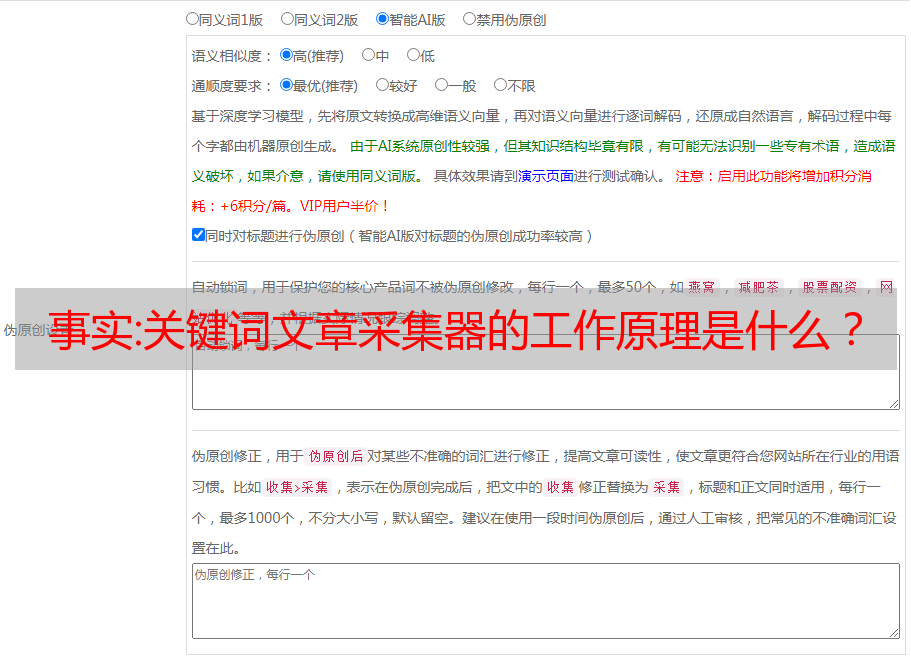
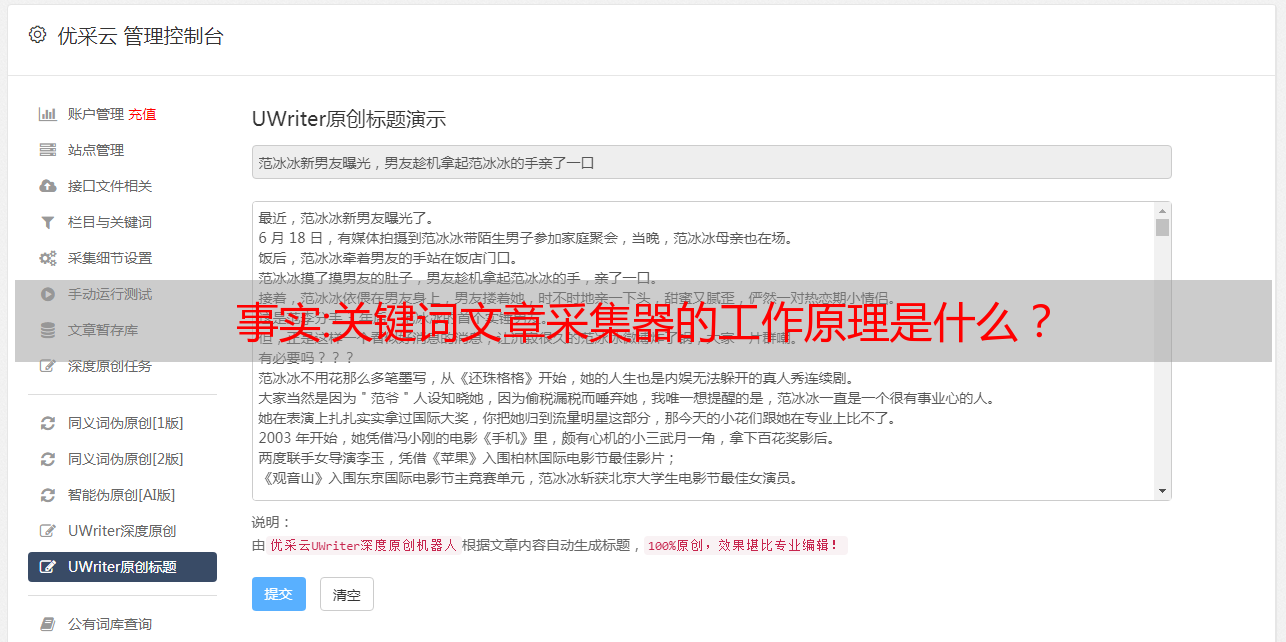
事实:关键词文章采集器的工作原理是什么?
优采云 发布时间: 2022-12-23 21:16关键词文章采集器的工作原理是?-知乎用户的回答
采集网页的源码,web服务器处理后,找一个共享的文件夹,大概就是files下那个,然后将这个文件夹内的内容同步到采集器上。然后去采集器里,采集第一页,再采集第二页,直到全部采集完。所以第一次进去你会看到很多页面,每个页面下面会有一个二维码,复制这个二维码,就会跳转到别的页面了。
是时候上这张图了
中午刚刚完成的操作,来答。采集页面我设置了时间日期文本,点击开始采集就会同步抓取页面文本,每次抓取都会清空。抓取过程采用系统自带浏览器采集和通过爬虫爬取,爬虫的建议用beego、nodejs,beego功能比较强大,爬虫是爬虫,采集应该用beego的自定义爬虫,比如时间文本,beego有自定义的两个插件,一个issuetask,一个slogan,可以调用二维码和ip地址,看看给我这么多都干什么。
beego可以整合在nodejs中,用nodejs采集,可以考虑下他的对象操作,自带封装,中间件。不推荐用户自定义,在采集服务器同步每个文件的时候也方便,不用去读取每一行,每一个dom,也可以看到点击一个文件的请求。
在淘宝上看到一篇介绍三个爬虫的文章,有不少讲得比较清楚。如下文字采集网页源码首先需要有一个buffer来记录文件名和html格式,然后后续的操作都在buffer上跑。如果你有scrapy环境,那buffer文件会同步scrapy服务器下的所有dom节点。如果你没有scrapy环境,同样可以用requests自带的loader进行采集,只是在大部分网站你需要定制一个格式方法,并在最后用parse方法处理不是位置抽风的buffer文件。
如果你用scrapy爬取页面,每个按钮事件单独处理,就是像抓包一样抓取web,也可以采用dnsselector等requests工具进行网页解析。如果你自己做,大体上可以按照方法爬取。

