汇总:1.如何抓取网页上的数据,需要登录
优采云 发布时间: 2022-12-23 04:53汇总:1.如何抓取网页上的数据,需要登录
如何采集需要登录的网页(如何为需要登录的网页采集文件)
2022-11-2810
目录:
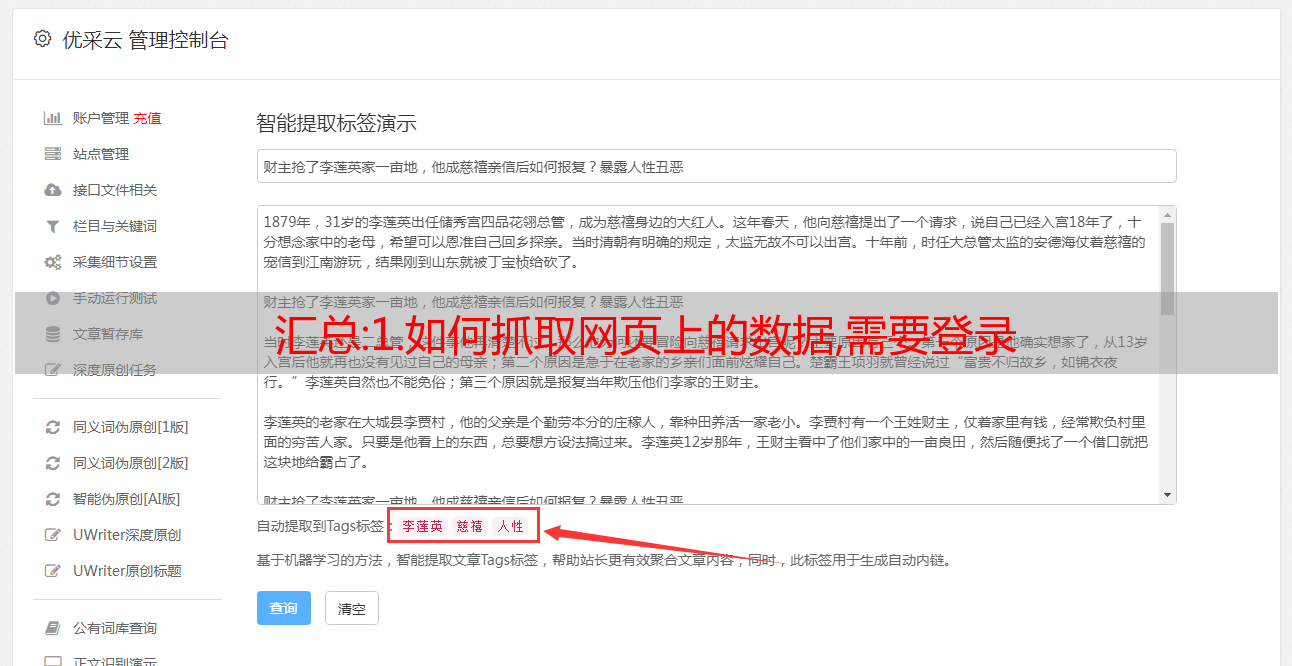
1、如何爬取网页上的数据,需要登录
如何爬取网页上的数据,需要登录? 随着互联网的发展,移动支付技术的普及,以及人们消费内容的观念,有很多网站只能付费才能浏览,或者只有开通会员才能浏览。 对于这样的网站,我们如何才能快速将需要的内容采集到本地并下载。 本文将详细解释! .
2、如何采集网页数据
小编会教你如何快速采集需要登录的网页,无论是导出到本地还是发布到网上,只需点几下鼠标就可以得到数据。 网络创作者还可以实现自动采集、定期发布、批量文章处理,让您瞬间拥有强大的资讯和数据内容,增加流量和知名度。
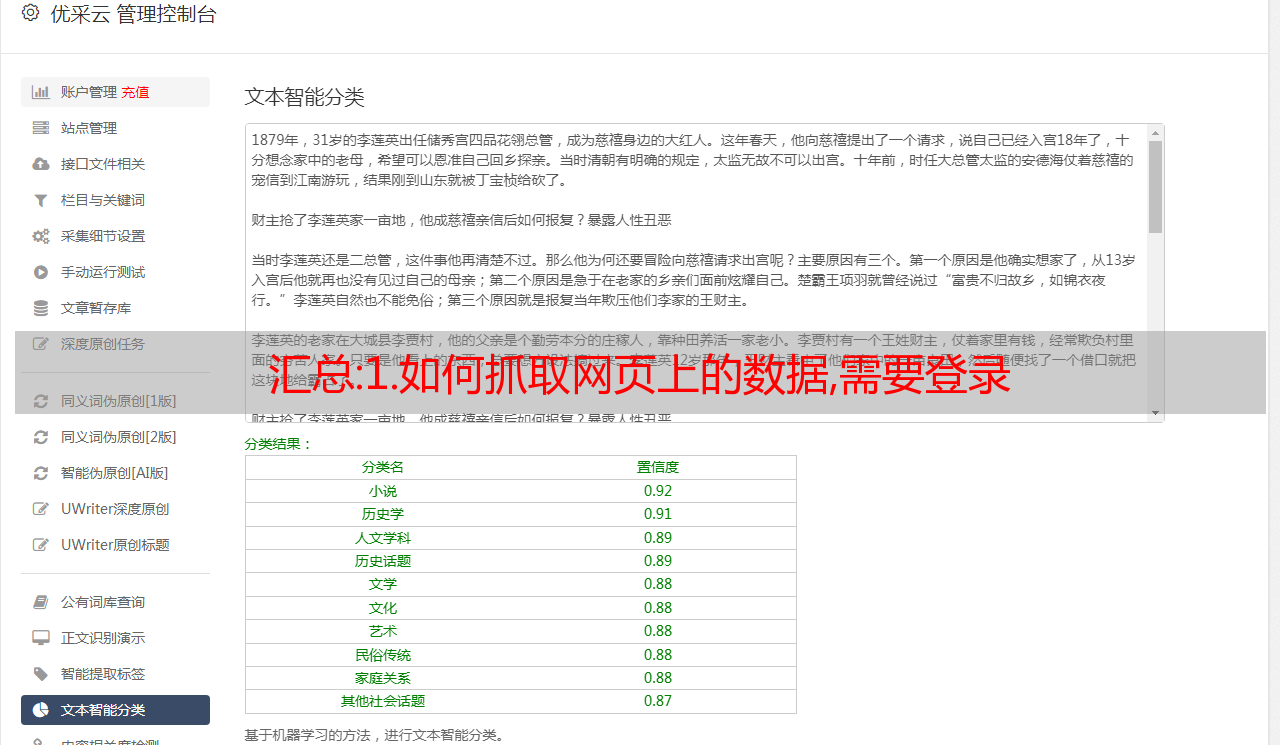
3. 网页内容采集
用户通过搜索引擎在网上搜索他们想要的东西 无论您是销售产品、服务、博客还是其他任何东西,SEO 优化都是必经之路 您的网站需要被搜索引擎收录 否则,您无法找到的页面将得到改善您在搜索引擎结果页面 (SERP) 中的排名。
四、信息采集如何登录
排名越高意味着流量越高,我们可以抓取网页上的数据进行分析。 搜索引擎优化的意义是什么? 近年来,越来越多的商家开始建立自己的品牌独立站,进行电子商务交易。 这些商家经常使用各种搜索引擎优化的方法来提高他们的网站在搜索引擎中的排名。
5.抓取需要登录的网站数据
但是还是有很多人不明白为什么要SEO
6.如何采集整个网站
1、SEO提高网站关键词排名的意义是什么? 更基础的是提高网站的关键词排名。 关键词是用户在搜索引擎搜索框中输入的最有可能找到他们需要的信息的单个单词或短语。 拥有一个好的关键词排名可以让网站更容易被搜索到。
7.如何采集其他网站内容
虽然搜索引擎优化的方法多种多样,但最终都会在一定程度上提高网站的关键词排名网站 2.增加网站的关键词网站 这意味着在一定程度上增加了网站的曝光度,将网站的相关产品和服务信息展示给更多的用户。
八、网页数据的采集方法
3、丰富网站内容当你没有SEO概念时,可以网站网站,可以是产品、知识、新闻、文章、以及做好这件事以后,即使你什么都不做SEO,谷歌还是会抓取你丰富的网站内容,你的网站还是会产生不错的流量,因为搜索引擎的目的不是排名,而是让搜索的人信息得到有意义的结果和正确的信息。
9. 如何采集网站数据
搜索引擎原理 爬虫 爬虫是指通过成千上万的小机器人扫描一个网站,它的结构、内容、关键词、标题、超链接、图像,以及任何可以在网站上找到的数据都会被爬虫在网站上抓取和检测所有指向其他网站的超文本链接,然后他们一遍又一遍地解析这些页面以获得新链接。
10、如何抓取网页数据
机器人程序会定期抓取整个互联网以更新数据
搜索引擎索引的原则 一旦一个网站被抓取,索引就开始了 把这个索引想象成一个巨大的目录或一个充满网站网站需要一些时间才能被索引 根据我们的经验,它大约是 1 到 10天,每次更改时,爬虫都会再次扫描它。
请记住,网站上的更新在被索引之前对搜索引擎是不可见的。 搜索引擎如何挑选结果 结果对开发人员和用户都很重要。 挖掘索引并提取匹配结果。 这是一个基于各种算法检查数十亿个网站查询的过程。
搜索引擎公司(谷歌、微软、百度、雅虎!)对其算法的精确计算保密。 尽管如此,许多排名因素是众所周知的。
分享文章:织梦模板内容页列表页首页调用文章tag带url链接的教程
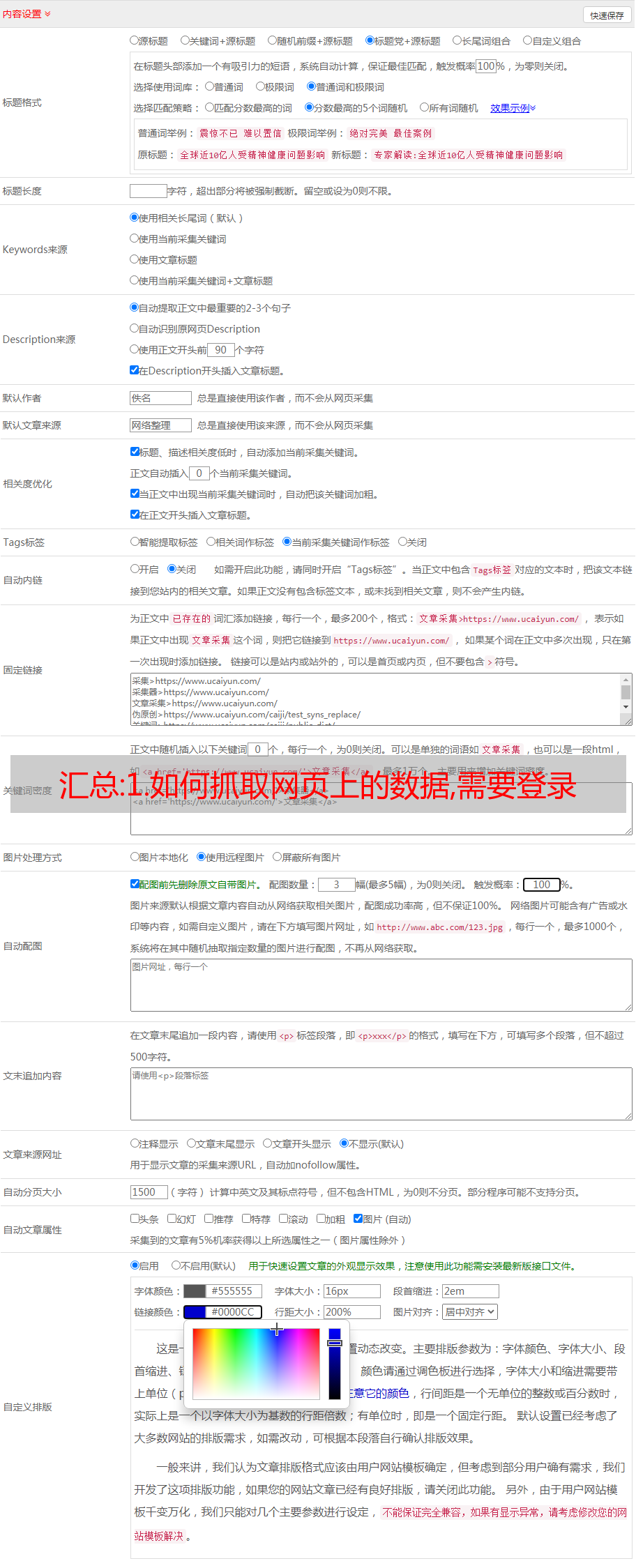
1.修改系统参数设置(文档标题最大长度)
系统-系统设置-系统基本参数-其他选项-文档标题最大长度:255
2.修改文档表dede_archives中title字段varchar(255)
系统-系统设置-SQL命令行工具,输入代码执行:
更改表 dede_archives 更改标题 title varchar(255)
3.修改采集数据导入程序co_export.php
打开后台文件夹(默认为dede),找到co_export.php的220行:
$mainSql = str_replace('',cn_substr($title,60),$mainSql);
将 60 更改为 $cfg_title_maxlen

