解决方案:自适应自适应滚屏企业宣传网站 演示/IT科技、软件、通讯业
优采云 发布时间: 2022-12-22 19:16解决方案:自适应自适应滚屏企业宣传网站 演示/IT科技、软件、通讯业
模板介绍点云自助建站系统V8门户版特点:
1.文章管理信息分类、权限配置、单页、新闻列表、友情链接、文章采集
2.产品管理系统产品参数、产品品牌、权限配置、产品列表、产品类型、产品分类、产品回收站、CVS导入
3.前端可视化栏目管理、文件管理库、可视化系统、区域设置、语言设置、HTML自定义自定义表单、tinymce编辑器、HTML模板、表单*敏*感*词*
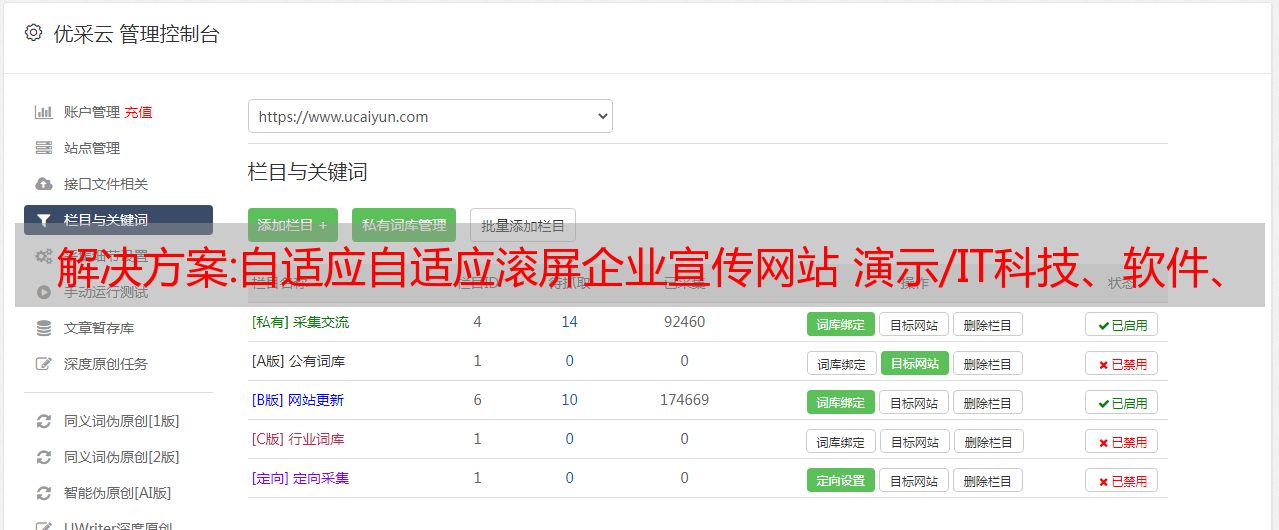
4.微站小程序模板消息,关键词回复,粉丝列表,自定义菜单,图文消息,群消息,公众号,小程序,小程序下载,订阅消息,小程序码
5.账号站点账号权限、平台管理、财务管理、会员管理、登录日志、用户组权限管理、财务记录、支付记录、权限规则、会员列表、会员留言、评论管理、通知留言、会员群组
6.商品推广功能 拍卖活动、议价活动、秒杀活动、团购活动、积分制、佣金管理、优惠券、抽奖活动
7. 订单管理 订单数据、订单清单、*敏*感*词*管理、退货处理
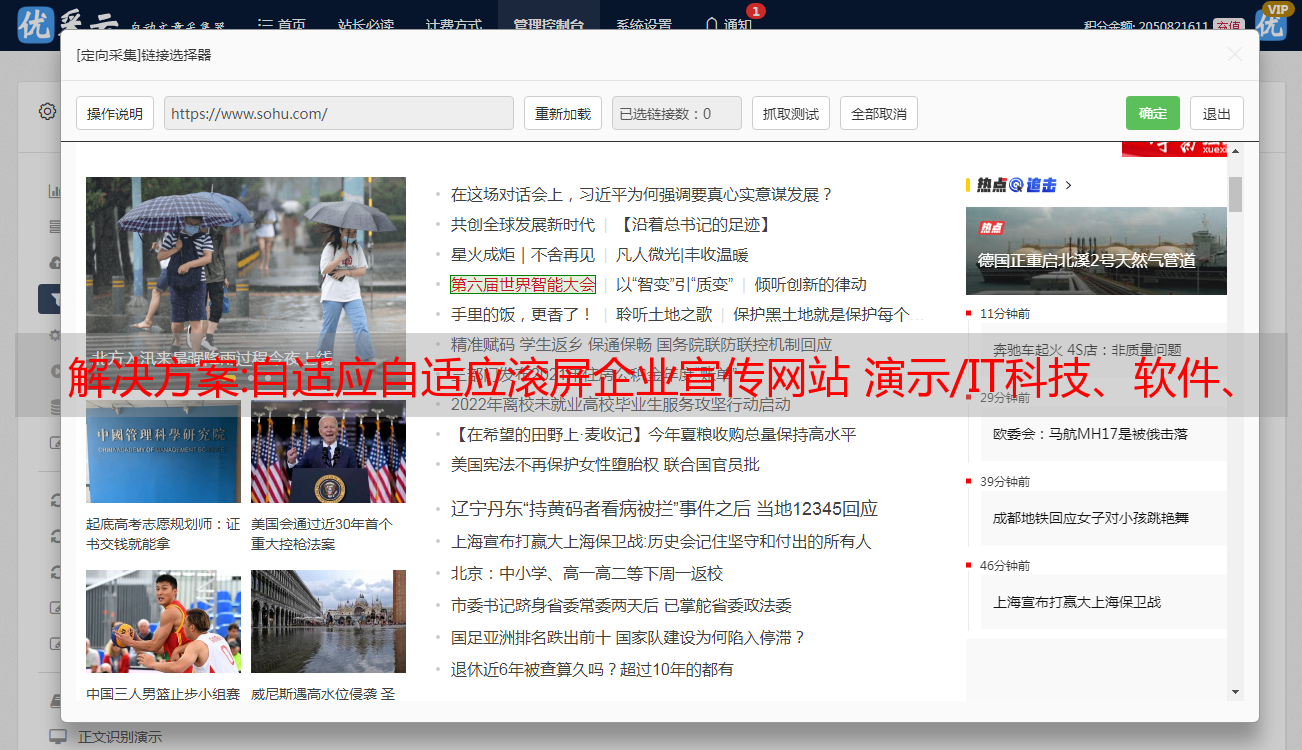
8.系统配置选项卡设置、系统设置、安全更改、密码更改、上传设置、数据维护、清除缓存、前台搜索
9、扩展功能投票系统、计划任务、地图导航、物流配送、小票打印机、短信通知、邮件系统、支付设置、快捷登录、客服系统、广告系统。
10.门户功能组件文集小说、问答系统、视频系统、论坛系统、图库系统、音频系统、分类信息(信息列表、组件配置、信息分类、信息举报、信息打赏、评论列表、信息采集)、下载系统等
如果您是建站平台版的源码用户,还支持建站平台功能,包括自助建站、续费、建站包模块管理等更多高级功能。
解决方案:一文学会 Prometheus:开源系统监视和警报工具包
标题图片 | CSDN东方IC下载
出品 | CSDN(ID:CSDNnews)
Prometheus 是一个开源系统监控和警报工具包,最初构建在 SoundCloud 上。 自 2012 年成立以来,许多公司和组织都采用了 Prometheus。 这个项目发展到今天,已经完全接管了Kubernetes项目的整个监控体系。
和Kubernetes项目一样,Prometheus项目也来自谷歌的Borg系统。 它的原型系统,叫做BorgMon,是一个几乎与Borg同时诞生的内部监控系统。
普罗米修斯的优势
Prometheus 非常适合记录任何纯数字时间序列。 它既适用于以机器为中心的监控,也适用于监控高度动态的面向服务的架构。 它对多维数据采集和查询的支持是微服务领域的一个特殊优势。
Prometheus 专为可靠性而设计,使其成为在中断期间使用的系统,使您能够快速诊断问题。 每个 Prometheus 服务器都是独立的,不依赖于网络存储或其他远程服务。 当您的基础设施的其他部分出现故障时,您可以依赖它,而无需构建广泛的基础设施来使用它。
Prometheus不适合哪些场景?
Prometheus 重视可靠性。 始终可以查看有关系统的可用统计信息,即使在出现故障的情况下也是如此。 但如果你需要 100% 的准确性(比如按请求计费),Prometheus 不是一个好的选择,因为采集的数据可能不够详细和完整。 在这种情况下,最好使用另一个系统来采集和分析账单数据,并使用 Prometheus 进行其余的监控。
普罗米修斯架构
下图展示了Prometheus及其组件的整体架构:
从图中可以看出主要包括以下几个组件:
特征
普罗米修斯的主要特点是:
Prometheus 由几个组件组成,其中很多组件是可选的,例如:
下载运行
直接去GitHub下载最新版本:
下载后解压,进入目录,执行:
[root@k8s prometheus-2.15.0.linux-amd64]# ls
console_libraries consoles data LICENSE NOTICE prometheus prometheus.yml promtool tsdb
[root@k8s prometheus-2.15.0.linux-amd64]# ./prometheus
程序启动后会输出一些日志。 默认*敏*感*词*端口为9090,使用prometheus目录下的prometheus.yaml配置文件。 程序启动时,会先启动prometheus,然后启动TSDB(时序数据库):
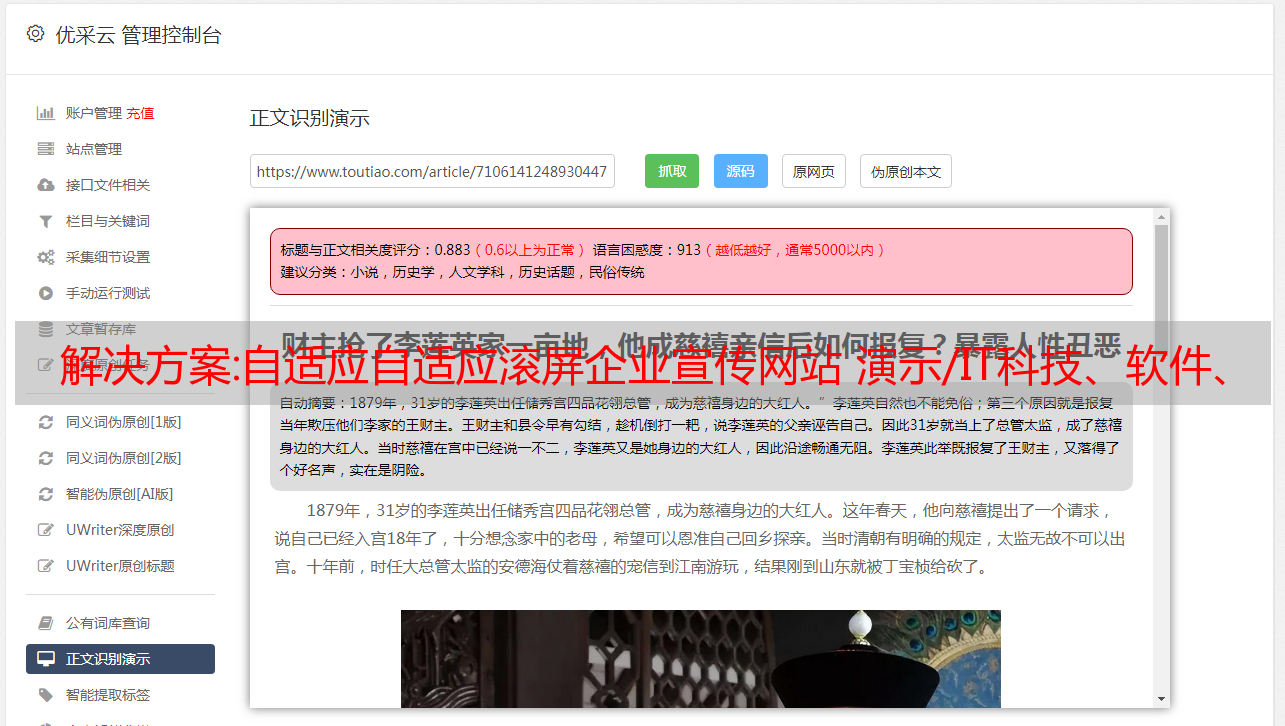
level=info ts=2019-12-24T06:34:56.601Z caller=main.go:294 msg="no time or size retention was set so using the default time retention" duration=15d
level=info ts=2019-12-24T06:34:56.601Z caller=main.go:330 msg="Starting Prometheus" version="(version=2.15.0, branch=HEAD, revision=ec1868b0267d13cb5967286fd5ec6afff507905b)"
level=info ts=2019-12-24T06:34:56.601Z caller=main.go:331 build_context="(go=go1.13.5, user=root@240f2f89177f, date=20191223-12:03:32)"
level=info ts=2019-12-24T06:34:56.601Z caller=main.go:332 host_details="(Linux 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 k8s (none))"
level=info ts=2019-12-24T06:34:56.601Z caller=main.go:333 fd_limits="(soft=1024, hard=4096)"
level=info ts=2019-12-24T06:34:56.602Z caller=main.go:334 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2019-12-24T06:34:56.604Z caller=main.go:648 msg="Starting TSDB ..."
level=info ts=2019-12-24T06:34:56.604Z caller=web.go:506 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2019-12-24T06:34:56.607Z caller=head.go:584 component=tsdb msg="replaying WAL, this may take awhile"
level=info ts=2019-12-24T06:34:56.612Z caller=head.go:632 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=2
level=info ts=2019-12-24T06:34:56.616Z caller=head.go:632 component=tsdb msg="WAL segment loaded" segment=1 maxSegment=2
level=info ts=2019-12-24T06:34:56.617Z caller=head.go:632 component=tsdb msg="WAL segment loaded" segment=2 maxSegment=2
level=info ts=2019-12-24T06:34:56.618Z caller=main.go:663 fs_type=EXT4_SUPER_MAGIC
level=info ts=2019-12-24T06:34:56.618Z caller=main.go:664 msg="TSDB started"
level=info ts=2019-12-24T06:34:56.619Z caller=main.go:734 msg="Loading configuration file" filename=prometheus.yml
level=info ts=2019-12-24T06:34:56.620Z caller=main.go:762 msg="Completed loading of configuration file" filename=prometheus.yml
level=info ts=2019-12-24T06:34:56.620Z caller=main.go:617 msg="Server is ready to receive web requests."
这时候通过浏览器访问,可以看到如下界面,这是prometheus的控制台:
配置文件
prometheus.yml是prometheus的配置文件,可以使用如下命令指定配置文件启动prometheus:
prometheus --config.file=prometheus.yml
它的默认配置如下:
# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
包括:
其中,global是一些常规的全局配置,这里只列出两个参数:
scrape_configs 指定 prometheus 监控的目标。 在scrape_config中,每个监控目标都是一个job,但是job的种类很多。 可以是最简单的static_config,静态指定各个target,比如上面这样:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
默认配置文件 scrape_configs 定义了一个作业来监控 prometheus 本身。 可以访问ip:9090/metrics访问prometheus本身的监控数据:
我们用浏览器访问:9090/metrics,可以看到一个实例暴露的监控指标。 除了评论,每隔一行就是一个监控指标项,大部分是这样的形式:
go_info{version="go1.10.3"} 1
这里go_info是metric的名字,version是metric的label,go1.10.3是metric的version标签的值,1是metric的当前采样值,metric的一个label可以有0或更多标签。 这就是上面提到的监控指标数据模型。
可以看到一些指标的形式如下:
go_memstats_frees_total 131961
根据prometheus官方推荐的规范,metrics的通用类型以_total为后缀的是counter计数器类型。
一些指标采用以下形式:
go_memstats_gc_sys_bytes 213408
该指标的一般类型是仪表类型。
一些指标采用以下形式:
prometheus_http_response_size_bytes_bucket{handler="/metrics",le="100"} 0prometheus_http_response_size_bytes_bucket{handler="/metrics",le="1000"} 0prometheus_http_response_size_bytes_bucket{handler="/metrics",le="10000"} 46prometheus_http_response_size_bytes_bucket{handler="/metrics",le="100000"} 46prometheus_http_response_size_bytes_bucket{handler="/metrics",le="1e+06"} 46prometheus_http_response_size_bytes_bucket{handler="/metrics",le="1e+07"} 46prometheus_http_response_size_bytes_bucket{handler="/metrics",le="1e+08"} 46prometheus_http_response_size_bytes_bucket{handler="/metrics",le="1e+09"} 46prometheus_http_response_size_bytes_bucket{handler="/metrics",le="+Inf"} 46prometheus_http_response_size_bytes_sum{handler="/metrics"} 234233prometheus_http_response_size_bytes_count{handler="/metrics"} 46
这是直方图直方图的类型。
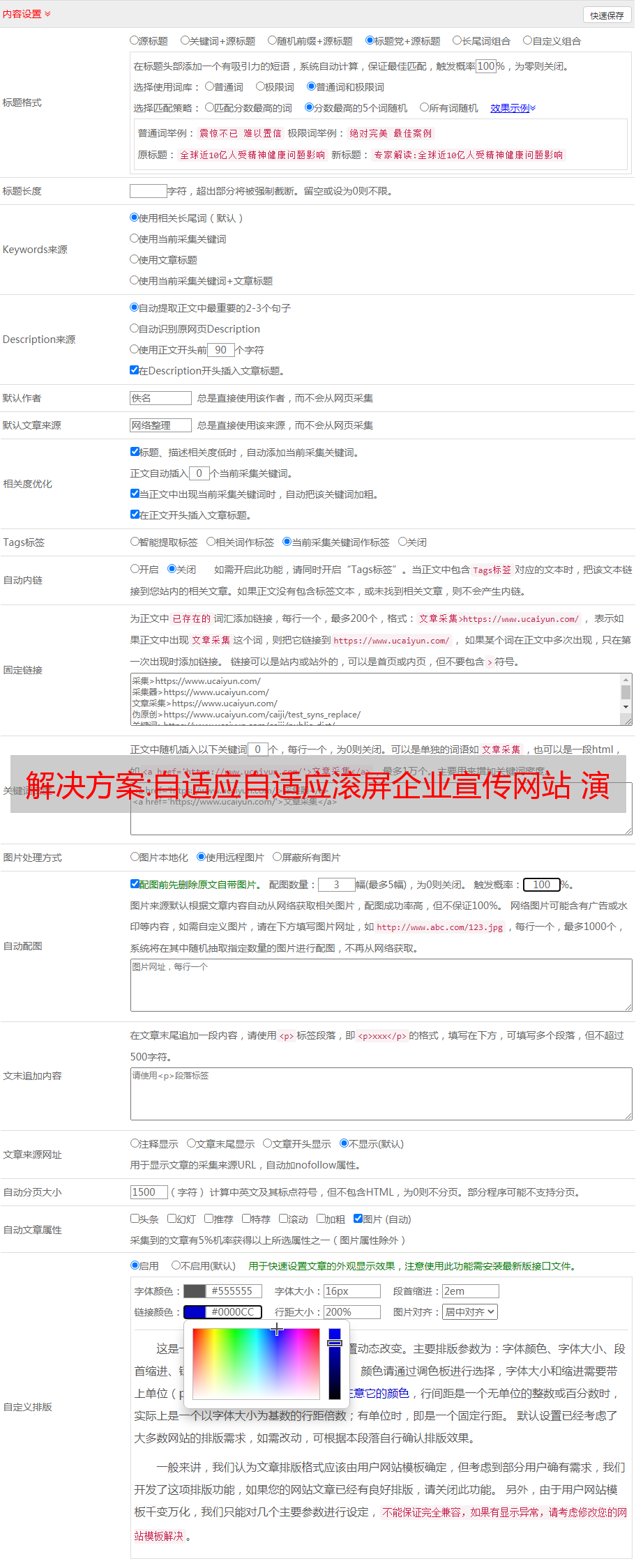
还有如下形式:
go_gc_duration_seconds{quantile="0"} 7.3318e-05go_gc_duration_seconds{quantile="0.25"} 0.000118693go_gc_duration_seconds{quantile="0.5"} 0.000236845go_gc_duration_seconds{quantile="0.75"} 0.000337872go_gc_duration_seconds{quantile="1"} 0.000707002go_gc_duration_seconds_sum 0.003731953go_gc_duration_seconds_count 14
这是摘要摘要类型。
更多配置说明,可以阅读官网文档:
Prometheus的一些概念
Jobs and Instances(任务和实例)
对于Prometheus而言,拉取采样点的端点服务称为实例。 多个这样拉取采样点的实例构成一个作业。
例如,名为 api-server 的任务有四个相同的实例。
job: api-server instance 1:1.2.3.4:5670 instance 2:1.2.3.4:5671 instance 3:5.6.7.8:5670 instance 4:5.6.7.8:5671
自动生成的标签和时间序列
Prometheus在拉取一个target时,会自动在metric名称的tag列表中添加两个tag,分别是:
对于每个采样点所在的服务实例,Prometheus 会存储如下的metric采样点:
up 指标对于监控服务 health.data 模型非常有用
从根本上说,Prometheus 存储的所有数据都是一个时间序列:一串只与单个指标和该指标下的多个标签维度相关的带有时间戳的数据流。除了存储时间序列数据,Prometheus 还可以使用查询表达式来存储时间序列5分钟返回结果中的数据
指标和标签(指标名称和标签)
每条时序数据由metric名称及其labels标签键值对集合唯一标识。
metric名称指定监控目标系统的度量特征(例如:http_requests_total-接收到的http请求总数)。 指标名称由 ASCII 字母、数字、下划线和冒号命名。 它必须与正则表达式 [a-zA-Z_ :][a-zA-Z0-9_:]* 匹配。 标签启用Prometheus的多维数据模型:对于同一个metric名称,通过不同标签列表的组合,会形成一个特定的metric维度实例。 (例如:所有收录metric名称/api/tracks的http请求都打上method=POST标签,组成一个特定的http请求)。 查询语言根据这些指标和标签列表进行过滤和聚合。 更改任何指标上的任何标签值将形成一个新的时间序列图标签标签名称可以收录 ASCII 字母、数字和下划线。 它们必须匹配正则表达式 [a-zA-Z_][a-zA-Z0-9_]*。 带 _ 下划线的标签名称保留供内部使用。
labels 值收录任何 Unicode 代码。
有序采样值
有序的采样值构成了时间序列数据的实际列表。 每个样本值包括:
总结:通过在metric指标下指定metric名称和相关标签值,确定感兴趣的目标数据,随时间形成一个点,实时在图表上画出一条动态变化的线''
符号
要表示一个指标和一组键值标签,请使用以下表示法:
[指标名称]{[标签名称]=[标签值], ...}
例如metric名称为api_http_requests_total,标签为method="POST",handler="/messages"的示例如下:

