 10 万个文档,估计有 5 万个可用文档,每个文档提供 3 种格式的下载。 光是从gitbook采集文档做成库,就有15万多个文档。

然后,借助搜索引擎,搜索filetype:document format+搜索关键字,比如filetype:pdf入门教程,你会发现惊喜!
如果你爬取其他文档,一年之内,自己搭建一个拥有数百万文档的图书馆站点应该不成问题。
积分功能
用户签到、上传、分享文档,获得积分奖励; 用户下载文件,需要消耗积分
阅读文档水印功能
在提供阅读的svg文件上添加水印
页面概览
项目开源地址:
PC模板
移动模板

