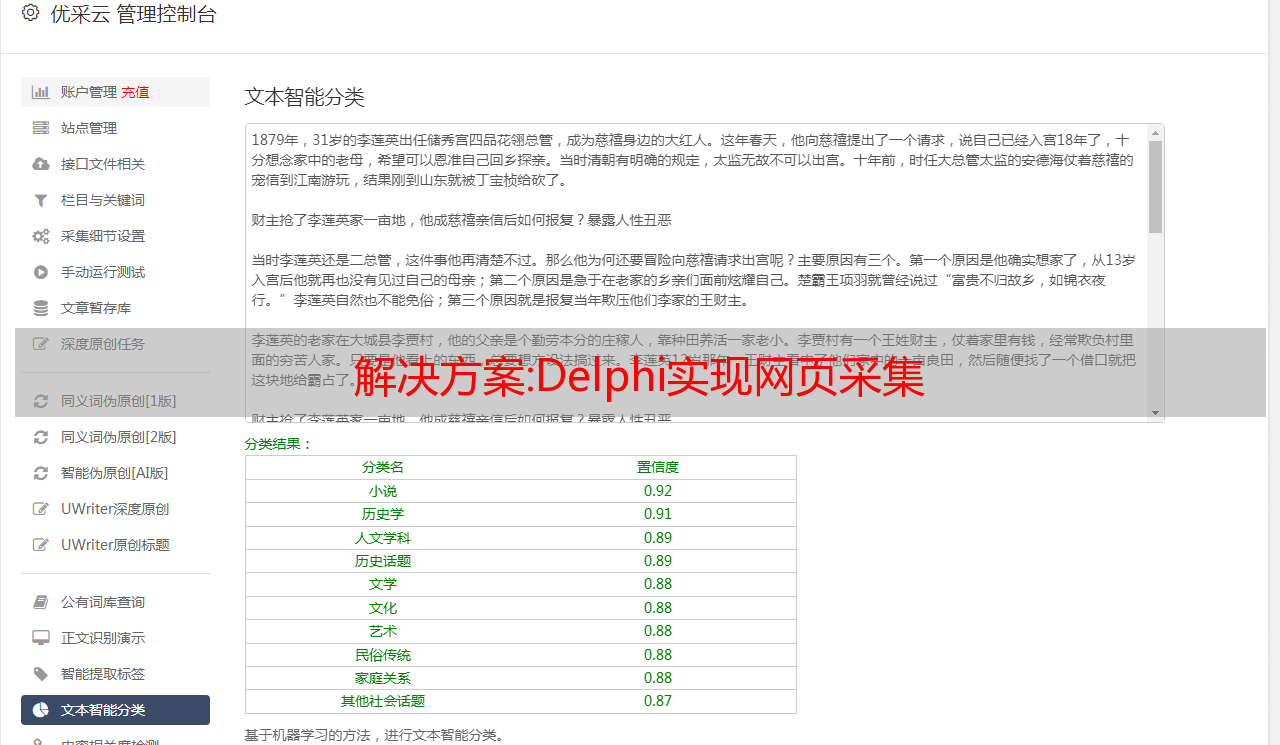
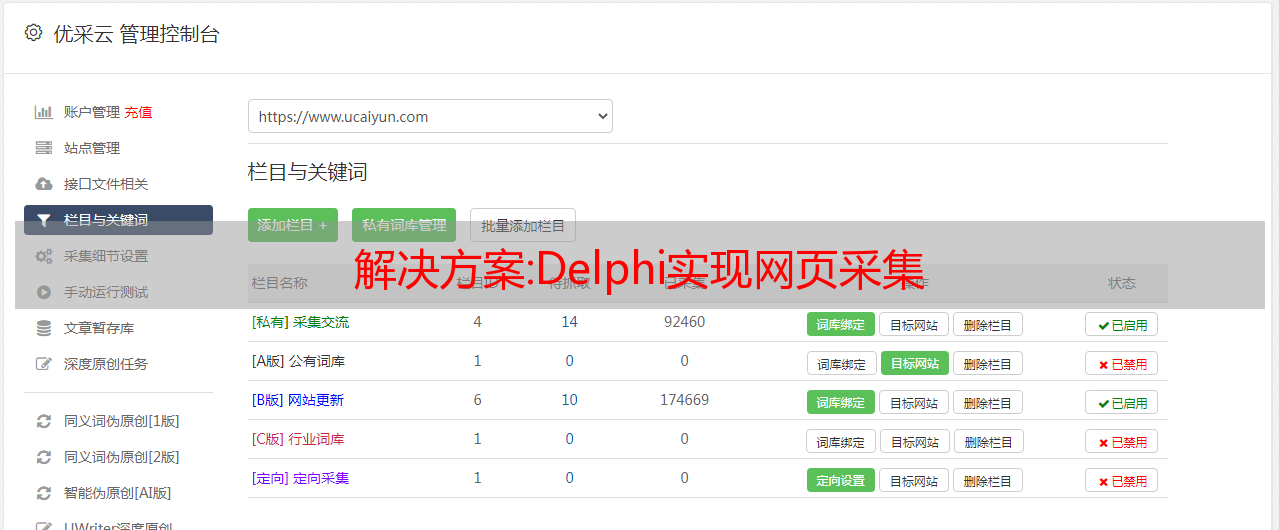
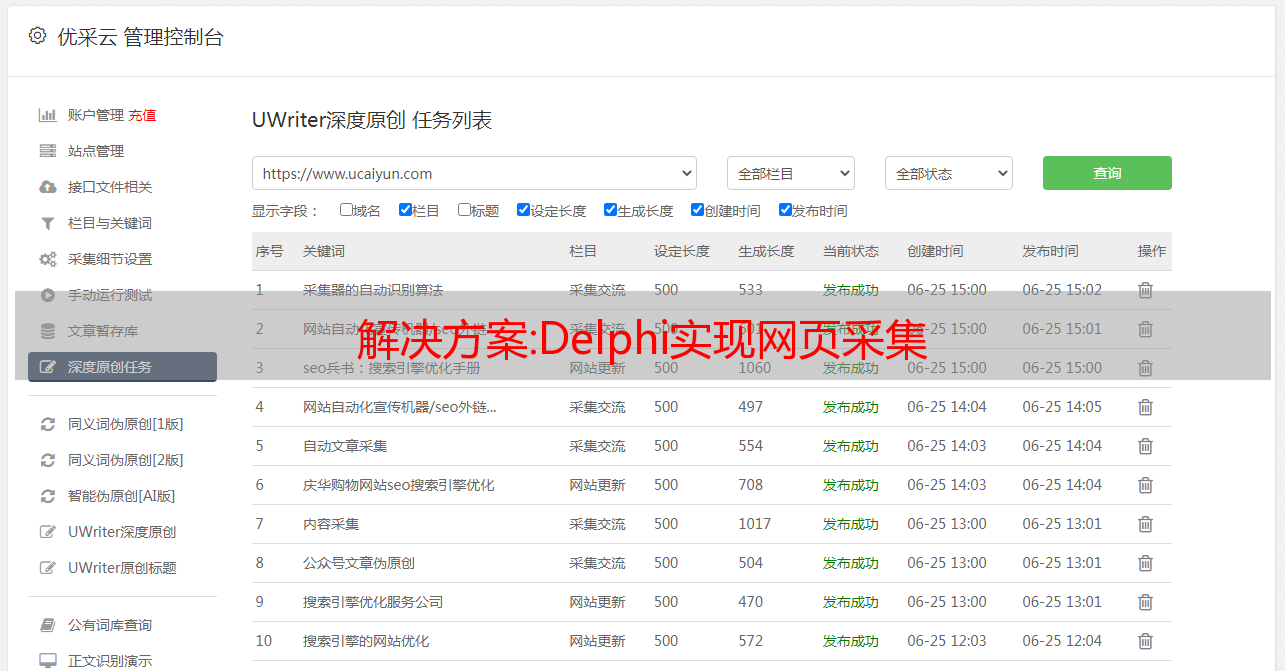
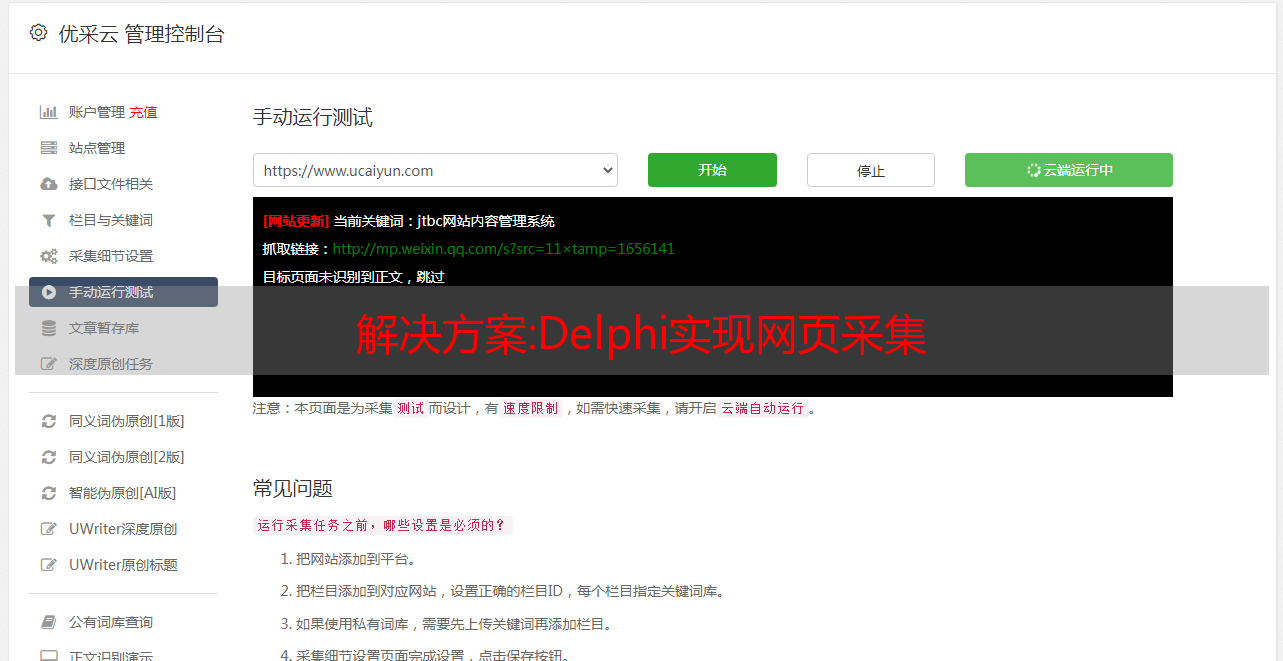
解决方案:Delphi实现网页采集
优采云 发布时间: 2022-12-17 15:44解决方案:Delphi实现网页采集
提到网页采集,人们通常认为他们上网窃取数据,然后将采集到的数据发布到自己的网站上。其实你也可以将采集获取的数据作为公司的参考,或者将采集到的数据与自己公司的业务进行对比等等。
现在的网页采集大多是3P代码(3P表示ASP、PHP、JSP)。东一科技BBS中最具代表性的新闻采集系统和网上流传的新浪新闻采集系统都是用的ASP程序,但是理论上速度不是很好. 如果我尝试使用其他软件的多线程 采集 会更快吗?答案是肯定的。DELPHI、VC、VB、JB都可以,但是PB好像比较难做。下面用DELPHI解释采集网页数据。
1. 简单新闻 采集
新闻 采集 最简单,只需标明标题、副标题、作者、来源、日期、新闻主题和页码即可。在采集之前,必须获取网页内容,所以在DELPHI中添加idHTTP控件(在indy Clients面板中),然后使用idHTTP1.GET方法获取网页内容,语句为如下:
函数 Get(AURL: 字符串): 字符串; 超载;
AURL参数为字符串类型,指定一个URL地址字符串。函数返回也是字符串类型,返回网页的HTML源文件。例如,我们可以这样称呼它:
tmpStr:= idHTTP1。得到('');
调用成功后,将网易首页的代码存入tmpstr变量中。
接下来说说数据拦截。在这里,我定义了这样一个函数:
函数 TForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
变量
in_star, in_end: 整数;
开始
in_star:=AnsiPos(strbegin,strsource)+length(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,代表HTML源文件。
StrBegin:字符串类型,表示截取的开始标志。
StrEnd:字符串,表示截取结束的标志。
该函数在字符串 StrSource 中返回一段从 StrSource 到 StrBegin 的文本。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
函数中使用的AnsiPos和copy是系统定义的,可以在delphi的帮助文件中找到相关说明。我将在这里简要说明:
function AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串 strsource 中从 in_sta(整数数据)到 in_end-in_star(整数数据)的字符串。
有了以上功能,我们就可以通过设置各种标签来拦截想要的文章内容了。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,我们必须设置它的开始和结束标签。比如获取网页的文章的标题,就必须提前查看网页的代码,查看文章标题前后的一些特征码,并使用这些特征码拦截 文章 的标题。
让我们在实践中演示一下,假设 采集 的 文章 地址是
代码是:
文章标题
作者
资源
这是 文章 内容文本。
在第一步中,我们使用 StrSource:= idHTTP1.Get(' '); 将网页代码保存在 strsource 变量中。
然后定义strTitle、strAuthor、strCopyFrom、strContent:
strTitle:= GetStr(StrSource,'
','
'):
strAuthor:= GetStr(StrSource,'
','
'):
strCopyFrom:= GetStr(StrSource,'
','
'):
strContent:= GetStr(StrSource,'
,'
'):
这样,文章的标题、副标题、作者、出处、日期、内容、分页就可以分别存储在上述变量中。
第二步是使用循环方法打开下一页,获取内容,并将其添加到 strContent 变量中。
StrSource:= idHTTP1。Get('new_ne.asp');
strContent:= strContent +GetStr(StrSource,'
,'
'):
然后判断是否有下一页,如果有,则获取下一页的内容。
这样就完成了一个简单的拦截过程。从上面的程序代码可以看出,我们使用的拦截方式是找到拦截内容的头部和尾部。如果有多个头和尾怎么办?好像没有办法,只能找到第一个,所以在找之前,先验证截取的内容是否只有前后两部分。
以上内容未经程序验证,仅供参考。如果觉得有用,可以试试。
解决方案:排名和用户双收的关键词布局
我们以前都是做关键词布局,特意在导航栏和模块的title前加上main 关键词来提高关键词的密度和排名,完全没有考虑用户体验. 随着搜索引擎的智能化,这种优化方式已经落伍了。但还是看到了很多这样的网站。科学地进行 SEO 从四个基本优化开始。
1. 重新发现关键词密度
关键词 密度是 关键词seo 在 文章 中出现的次数。
只是为了优化而优化,可以在第一段插入两三个关键词,并加粗,后面的段落可以适当加上关键词,不用管的连贯性文章 、可读性、可重复性等。
为了增加用户体验,把重点放在文章的内容上,不要刻意添加关键词,写文章的时候,可以围绕一个关键词的主题开始写,在标题中添加 关键词 或 关键词 变体、缩写等就可以了。书面的文章应该是流畅的、可读的和实用的。对比一下就知道哪个更好了。前者,由于内容的可读性和重复性,即使开始获得稍微好一点的排名,因为内容不适合传播,点击转发的人也会变少。根据 click 原则,这样的排名会下降。
文章 流畅、实用、可读性强,传播性更好。就算一开始排名不好,点击的人多了,排名自然就上去了。这个假设是基于搜索引擎早期的关键词识别技术,更何况现在的搜索引擎早就认识到了关键词堆叠的不良行为。
2.适度堆叠关键词
现在很多cms管理系统会自动提取文章的开头作为文章的概览、指南和总结。而搜索引擎蜘蛛最先阅读的内容也是文章开头的,如果在文章前面堆一些关键词,就有可能骗过百度。但如果你关键词效果不好,cms会自动抽取另一段,重复开头,重复关键词。这是作弊。
为用户优化内容,一般情况下,遵循关键词自然出现的原则,即关键词恰好出现在文章中,能够引起读者的共鸣。大多数 文章 在末尾总结了整个 文章,因此 文章 末尾的 关键词 也是使 文章 更相关的一种方式。
只是为了加关键词而写的结尾,肯定很难兼顾总结的任务。只为总结而写的结尾,自然会将文章的重点和要点写在最后。不送出去,一不小心就会插柳柳成荫。”这是实话。
3. 永远不要盲目依赖文章伪原创软件
现在很多伪原创软件都用所谓的关键词来代替伪原创文章,其实没什么用。没有官方网站会原创用这个方法来做文章。关键词替换最大的缺点在于文章的可读性。很多词被替换后,就无法流利地阅读了。这样的文章,就算是收录,别人看了我肯定不会看第二遍,当然也不会转载。
如果我们在写文章的时候把读者放在心上,那么关键词中就会出现各种形式的关键词、别名、常用名等等,其实就是关键词的不同的表达方式,因为用得自然,自然会被读者认可,从而获得点击或转载。把读者放在心上,换位思考,为他们写出实用的文章,自然就能获得好的排名、转载和传播。
4、网站定位从关键词组合开始
许多SEOer都有这样的经历。在撰写文章 文章 时,他们希望插入尽可能多的 关键词。就这样,他们总以为这么多词组合起来,所有的词都能得到更好的排名,其实是一种错觉。当一个页面的权重为5的时候,如果把它分成5个词,每个词的权重就会小于5。如果master做一个词,那么他就会接近5,所以这会导致权重分散,以致达不到想要的排名。
当网站的权重比较低的时候,做好一个词往往比多个词要容易的多。一个词起来了,再做其他词就容易多了。关键词不要太贪心,做大做全,以用户为中心,为用户写文章,而不是为关键词写文章。
从细节做SEO,不要为了优化而优化。记住用户就是上帝,排名优化和用户优化才是科学优化之道!
-结束-

