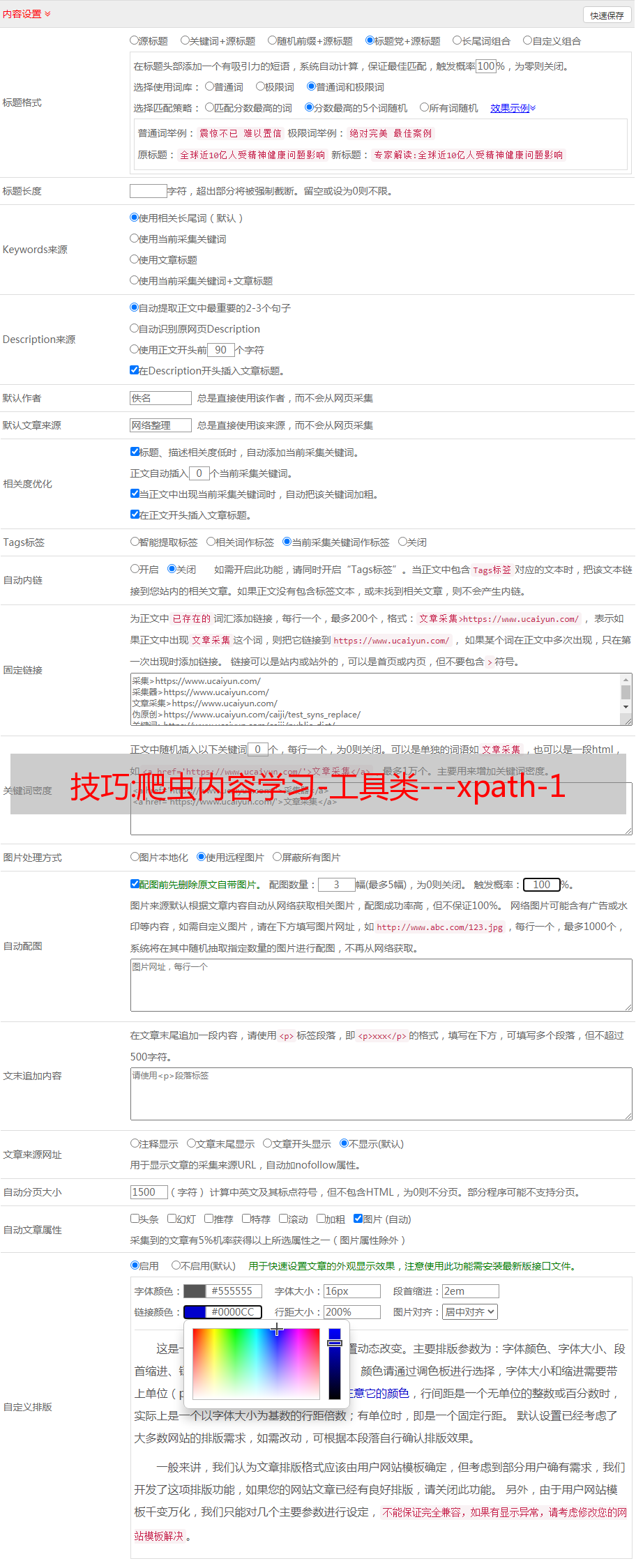
技巧:爬虫内容学习-工具类---xpath-1
优采云 发布时间: 2022-12-24 03:27技巧:爬虫内容学习-工具类---xpath-1
爬虫学习建议:
在编写python爬虫时,只需要做以下两件事:
这两件事,python有相应的库帮你做,你只需要知道怎么用就可以了。
爬虫目前涉及两种类型。 一种是获取网页,比如urllib库和requests库,获取网页,获取内容,保存,响应。
2、分析网页内容:网页内容很多。 爬虫的本质就是选择我需要的内容。 比如我只想要一部分图片,一部分视频或者网页中的一部分特殊内容。 这个选择的“部分”主要包括1.Regular Expression 2.xpath 3.BeautifulSoup 4.jsonparh 5.selenium
前期练习可以使用requests库+正则表达式来练习
在后面的使用过程中,推荐使用requests库+xpath库+XpathHelper【浏览器工具】
建议工作重点:requests库+xpath库+XpathHelper【浏览器工具】+selenium结合使用
个人建议:
背景内容:
XPath在Python爬虫中的使用,相信无论是写爬虫还是做网页分析的人,都会花很多时间在XPath路径的定位和获取上。 在没有这些辅助工具的日子里,我们只能通过搜索HTML源码,定位一些id,class属性来寻找对应的位置,很麻烦,
Chrome插件中的爬虫网页分析工具:XPath Helper
XPath Helper插件是一款免费的Chrome爬虫网页分析工具,可以帮助用户解决获取XPath路径时无法正常定位等问题
安装 XPath Helper 后,您可以轻松获取 HTML 元素的 XPath。 这个插件主要是帮助我们提取和查询在各个网站上查看的页面元素的代码。 同时,我们还可以对查询到的代码进行编辑,编辑后的结果会立即显示在旁边的结果框中,也很方便帮助我们判断自己的XPath语句是否写对了
1.Xpath Helper安装【工具安装】
网上找到的下载地址,大家可以根据实际情况下载
https://chrome.zzzmh.cn/info/hgimnogjllphhhkhlmebbmlgjoejdpjl
安装完成后,在需要匹配数据的页面,使用快捷键打开辅助工具(快捷键:ctrl+shift+x)
2.Xpath Helper的使用
涉及的资料仅限于学习---仅限于学习---
将刚刚复制的xpath内容复制到Xpath Helper工具中,观察结果
3.xpath的语法
XPath(XML Path Language——XML路径语言),它是一种用来确定XML文档某部分位置的语言。
XPath 基于 XML,为用户提供了在数据结构树中查找节点的能力。 XPath 被许多开发人员亲切地称为小型查询语言。
XPath 可以使用路径表达式来选择 XML 上的节点,以达到识别元素的目的。 下面先介绍一下语法规则
语法规则:表达式效果
节点名
选择该层级节点下的所有子节点
/
表示从根节点开始选择
//
可以理解为匹配,就是在所有节点中选择这个节点,直到匹配
.
选择当前节点
……
选择当前节点的上层(upper directory)
@
选择属性(也匹配)
标签定位:
方法
影响
/html/正文/div
表示从根节点开始查找,标签之间/代表一个层次
/html//分区
表示多级作用于两个标签之间(也可以理解为html下匹配查找标签div)
//分区
从任意一个节点开始查找,即查找所有的div标签
./分区
表示从当前标签开始寻找div
属性定位
需要
格式
在属性名为href且属性值为''的div中找到div标签
@属性名=属性值
href是属性名''是属性值
/html/正文/div[href='']
指数定位
找到 ul 下的第二个 li 标签(下图)
//ul/li[2]
索引值开始于
1个
获取文本内容
方法
影响
/文本()
直接获取标签下的标签内容
//文本()
获取标签中的所有文本内容
细绳()
获取标签中的所有文本内容
4.在python中使用
使用步骤:
1.安装lxml库
pip 安装 lxml
2.导入lxml
from lxml import etree
3. 解析文件 3.1 解析本地文件(离线文件)
html_tee=etree.parse("xxx.html")
3.2 解析网络文件(Internet URLs) 系统自带urllib库
html_tee=etree.HTML(response.read().decode("utf-8"))
3.3 如果是响应库
import requests
response = requests.get(url=f'http://www.baidu.com', headers=headers)
#可选步骤,如果网页是gb2312编码,这里修改,否则不用加
response.encoding='gb2312'
html_tee = etree。 HTML(响应。文本)
4.加载文件
最重要的是xpath规则的编写。 这个规则也很简单。 掌握以下就足以满足爬虫的使用了。
xpathguize="//div[@class="info-con pd20"]//img/@src"
html_tee.xpath(xpathguize)
5 附则汇编:
1.如何定位元素,下面的《5.2网络源码样式》,这里如何在img的src中找到图片地址
5.1 F12调出网页源代码(或右击网页选择“检查”),选择需要的图片右击
下面的元素选择在右边显示了你需要的xpath
调出xpath和浏览器工具,修改自己需要的样式,查看右边选择是否正确
选择要点:
充分掌握xpath中的以下1和2,就可以写出好的xpath规则,可以满足大部分需求
1.定位,用属性定位
//div[@class="box box-blue-bold"]//li//img//@src
//div[@class="box box-blue-bold"]//li//img//@src
说明:定位就是找到你想要的元素在网页中的起始位置---定位函数
[@class="box box-blue-bold"]===就是用class定位标签,
经常使用的是@id="xxx" 和@class="xxx"
如:div[@class="box box-blue-bold"], div[@id="con_latest_1"]
2.获取元素属性内容--必填内容,一般图片地址,视频地址大部分
//div[@class="box box-blue-bold"]//li//img//@src
/@src是获取img的src的连接地址信息,可以获取图片地址信息"""
5.2 网页源码样式:
三体性
剧情/科幻/*敏*感*词*
操作方法:Dedecms采集功能的使用方法---含有分页的普通文章的采集(三)
前言:本文为分页普通文章采集方法之三。 在前面两节的基础上,详细介绍如何采集指定节点以及如何导出采集内容。 为了与上一篇文章保持一致,本文将继续使用上一篇文章的章节标记。 进入第二部分。 3.1采集指定节点点击保存开始采集后,会进入“采集指定节点”界面,如图(图29),图29-每页采集指定节点:这里是设置要采集的条目数每页采集,可根据网站是否有防刷新功能设置采集间隔 特殊选项:设置是否检测重复图片,默认为“检测” 附加选项:有3种采集模式可供选择from 在这个选项中:第一个是监控采集方式(检查当前或所有节点是否有新内容),选择后,系统只会采集指定节点中更新的内容; 二是“重新下载所有内容”,选择后系统会采集指定节点的所有内容; 三是“下载*敏*感*词*网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载的内容和更新后的内容。设置完成并确认无误后,可以点击“开始采集网页”或“查看*敏*感*词*网址”。此时如果点击“查看*敏*感*词*网址”,会看到列表为空,表示这是因为新建立的采集节点一直没有采集过,如图(图30),图30-查看节点的*敏*感*词*URL 点击开始采集网页后,系统会开始采集节点中设置的URL,以及相关的Prompt,如图(图31),图31-采集过程中的提示信息采集完成后,再次点击“查看*敏*感*词*网址”或者点击页面右上角的“查看已下载”即可查看已经采集的网址 采集信息,如图(图32),图32-视图节点的*敏*感*词*URL采集成功后,可以根据实际需要在页面右上角选择“采集节点管理”或“导出数据” .
点击导出数据后,可以进入“采集管理>采集内容导出”界面,如图(图33),图33-采集内容导出默认导出列:设置采集内容将导入到的列批量采集选项":如果在采集规则中已经指定了column ID,则可以使用该函数。 如果指定的栏目ID为0,系统会将采集的内容导入到默认导出栏目选择的栏目中。 发布选项:有,正常发布“文档”和“另存为草稿”可用。导入每批次:设置每批次导入的文章数量,这个数量不能太大。附加选项:这里可以多选。如果不想采集重复的文章标题,可以选择Exclude duplicate titles”; 如果希望采集的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”; 如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不建议勾选此选项。“随机推荐”:填写一个数字代表文档数量。推荐的文档会在填写的文档数量中随机出现。如果填写0”,则表示不推荐。 设置完成后点击“确定”将下载的内容导入到选中的栏目中,如图(图34),图34-设置完成后的采集内容导出页面同时,系统会有一、导出进度提示,如图(图35),图35-采集内容导出中的提示信息 导出采集内容提示“完成所有栏目列表更新”,点击“浏览栏目”,即可进入相关页面的网站查看采集的文章列表及其具体内容。
也可以在后台管理界面主菜单中点击“核心”,然后点击“常用文章”进入文献列表页面,查看采集文章列表,如图(图36)。 图36-文档列表在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面变化部分,如图(图37) . 图 37-Page Breaking 显示它收录的分页文章内容已被成功采集。 综上所述,本文详细介绍了如何通过分页对常见文章类型的页面进行采集,并简单介绍了过滤规则。 对于比较复杂的常见文章类型页面的采集和过滤规则的使用,会在以后的文章中介绍。 本文采集规则:{dede:listconfig}{dede:noteinfonotename="采集测试(二)"channelid="1"macthtype="string"refurl=""sourcelang="gb2312"cosort="asc"isref="没有 "exptime="10"usemore="0"/}{dede:listrulesourcetype="batch" rssurl=";regxurl="(*).html"startid="1"endid="1"addv = "1"urrlrule="area" musthas=""nothas=""listpic="1"usemore="0"}{dede:addurls}{/dede:addurls}{dede:batchrule}{/dede:batchrule} { dede:regxrule}{/dede:regxrule}{dede:areastart}
{/dede:areastart}{dede:areaend}
{/dede:areaend}{/dede:listrule}{/dede:listconfig}{dede:itemconfig}{dede:sppagesptype='full'srul='1'erul='5'}
[内容]
{/dede:sppage}{dede:previewurl}{/dede:previewurl}{dede:keywordtrim}{/dede:keywordtrim}{dede:descriptiontrim}{/dede:descriptiontrim}{dede:itemfield='title'value=' 'isunit=''isdown=''}{dede:match}[content]{/dede:match}{dede:function}{/dede:function}{/dede:item}{dede:itemfield='writer'value =''isunit=''isdown=''}{dede:match}{/dede:match}{dede:function}{/dede:function}{/dede:item}{dede:itemfield='source'value= ''isunit=''isdown=''}{dede:match}来源:[content]{/dede:match}{dede:function}{/dede:function}{/dede:item}{dede:itemfield=' pubdate'value=''isunit=''isdown=''}{dede:match}time:[content]{/dede:match}{dede:function}{/dede:function}{/dede:item}{dede :itemfield='body'value=''isunit='1'isdown='1'}{dede:match}[content]{/dede:match}{dede:trimreplace=""}
(.*)
{/dede:trim}{dede:trimreplace=""}
(.*)
{/dede:trim}{dede:trimreplace=""}
(.*)
{/dede:trim}{dede:function}{/dede:function}{/dede:item}{/dede:itemconfig}【如何使用Dede cms的采集功能---普通文章的采集带分页(3 )网站URL: [db: 来源名称]]

