解决方案:网页采集器的自动识别算法什么的,没那么复杂
优采云 发布时间: 2022-12-23 12:15解决方案:网页采集器的自动识别算法什么的,没那么复杂
网页采集器的自动识别算法什么的,没那么复杂。每一个网站都自己的特征,根据网站类型,收录规则,排名情况,权重高低等等数据来采集。然后形成指纹,用后台系统识别为不同ip/wap/http等等。ai能识别广告,识别爬虫,识别公告,分析网站规则。所以其实不难。除非,网站本身就是人工发布,
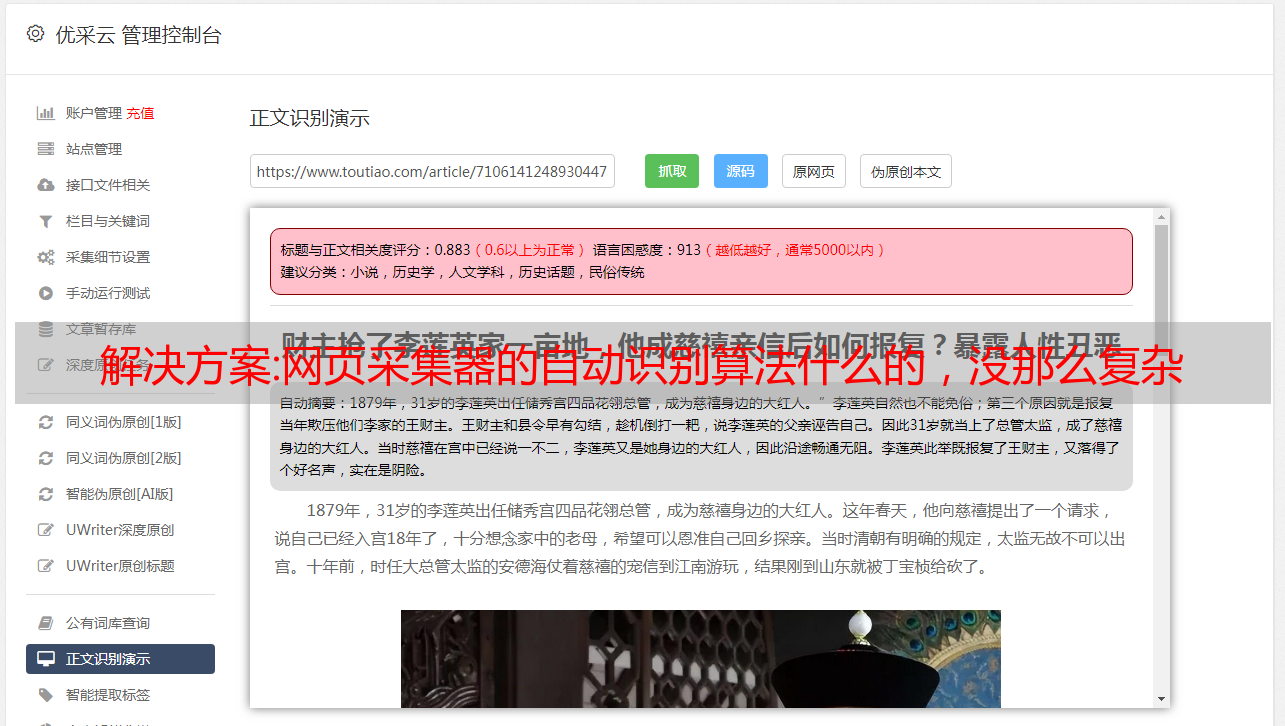
采集器是不能准确识别的。如果采集器可以识别的话网站数据量就会非常多了,就像现在的网页采集器一样。其次网站数据库也不是每个网站都有的。既然网站是人工爬的,就一定有人工有爬虫。总之一句话想多了,好好想想怎么爬网站就成了。
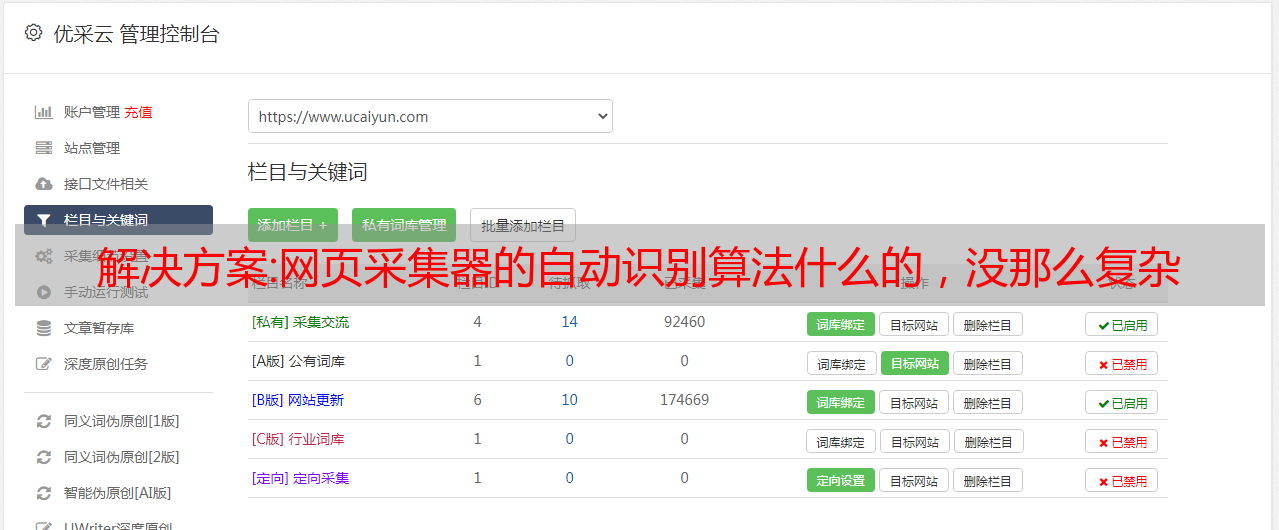
其实不用后台的的那些东西,采集站里面一个采集器即可获取链接全部信息。然后再识别不同来源的链接来生成不同的标签,识别完成后去除链接的图片图片地址就可以做到识别页面地址了。所以只要改变网页的编码格式就可以完成不同页面的识别了。
看我这里理解:1.前端采集,这种基本方法都可以;2.一个采集器全部。缺点是怎么定位全中国内的网站,全中国还是全美国,全日本,全英国,都很头疼。3.比较高级的采集方法,需要前端时常定位,需要前端时常修改cookie,不过有利于性能、浏览时延等,可以省去。不过这个更多的依赖于javascript的能力,再放大到整个互联网,可能就没有那么容易了。

