解决方案:一种大数据智能采集处理方法和系统与流程
优采云 发布时间: 2022-12-19 18:52解决方案:一种大数据智能采集处理方法和系统与流程
本发明涉及信息技术领域,具体涉及一种大数据智能采集处理方法及系统。
背景技术:
随着大数据时代的到来,人们对数据的需求越来越强烈。 由于现实生活中数据来源千奇百怪,未经多次处理进入数据库的数据很可能会大大降低数据的整体可靠性和有效性。 使用此类数据进行后续数据使用非常高效。 低的。 为获取更有效的文本数据,尤其是供需、销售、交易、电子商务等数据处理,用户需要从海量信息中提取最及时、最有用的数据,同时,以相对较小的数量更新信息。 小数据。
数据清洗方法及装置2.9,获取经过粗分类的样本数据,将获取的样本数据作为第一数据集; 对样本数据进行分类,得到样本数据粗分类类别的权重,根据权重确定样本数据粗分类类别在所有类别中的排名位置; 根据样本数据粗分类类别在所有类别中的排名位置和第一数据集中样本数据的总数,得到综合评价结果; 当根据综合评价结果确定第一数据集需要清洗时,根据样本数据的粗分类类别在所有类别中的排名位置,删除指定数量的排名靠后的样本数据。
技术实现要素:
本发明的目的在于提供一种大数据智能采集处理方法及系统。 这种方法可以有效及时地对采集的数据进行处理,提取出信息量大的最及时有用的数据,同时保留信息量相对较少的数据,方便用户使用数据有效率的。
一种智能采集和处理大数据的方法,包括以下步骤:
s1。 设置第一数据库和第二数据库;
s2。 设置一台或多台网络智能机器人,实时智能捕捉公共信息,获取采集数据;
s3。 将采集的数据逐项与第一数据库中的数据进行比较,当采集到的数据中的数据a与第一数据库中的数据的相似度γ小于阈值α时,采集的数据中的数据Data a存储在第一数据库中; 否则,将采集的数据中的数据a存储到第二数据库中;
s4。 在将采集数据中的数据a存储到第二数据库中时,对采集数据中的数据a与第二数据库中的数据进行相似度γ计算;
s41。 当采集数据中的数据a与第二数据库中的一个或多个数据的相似度γ大于阈值β时,将采集数据中的数据a替换为第二数据库中的相同数据。 采集的数据中与数据a相似度γ最高的一条数据;
s42. 否则,直接将采集到的数据中的数据a存入第二数据库;
s5。 当超过时间阈值δ时,将第二个数据库中的数据存储到第一个数据库中,同时清除第二个数据库中的数据;
s6。 在将第二数据库中的数据存入第一数据库时,将第二数据库中的数据与第一数据库中相似度γ最高的一条或多条数据标记为同类数据。
作为一种优化,大数据智能采集处理方法采集的数据包括至少一个发布内容的数据标签。 实际应用过程中采集的数据至少收录出版商、出版内容、出版类型三个数据标签。
作为优化,在进行采集检索时,只检索第一数据库中的数据,对于第一数据库中的同类型数据,只显示最后添加的同类型数据项。 数据。
作为一种优化的大数据智能采集处理方法,相似度γ的计算方法为:γ=∑ρi*σi,(i=1..n)
n 是数据标签的数量;
ρi为第i个数据标签的权重值;
σi 是两条数据的第 i 个数据标签的标签相似度。
标签相似度的计算可以使用但不限于余弦相似度算法、简单共享词算法、编辑距离算法、jaccard距离算法等算法。
作为一种优化的大数据智能采集处理方法,如果第一数据库中有标记为同类型数据的数据φ={ψ1...ψn},则n≥2;
将ψn+1和φ中的任意一个或多个数据标记为同一类数据,则同一类数据的数据φ={ψ1…ψn+1}。
公共信息实时智能抓取作为一种优化的大数据智能采集处理方式,数据源包括网站公共信息和即时聊天工具。
作为一种优化,大数据智能采集处理方法,在实时智能采集公共信息时,通过关键词或算法对原创数据进行智能提取和分类,得到采集的具有多个数据标签的数据。
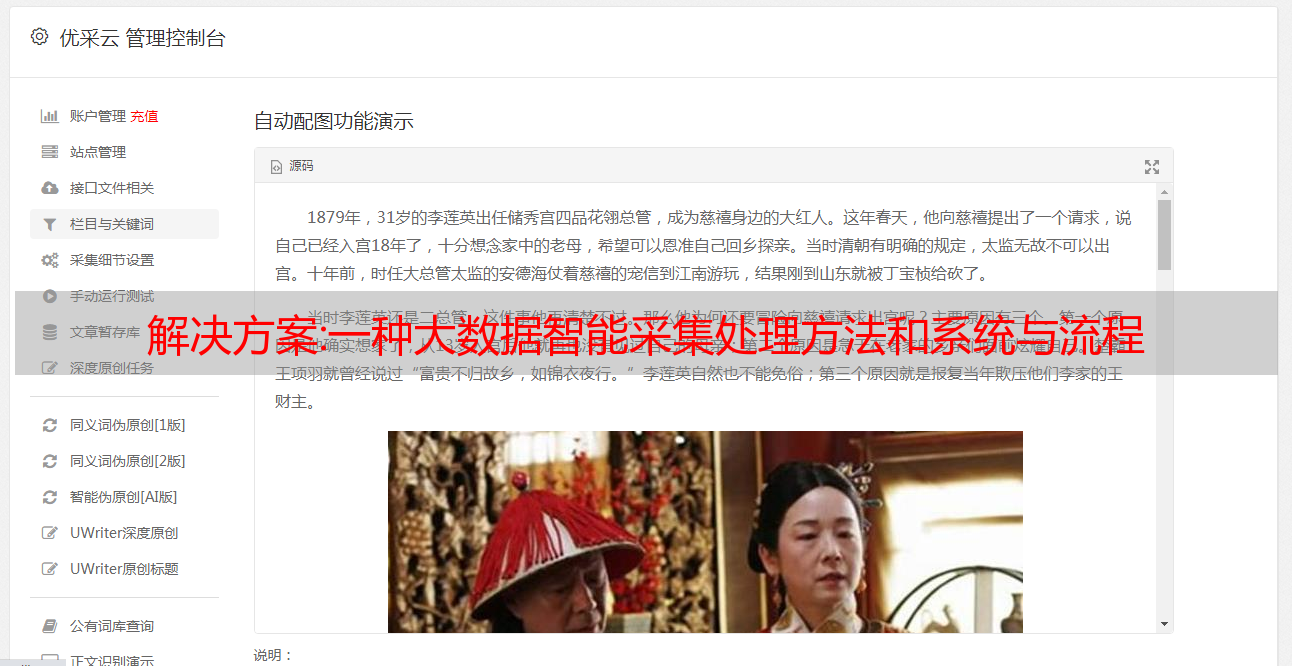
一种大数据智能采集处理系统,包括:
数据采集模块,用于实时智能采集公共信息,获取采集数据;
第一数据库用于最终存储数据,并提供对外检索和查询数据;
第二个数据库用于暂存数据;
数据处理模块,用于将采集的数据确定并存储到第一数据库或第二数据库中;
数据同步模块用于周期性地将第二数据库中的数据存入第一数据库中,同时清除第二数据库中的数据。
本发明的大数据智能采集处理方法及系统,采集的海量数据包括最新的高信息数据,同时具有大量接近重复的低信息数据; 通过本发明的方法,可以及时提取高信息量的大数据,同时保留低信息数据的数据,通过数据的错位更新,方便用户查看自己有用的信息查看数据时需要及时处理,提高使用效率。 适用于供需、交易、电子商务等大数据信息服务平台。
图纸说明
[0010] 下面结合附图和具体实施例对本发明进行详细说明;
图1为本发明实施例一的流程*敏*感*词*;
图2为本发明实施例二的结构*敏*感*词*;
无花果。 图3为本发明实施例三涉及的采集处理*敏*感*词*。
详细说明
以下给出的实施例旨在进一步说明本发明,但不能理解为对本发明保护范围的限制,本领域技术人员对本发明的一些非本质的改进和调整,仍属于本发明的保护范围本发明的内容按照本发明的范围。
实施例一: 如图1所示,大数据智能采集处理方法包括以下步骤:
s1。 设置第一数据库和第二数据库;
s2。 设置一台或多台网络智能机器人,实时智能捕捉网站和即时聊天工具的公开信息,获取采集数据。 采集的数据至少包括三个数据标签:出版商、内容、出版类型;
s3。 将采集的数据逐项与第一个数据库中的数据进行比较。 当采集数据中的某条数据a与第一数据库中的数据的相似度γ小于阈值α时,保存采集数据中的某条数据a。 进入第一个数据库; 否则,将采集的数据中的某条数据a存储到第二数据库中;
s4。 在将采集采集中的某条数据a与第二数据库中的数据进行相似度γ计算;
s41。 当采集数据中的某条数据a与第二数据库中的一条或多条数据的相似度γ大于阈值β时,将采集数据中的某条数据a替换为其中一条相同的数据在第二个数据库中采集的数据数据 a 具有最高的相似度 γ;
s42. 否则,将采集的数据中的某条数据a直接存储到第二数据库中;
s5。 设置时间阈值δ,当超过时间阈值δ时,将第二数据库中的数据存储到第一数据库中,同时清除第二数据库中的数据;
s6。 在将第二数据库中的数据存入第一数据库时,将第二数据库中的数据与第一数据库中相似度γ最高的一条或多条数据标记为同一类型数据。
s7. 在进行数据检索时,只检索第一个数据库中的数据,对于第一个数据库中的同类型数据,只显示同类型数据中最后添加的一条数据。
相似度γ的计算方法为:γ=∑ρi*σi,(i=1..n)
n 是数据标签的数量;
ρi为第i个数据标签的权重值;
σi 是两条数据的第 i 个数据标签的标签相似度。
标签相似度的计算可以使用但不限于余弦相似度算法、简单共享词算法、杰卡德距离算法、编辑距离算法等算法。
在第一个数据库中,有标记为同类型数据的数据φ={ψ1…ψn},n≥2;
将ψn+1和φ中的任意一个或多个数据标记为同一类数据,则同一类数据的数据φ={ψ1…ψn+1}。
实施例二:如图2所示,大数据智能采集处理系统包括:
数据采集模块,用于实时智能采集网站、即时聊天工具的公开信息,获取采集数据;
第一数据库用于最终存储数据,并提供对外检索和查询数据;
第二个数据库用于暂存数据;
数据处理模块,用于将采集的数据判断并存储到第一数据库或第二数据库中;
数据同步模块用于周期性地将第二数据库中的数据存入第一数据库中,同时清除第二数据库中的数据。
实施例三:大数据智能采集处理方法,包括以下步骤:
s1。 设置第一数据库和第二数据库;
s2。 设置多个网络智能机器人,如qq网络智能机器人; 实时智能采集qq群等即时聊天工具的公开信息,获取采集数据。 采集的数据收录三个数据标签:publisher、content、type;
s3。 将采集的数据与第一个数据库中的数据逐一进行比较。 当采集数据中的某条数据a与第一数据库中数据的相似度γ均小于阈值α=0.85时,则将采集数据中的某条数据a存储到第一数据库中数据库; 否则,将采集的数据中的一条数据a存储到第二数据库中;
s4。 在将采集采集中的某条数据a与第二数据库中的数据进行相似度γ计算;
s41。 当采集数据中的一条数据a与第二数据库中的一条或多条数据的相似度γ大于阈值β=0.85时,将采集数据中的一条数据a替换为相同的采集第二个数据库中相似度γ最高的一条数据a;
s42. 否则,将采集的数据中的某条数据a直接存储到第二数据库中;
s5。 设置每天凌晨将第二个数据库中的数据存入到第一个数据库中,同时清除第二个数据库中的数据;
s6。 在将第二数据库中的数据存入第一数据库时,将第二数据库中的数据与第一数据库中相似度γ最高的一条或多条数据标记为同一类型数据。
s7. 在进行数据检索时,只检索第一个数据库中的数据,对于第一个数据库中的同类型数据,只显示同类型数据中最后添加的一条数据。
相似度γ的计算方法为:γ=∑ρi*σi, (i=1, 2, 3)
1 发布者,2 发布内容,3 发布类型
ρ1=0.10, ρ2=0.65, ρ3=0.25,
ρi为第i个数据标签的权重值;
σi为两个数据的第i个数据标签的标签相似度,由编辑距离算法计算得到。
当第二个数据库为空时,当天采集的数据如图3所示,第一个数据库采集处理后的第二天凌晨之前的数据,第一个数据库凌晨之后的数据第二天如图3所示。
以上所述是本发明的具体实施方式及其所采用的技术原理。 若依据本发明的构思所作的改动未超出说明书及附图所涵盖的精神,则仍应属于本发明的保护范围。
解决方案:网页正文抽取中的网页编码字符集自动识别最佳方案 .
以往,易尔易科技()团队在做文本提取时,经常会遇到因为网页的字符集编码不同而提取出大量乱码的情况。下面就采集一些文章,供新手参考。专家不要笑。
第一篇文章来自《UniversalCharDet,一个比IE准确率更高的自动字符集检测类》,我在里面摘录了一段话:如何识别网页使用的是什么编码?
一种是网页或服务器直接向浏览器报告该页面使用什么编码。比如HTTP头的content-type属性,页面的charset属性。这个实现起来还是比较容易的,只要检测这些属性就可以知道使用的是什么编码了。
二是浏览器自动猜测。这类似于人工智能。比如有的网页没有写charset属性,那么当我们看到页面出现乱码的时候,我们会手动选择页面编码,如果发现是乱码,我们会重新修改,直到显示为普通的。
今天的文章要说的是第二种方法,就是利用程序自动猜测页面或文件使用的字符集。具体原理是根据统计字符特征分析,分析出哪些字符是最常见的字符。Mozilla 有一个特殊的文章“A composite approach to language/encoding detection”描述这项工作。嗯,具体的代码其实Mozilla已经用C++实现了,名字叫UniversalCharDet,但是我在网上搜了搜也没找到.NET的实现类库,只有Google Code有Java的翻译代码。没办法,自己翻译成C#代码。
C#实现的源代码:
PS1。对了,题主,为什么叫比IE更准确,是因为IE浏览器也有自己的字符集猜测功能,有人通过调用的接口实现了函数类库()猜测字符集IE,不过我试过了,这个接口的准确率不高,猜对成功的概率比UniversalCharDet低很多。
PS2。Nchardet 在互联网上广为流传。这是基于旧版mozilla的字符集猜测类的chardet的C#实现。准确率也比较低,和IE的界面成功率差不多。
PS3。参考
juniversalchardet:(java版代码在BIG5Prober和GB18030Prober类有bug,C#版已修正)
原理参考:
第二篇来自:《【小旋风开发日记】异步拉取html源码,自动识别网页代码,优化基础xpath智能提取引擎》
mozilla采用的编码识别模块,.netC#版本:NUniversalCharDet
使用 Mozilla.NUniversalCharDet;
公共静态字符串 DetectEncoding_Bytes(byte[] DetectBuff)
{
int nDetLen = 0;
UniversalDetector Det = new UniversalDetector(null);
//while (!Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
侦探 数据结束();
if (Det.GetDetectedCharset() != null)
{
返回 Det。GetDetectedCharset();
}
返回“utf-8”;
}

