汇总:信息收集工具 -- 水泽(V1.0)
优采云 发布时间: 2022-12-20 05:50汇总:信息收集工具 -- 水泽(V1.0)
0x01 工具介绍
只需输入域名,即可全方位采集信息,检测漏洞。 也可以输入多个域名、C段IP等。
0x02 安装使用
1.安装需要的库文件
pip install -r requirements.txt
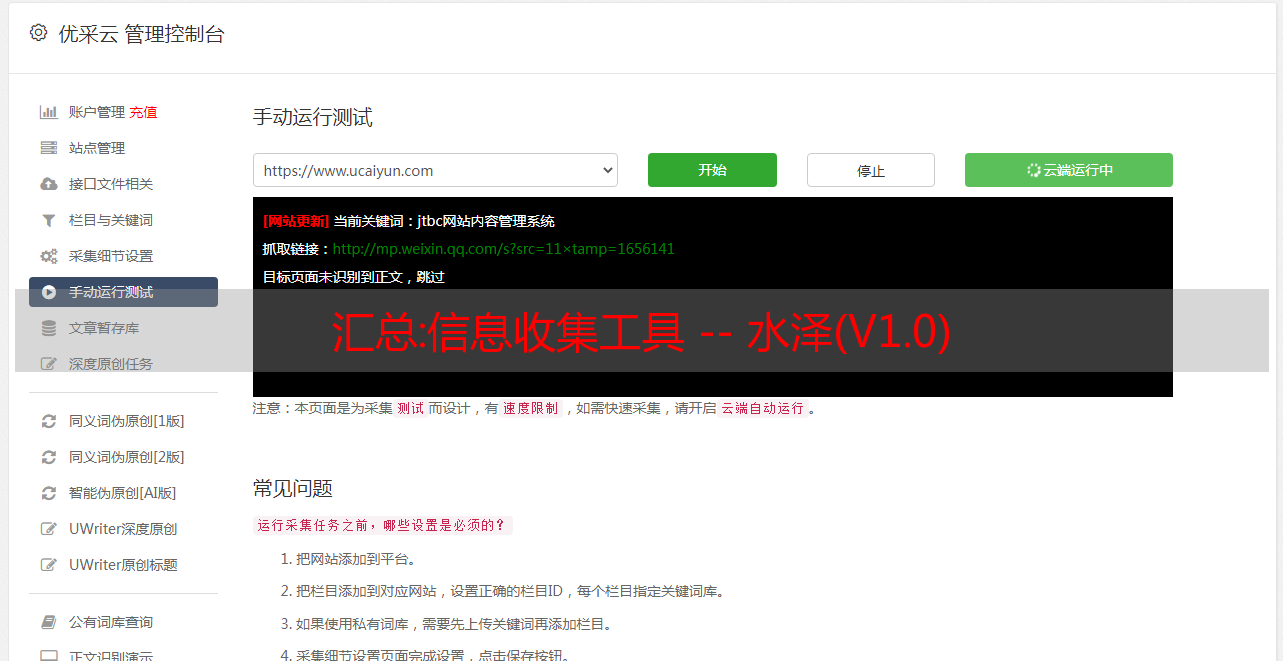
2.修改配置文件,把可以填写的API都填上,平台越多,采集的信息越多
3.可以在底部添加代理地址,防止IP被封。 这是一个代理平台
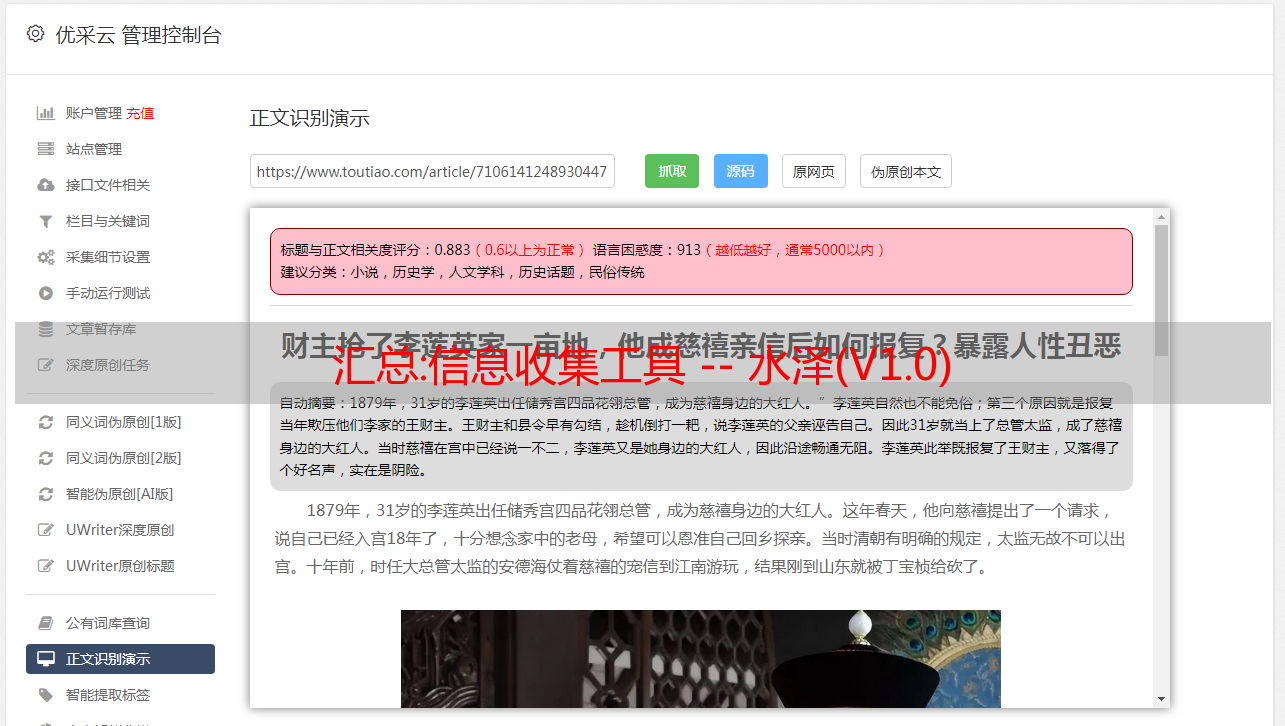
4.输入子域名,然后稍等片刻
4.查看结果
0x03 工程链接下载
汇总:「Python网络爬虫与数据采集」学习笔记,熬夜整理了一个月,最强
之所以有这么多小伙伴热衷于爬虫技术,是因为爬虫可以帮助我们做很多事情,比如搜索引擎、数据采集、广告过滤等。以Python为例,Python爬虫可以用来做数据分析,在数据捕获中发挥巨大作用。
但这并不意味着仅仅掌握一门Python语言就可以理解爬虫技术。 还有很多知识和规范需要学习,包括但不限于HTML知识、HTTP/HTTPS协议基础知识、正则表达式、数据库知识等。 ,常用的抓包工具的使用,爬虫框架的使用等等。而说到*敏*感*词*爬虫,还需要了解分布式的概念,消息队列,常用的数据结构和算法,缓存,甚至机器学习的应用。 许多技术支持大型系统。
零基础如何学习爬虫技术? 对于迷茫的初学者来说,爬虫技术初级学习阶段最重要的是理清学习路径,摸清学习方法。 只有这样,在良好的学习习惯的监督下,后期的系统学习才会事半功倍。
用Python写爬虫,首先需要懂Python,了解基本语法,知道函数、类以及dict中list、常用方法等常用数据结构的使用。 作为入门级的爬虫,了解HTTP协议的基本原理是很有必要的。 HTTP规范虽然写不成书,但是深入的内容以后可以慢慢看,理论与实践相结合,以后学习起来会更轻松。 easy。关于爬虫学习的具体步骤,我整理了一份给大家。
【Python网络爬虫与数据采集】学习笔记,送给想学习数据采集爬虫的朋友!
部分目录如下:
第 1 部分* 序言* 网络爬虫的基础知识
1 爬虫基本概述2
1.1 什么是爬虫
1.2 爬虫能做什么
1.3 爬行动物的分类
1.4.1 浏览网页的过程
1.4.2 爬虫的基本流程
1.5 爬虫与反爬虫
1.5.1 爬虫攻防
1.5.2 普通防爬和防爬
1.6 爬虫与机器人协议的合法性
1.6.1 机器人协议
1.6.2 查看网页的robots协议
1.7 Python爬虫相关库
2 Chrome 开发者工具 10
2.1 Chrome浏览器开发者工具简介
2.1.1 什么是浏览器开发者工具
2.1.2 浏览器开发者工具的基本使用
2.2 浏览器开发者工具面板说明
2.2.1 元素面板
2.2.2 网络面板(1)
2.2.3 网络面板(2)
的
第二部分* 第一章* 网络爬虫简介
内容部分截图如下:
内容注释很多,就不一一展示了。需要小伙伴的可以从下图获取

