解决方案:采集工具(采集站的生存之道,盘点常见的采集工具与软件!)
优采云 发布时间: 2022-12-18 21:30解决方案:采集工具(采集站的生存之道,盘点常见的采集工具与软件!)
采集工具(采集网站的生存之道,盘点常用采集工具和软件!),今天我们为大家整理了详细的采集工具(生存之道采集网站方法,常用采集工具软件盘点!)介绍,希望这篇文章对你有参考价值,一起关注采集工具吧( 采集网站如何生存,盘点常用采集工具软件!)。
早前很多SEOer喜欢用采集工具批量播放大量的文章,然后上传到自己的网站,没有任何版权。随着百度算法的调整,恒大采集网站在净网运营方面遭受重创。
Batman IT 将通过以下内容分享一些关于采集 网站的事情: 1. 采集 网站的生存之道,是时候和它说再见了吗?
答案基本上是肯定的。虽然百度目前还不能很好的对原创内容和采集内容进行排序,但雄掌的推出正试图扭转这种局面。这也是百度搜索的不断发展。核心战略面临挑战,但势在必行。
2、百度是否支持合理的“采集”?
显然,这里的“采集”可以理解为转载,基于搜索引擎的性质,试图快速找到最佳解决方案,百度支持合理的“采集”,值得注意的是必须带有原文链接,这样才不容易被识别为低质量内容。
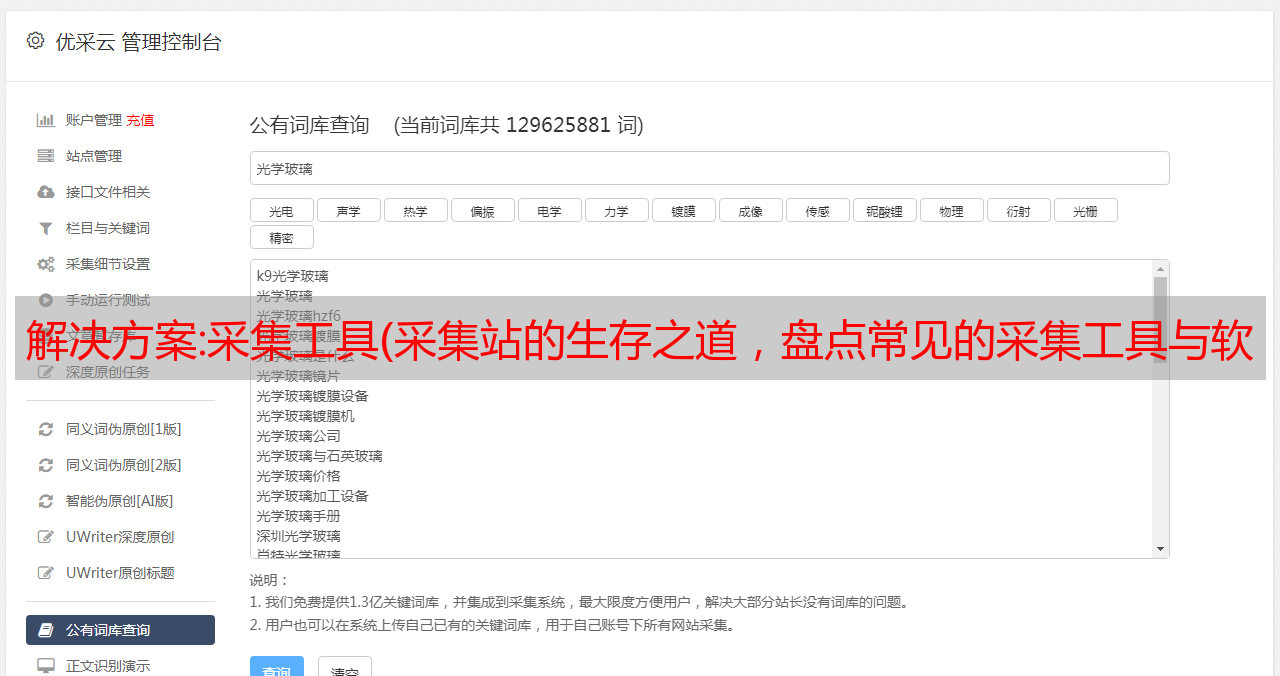
同时需要明确的是,一个网站的“文章采集”的数量需要控制在合理范围内,不能整个站点采集。
3.如果我站在采集上会受到惩罚吗?
不一定,要看情况,除了上面那个合理的采集例子,URL导航和网站目录,理论上都是采集站点,但是为什么不被处罚毛呢?
原因很简单。搜索引擎是一个开发平台。它将对真正满足用户需求的站点给予一些支持。同时,优质网站导航只推荐优质站点,代表一定的权威性,如:hao123。
因此,网站适度采集并转发部分内容不会被百度处罚。刚入行的个人站长不要担心这个问题。
4、用采集软件编辑稿件是否可行?
如果尝试做一个稿件清洗的分类采集工具,可以分为初级稿件清洗和高级稿件清洗:
① 初级稿件编辑:通常使用采集软件,如:博客搜索工具采集工具,采集特定关键词博文采集工具,然后多个articles 组合成一篇文章,有时上下文和逻辑结构不流畅,这是肯定不行的。
②进阶编辑:如果你长期关注某个行业网站,他们官网的行为格式都有特定的标签,比如:
标题:H1标签,副标题H2标签,副标题H3标签。
经验丰富的行业领导者通常会使用采集工具来遵循页面内容格式、玩法指南文章内容逻辑结构标题,然后根据这个框架进行创建和部分集成。
这种采集网站目前百度还难以识别,但显然是高级SEO的作弊行为。未来随着人工智能的介入,语义识别能力将得到极大提升。到时候,基本上都会被击中。
5、站长常用的采集工具有哪些?
对于一些SEO高手,基本都是自己写采集工具,但是对于小白来说,这里推荐一款采集软件:优采云采集,基本上这款软件可以满足大部分功能要求。
有人说我不懂这些复杂的采集规则。当然,网上有很多免费教程,你可以学习一下。一些博客群发工具还自带采集软件,效果也不错的。
总结:即使采集网站在短期内躲过了算法的攻击,但想想看,如果脱离了内容质量排名和流量,转化率也不会很高。即使附加了affiliate code,也不是长久之计。我建议你回归搜索的本质,才能不断提升。
解决方案:使用Cadvisor监控容器并展示数据
Clot 使用 Go 语言开发,使用 Linux cgroups 获取容器资源使用情况信息,cadvisor 不仅可以采集一台机器上所有正在运行的容器信息,还可以提供基本的查询接口和 http 接口,方便 Prometheus 等其他组件抓取数据。
本文介绍 Cadvisor 的安装、如何监控容器,最后展示数据。
首先,使用容器部署 Cadvisor 采集器
[root@prometheus ~]# docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
google/cadvisor:latest
#如果启动docker 错误,cadvisor无法启动容器管理器:inotify_add_watch /sys/fs/cgroup/cpuacct,cpu:nosuchfile
解决方法:
1. 将 cgroup 设置为读写文件,否则会报告:只读文件系统
2. 建立软连接
[root@prometheus ~]# mount -o remount,rw '/sys/fs/cgroup'
[root@prometheus ~]# ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
再次启动容器,没关系
2. 打开浏览器访问 Cadvisor 控制台
浏览器访问:8080
您可以查看某些容器的指标数据
在普罗米修斯服务器上配置废料
修改配置文件(添加底部job_name:“docker”)。
[root@prometheus to]# cat prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.31.250:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.31.30:9100','192.168.31.40:9100','192.168.31.41:9100','192.168.31.42:9100']
params:
<p>
collect[]:
- cpu
- meminfo
- diskstats
- job_name: 'docker'
static_configs:
- targets: ['192.168.31.250:8080']</p>
#改完后记得重新加载下普罗米修斯的配置文件
[root@prometheus ~]# ps -ef | grep prometheus | grep -v grep | awk '{print
解决方案:采集工具(采集站的生存之道,盘点常见的采集工具与软件!)
优采云 发布时间: 2022-12-18 21:30解决方案:采集工具(采集站的生存之道,盘点常见的采集工具与软件!)
采集工具(采集网站的生存之道,盘点常用采集工具和软件!),今天我们为大家整理了详细的采集工具(生存之道采集网站方法,常用采集工具软件盘点!)介绍,希望这篇文章对你有参考价值,一起关注采集工具吧( 采集网站如何生存,盘点常用采集工具软件!)。
早前很多SEOer喜欢用采集工具批量播放大量的文章,然后上传到自己的网站,没有任何版权。随着百度算法的调整,恒大采集网站在净网运营方面遭受重创。
Batman IT 将通过以下内容分享一些关于采集 网站的事情: 1. 采集 网站的生存之道,是时候和它说再见了吗?
答案基本上是肯定的。虽然百度目前还不能很好的对原创内容和采集内容进行排序,但雄掌的推出正试图扭转这种局面。这也是百度搜索的不断发展。核心战略面临挑战,但势在必行。
2、百度是否支持合理的“采集”?
显然,这里的“采集”可以理解为转载,基于搜索引擎的性质,试图快速找到最佳解决方案,百度支持合理的“采集”,值得注意的是必须带有原文链接,这样才不容易被识别为低质量内容。
同时需要明确的是,一个网站的“文章采集”的数量需要控制在合理范围内,不能整个站点采集。
3.如果我站在采集上会受到惩罚吗?
不一定,要看情况,除了上面那个合理的采集例子,URL导航和网站目录,理论上都是采集站点,但是为什么不被处罚毛呢?
原因很简单。搜索引擎是一个开发平台。它将对真正满足用户需求的站点给予一些支持。同时,优质网站导航只推荐优质站点,代表一定的权威性,如:hao123。
因此,网站适度采集并转发部分内容不会被百度处罚。刚入行的个人站长不要担心这个问题。
4、用采集软件编辑稿件是否可行?
如果尝试做一个稿件清洗的分类采集工具,可以分为初级稿件清洗和高级稿件清洗:
① 初级稿件编辑:通常使用采集软件,如:博客搜索工具采集工具,采集特定关键词博文采集工具,然后多个articles 组合成一篇文章,有时上下文和逻辑结构不流畅,这是肯定不行的。
②进阶编辑:如果你长期关注某个行业网站,他们官网的行为格式都有特定的标签,比如:
标题:H1标签,副标题H2标签,副标题H3标签。
经验丰富的行业领导者通常会使用采集工具来遵循页面内容格式、玩法指南文章内容逻辑结构标题,然后根据这个框架进行创建和部分集成。
这种采集网站目前百度还难以识别,但显然是高级SEO的作弊行为。未来随着人工智能的介入,语义识别能力将得到极大提升。到时候,基本上都会被击中。
5、站长常用的采集工具有哪些?
对于一些SEO高手,基本都是自己写采集工具,但是对于小白来说,这里推荐一款采集软件:优采云采集,基本上这款软件可以满足大部分功能要求。
有人说我不懂这些复杂的采集规则。当然,网上有很多免费教程,你可以学习一下。一些博客群发工具还自带采集软件,效果也不错的。
总结:即使采集网站在短期内躲过了算法的攻击,但想想看,如果脱离了内容质量排名和流量,转化率也不会很高。即使附加了affiliate code,也不是长久之计。我建议你回归搜索的本质,才能不断提升。
解决方案:使用Cadvisor监控容器并展示数据
Clot 使用 Go 语言开发,使用 Linux cgroups 获取容器资源使用情况信息,cadvisor 不仅可以采集一台机器上所有正在运行的容器信息,还可以提供基本的查询接口和 http 接口,方便 Prometheus 等其他组件抓取数据。
本文介绍 Cadvisor 的安装、如何监控容器,最后展示数据。
首先,使用容器部署 Cadvisor 采集器
[root@prometheus ~]# docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
google/cadvisor:latest
#如果启动docker 错误,cadvisor无法启动容器管理器:inotify_add_watch /sys/fs/cgroup/cpuacct,cpu:nosuchfile
解决方法:
1. 将 cgroup 设置为读写文件,否则会报告:只读文件系统
2. 建立软连接
[root@prometheus ~]# mount -o remount,rw '/sys/fs/cgroup'
[root@prometheus ~]# ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
再次启动容器,没关系
2. 打开浏览器访问 Cadvisor 控制台
浏览器访问:8080
您可以查看某些容器的指标数据
在普罗米修斯服务器上配置废料
修改配置文件(添加底部job_name:“docker”)。
[root@prometheus to]# cat prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.31.250:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.31.30:9100','192.168.31.40:9100','192.168.31.41:9100','192.168.31.42:9100']
params:
<p>
collect[]:
- cpu
- meminfo
- diskstats
- job_name: 'docker'
static_configs:
- targets: ['192.168.31.250:8080']</p>
#改完后记得重新加载下普罗米修斯的配置文件
[root@prometheus ~]# ps -ef | grep prometheus | grep -v grep | awk '{print $2}' | xargs kill -HUP
视图
普罗米修斯控制台上的目标
您可以看到 Cadvisor 采集器已添加到目标列表中
5. 在格拉法纳上显示容器数据
在此处使用 Grafana 仪表板网站上的模板
登录格拉法纳, :3000
导入 ID 为 193 的导入模板
您可以自定义监控名称并选择数据源为 Prometheus
最终效果
本文仅涉及使用 Cadvisor 监控容器和展示数据,不写触发器的配置告警,稍后会更新。
0 个评论
官方客服QQ群


在
线
客
服
视图
普罗米修斯控制台上的目标
您可以看到 Cadvisor 采集器已添加到目标列表中
5. 在格拉法纳上显示容器数据
在此处使用 Grafana 仪表板网站上的模板
登录格拉法纳, :3000
导入 ID 为 193 的导入模板
您可以自定义监控名称并选择数据源为 Prometheus
最终效果
本文仅涉及使用 Cadvisor 监控容器和展示数据,不写触发器的配置告警,稍后会更新。