分享文章:文章自动采集
优采云 发布时间: 2022-12-20 03:28分享文章:文章自动采集
文章自动采集,文章自动采集怎么做,文章自动采集发布
文章自动采集Discuz应用中心搜索“csdn123”神秘人物,下载采集插件成功后,开启自动采集并发布内容。
使用百度的discuz结构化数据插件。 可以有效提高收录效率,但主要还是要看你网站的优化效果。
时代互联为您解答
文章自动采集wordpress采集采集文章文章
全网热点话题:
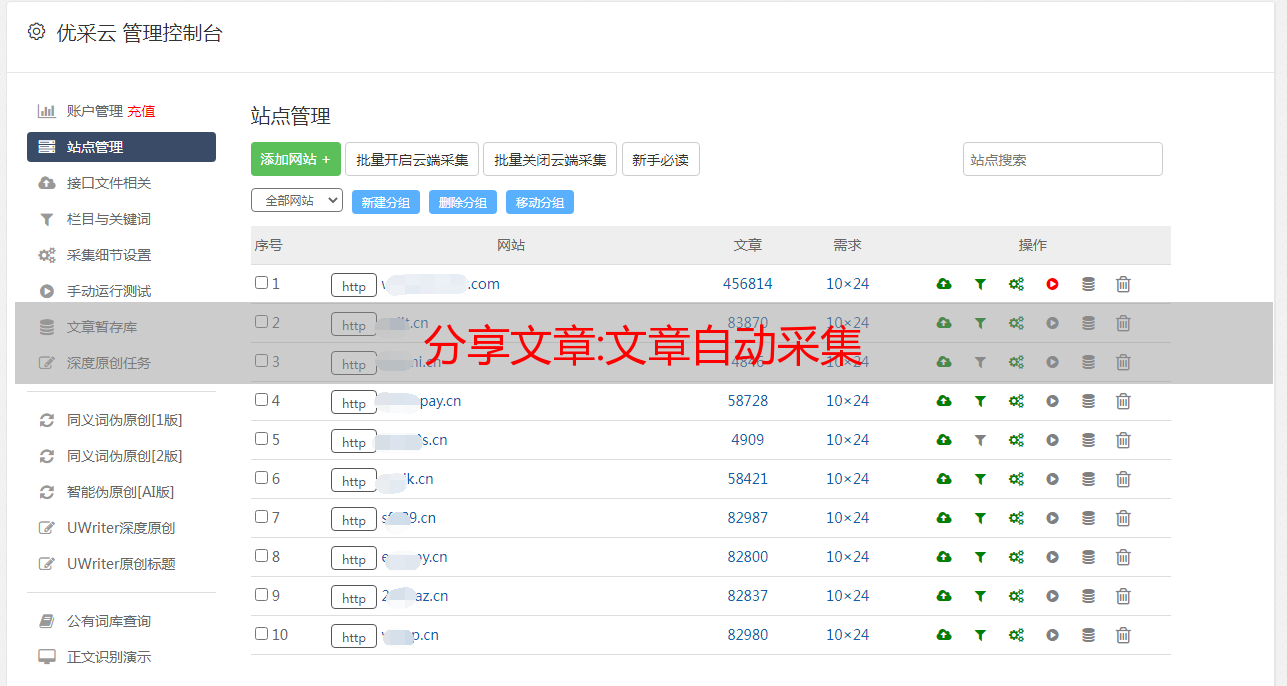
1楼文章自动采集软件:可自动采集大量关键词 3可设置项采集特定网站频道目录下的所有文章内容(如simple,贴吧百度),系统智能匹配,无需要写复杂
2楼文章自动采集采集器:文章内容自动采集和发布内容经历了数月的搏击,文章内容自动采集和文章内容自动发布已经上线,简单易用的操作面板,
3楼自动采集生成文章:在采集过程中,会自动生成一个目录。 微信采集完成后,将采集采集的内容存放在weixin目录下的微信公众号中。 文章标题目录内容为图片和txt文件。 下载地址:
4楼自动文章采集器:抖音采集软件在之前的文章中也提到过。 这个神器在很多项目中都有使用。 今天给大家详细介绍两款抖音软件! 两个软件都是同一个作者开发的
即将到来的假期:11 月的万圣节! 再忙也要善待自己!
文章自动采集!
直观:如何采集静态文章系统
结束功能
函数 getbody(url)
下一个错误恢复
设置检索 = createobject("microsoft.xmlhttp")
带检索
.open "get", url, false, "", ""
。发送
getbody = .responsebody
结束于
设置检索 = 无
结束功能
函数 bytetestobstr(正文,cset)
昏暗的对象流
设置 objstream = server.createobject("adodb.stream")
objstream.type = 1
objstream.mode=3
对象流.open
objstream.write 正文
objstream.position = 0
objstream.type = 2
objstream.charset = cset
bytesobstr = 对象流。 阅读文本
对象流。 关
设置 objstream = 无
结束功能
那我们先写个最简单的程序,一步步教你,(呵呵,废话太多*.*)
将以上代码命名为 get.asp
另一个页面代码称为 getfilename.asp。 代码如下:
呵呵,getfilename.asp就完成了,当然这是最简单的copy,我们还得一步步修改完善,
当你走到代码最远的地方时,你会看到一个与那个页面基本相同的页面。 当然有些图片是不能显示的!
然后我们分析这个页面,首页,右键,查看源代码找到这一行
知名度
当然,我们不要那么多,人气就够了,但是为了保险起见,还是要多点,
这是那些文件标题开始的地方,然后我们找到它们结束的地方,
页数
哦,我找到了这些代码,多多少少都可以,我们的代码需要一步步完善,
然后我们把getfilename.asp改成
再次运行此文件并查看,
你会发现少了很多东西,哦,简单多了,那么,我们再找规律,在同一个页面查看源码,
然后你会发现每个item都是由一个label组成的,这样就好办多了,
djmore=分裂(dj1,“”)
记住,仔细看,你会发现更多,
然后去掉前两个,就变成这样了
让我们循环
捆
response.write dj1 替换为
djmore=分裂(dj1,“”)
对于 i=1 到 ubound(djmore)-2
响应.write djmore(i)
下一个
这会将每一行分成以下内容
CSS语法手册(一)字体属性
2005-7-21
现在分析这段就容易多了,
让我们为 djmore(i) 数组中的项目编写代码,
l3=instr(djmore(i), "l4=instr(l3,djmore(i), """ target=""_blank""")
url=mid(djmore(i),l3,l4-l3)
响应。写 url &"
“
为了方便写在这里,
将以上段落替换为上一段
响应.write djmore(i)
在这里添加
是用来换行的,比较好看,然后你看url好像多了点东西,所以我们要做一些处理,把
url=mid(djmore(i),l3,l4-l3) 变成
url=mid(djmore(i),l3+len("哦,没问题,再次运行时会留下地址,
哦对了,这只是针对每个页面,如果你想要所有的,你只需要修改它

