解决方案:大数据智能营销系统,2023的大数据获客软件
优采云 发布时间: 2022-12-16 21:16解决方案:大数据智能营销系统,2023的大数据获客软件
近年来,随着互联网时代的变化,传统行业获取客户信息的方式单一,数据不准确,企业转化率低。2015年,通过对客户需求的不断探索,以及其在网络营销服务方面的长期积累,我们开发了一套能够帮助企业快速占领市场,获取更多客户的网络营销系统。
详情请咨询:(同微信号)
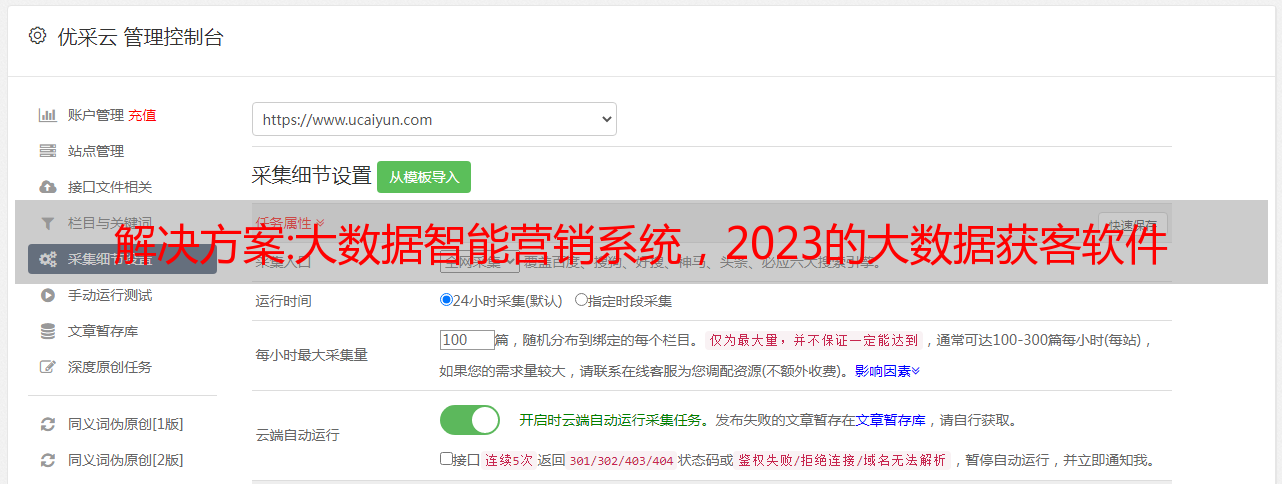
1、*敏*感*词*采集,系统接入全网200多个网站平台,操作相对简单。你只需要设置地区和行业关键词,它就可以帮你采集到你的对口源信息
2、微信自动营销,采集收到的客户信息,系统可以自动为您加微信,群发消息,自动爆粉,快速积累客户
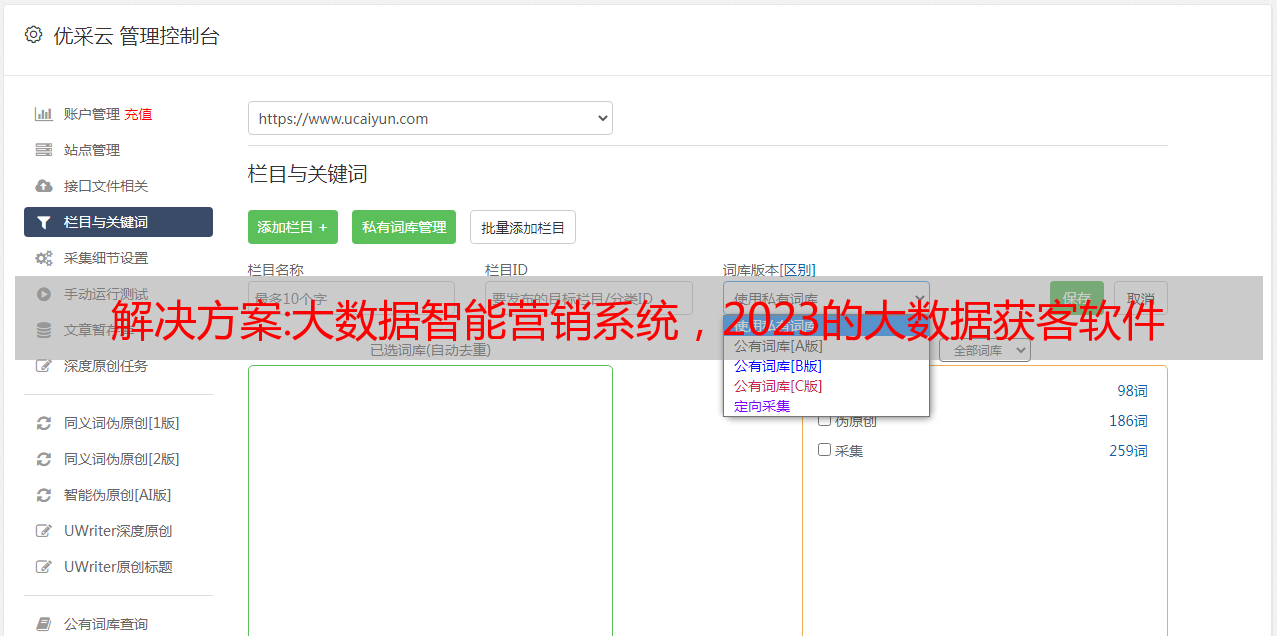
3、短信营销,系统可一键给采集客户手机号,群发短信,闪屏短信(客户必读),一键群发邮件
4.QQ营销,系统可以帮你采集进各个QQ群,自动加群,发群消息,不加群提取群成员,自动通过群成员QQ加微信
解决方案:基于智能分析的恶意软件检测研究进展和挑战
概括
在处理恶意软件变种和新型恶意软件时,传统的基于特征匹配等方法的恶意软件检测方法往往存在较高的误报率和漏报率。随着人工智能技术的发展,人工智能在恶意软件检测领域的应用具有广阔的发展空间。首先从数据集构建、安全特征提取、安全特征处理、分类器选择、模型验证和性能评估五个方面总结了Windows平台下恶意软件智能分析的相关工作;其次,详细阐述了智能分析在恶意软件检测中面临的挑战和问题;最后,根据面临的挑战,指出了未来可能的研究方向。
内容目录
1 数据集构建 1.1 公开数据集 1.2 自建数据集 1.3 总结 2 安全特征提取 2.1 静态分析特征 2.1.1 字节序列特征 2.1.2 可读字符串 2.1.3 PE文件信息 2.1.4 信息熵 2.1.5 DDL相关信息 2.2 动态分析特征 2.2.1 系统运行状态信息 2.2.2 系统运行信息 2.2.3 网络行为特征 2.3 静态和动态混合分析特征 2.3.1 操作代码特征 2.3.2 API系统调用特征 2.4 图像分析特征 2.5 小结 3 安全特征处理 3.1 信息增益法 3.2 PCA 方法 3.3 使用分类器处理特征 3.4 嵌入技术 3.5 小结 4 分类器选择 4.1 机器学习分类器 4.1.1 K 最近邻算法 4.1.2 K-means 算法 4.1.3 SVM4 . 1.4 决策树4。2 深度学习分类器4.2.1 CNN4.2.2 递归神经网络4.2.3 BP 神经网络4.2.4 图卷积神经网络4.3 集成学习分类器4.3.1 随机森林4.3.2 GBDT、XGBoost 和LightGBM4。4 小结 5 模型验证与性能评估 5.1 模型验证 5.2 性能评估 5.3 小结 6 智能分析面临的挑战 6.1 数据样本相关问题 6.1.1 数据样本现状 6.1.2 样本采集相关问题 6.1.3 数据样本标注问题 6.1.4 新威胁样本问题 6.2 分析方法相关问题 6.2.1 静态分析的局限性 6.2.2 动态分析的局限性 6.2.3 图像分析的局限性 6.3 信息丢失问题 6.4 可解释差异问题 6.5 对抗样本攻击问题 6.6总结 7 总结与展望
随着信息技术的发展,恶意软件攻击的不断出现使得网络安全形势日益严峻。恶意软件的数量和种类每年都在呈爆发式增长,对个人财产安全、企业数据安全乃至国家网络安全造成极大危害。例如,2017年WannaCry勒索病毒席卷全球,感染了150多个国家和地区的30万用户和机器,造成的经济损失高达80亿美元。这些恶意软件通过使用伪装技术(例如打包、混淆、反沙盒和对抗性样本攻击)来抵抗检测。因此,如何有效检测恶意软件一直是网络安全领域的重要研究课题之一。传统的恶意软件检测技术使用特征匹配来检测恶意软件。此类检测方法可以有效检测已知恶意软件,但无法检测未知恶意软件,尤其是恶意软件及其变种。在种类和物种爆发式增长的情况下,这类技术必然会导致检测效率的下降。随着人工智能技术的日益发展,研究人员将其应用于恶意软件检测领域。本文将借助人工智能进行恶意软件检测的技术统称为恶意软件智能分析技术。恶意软件智能分析技术可以有效缓解伪装技术带来的威胁,对恶意软件加壳、混淆、防沙盒和防样本攻击,有效降低人工分析人力成本。因此,恶意软件智能分析技术的研究具有很高的应用价值。本文总结和概括了智能分析技术在恶意软件检测中的应用成果,形成了如图1所示的恶意软件智能分析框架。该框架包括5个主要步骤:数据集构建、安全特征提取、安全特征处理、分类器选择、模型验证和性能评估。根据这五个步骤,本文对恶意软件的智能分析技术一一阐述。最后,从不同层面分析了人工智能技术在恶意软件检测中的应用面临的一些挑战,并提出了未来的研究方向和发展趋势。另外,结合作者的研究领域,本文仅介绍Windows系统的恶意软件智能分析技术。
图1 恶意软件智能分析框架
✦+
+
1 数据集构建
1.1 公共数据集一些大型组织和公司开源他们的数据集,即建立一些公共数据集。但是,出于安全、隐私和版权方面的考虑,必须对公共数据集进行相应处理。例如,数据集仅收录从可移植可执行 (PE) 文件中提取的特征向量、分类标签和函数调用序列。以下是一些具有许多应用程序的公开数据集。EMBER数据集是EndGame在2018年发布的一个*敏*感*词*公开数据集。该数据集包括来自EMBER2017的110万个样本和来自EMBER2018的100万个样本。这两个阶段的样本由恶意样本、良性样本和未知样本按一定比例组成,样本文件由从PE文件中提取的特征向量及其标签组成。BIG2015数据集由微软公司构建并发布。出于安全考虑,BIG2015数据集的头文件全部去掉。样本数据由 10 868 个恶意标记软件和 10 873 个未标记恶意软件组成,来自 9 个不同的恶意软件家族。SoReL-20M 数据集由网络安全公司 Sophos 和 ReversingLabs 于 2020 年 12 月 14 日联合发布。该数据集收录 2000 万个 Windows PE 文件的元数据、标签和特征。该数据集是目前研究恶意软件检测的最大数据集。kaggle平台恶意软件分类数据集由微软于2015年发布,该数据集收录近500GB的样本数据,分为9个恶意软件家族,共有10868个恶意软件样本。但是,出于安全原因,PE 头文件已被删除。阿里安全云于2018年发起了恶意软件检测挑战赛,并发布了比赛使用的数据集。该数据集中的数据为经过脱敏处理的 Windows 二进制可执行程序,总数据量为 6 亿条。1.2 自建数据集 对于一些特殊的网络环境和工作需求,如果需要跟踪最新样本的变化趋势,往往需要自己采集恶意样本,一般会部署蜜罐进行诱捕。对于蜜罐系统的部署方法,网上有详细的操作方法,本文不再介绍相关方法。1. 3 小结 构建高质量的恶意样本数据集是保证智能分析模型良好性能的关键环节。一般来说,数据量、家庭类型、公共数据集的数据质量平衡分布优于自建数据集。但是,出于一些特殊的研究和工作目的,往往需要自行采集构建恶意软件样本,这也是实际工作应用场景中恶意软件数据样本的主要来源。
✦+
+
2 安全特征提取
2.1 静态分析特征静态分析特征是指在不运行待测恶意软件的情况下提取的安全特征。本节将从以下几个方面介绍静态分析的特点。2.1.1 字节序列的特点 字节序列是程序的字节级组成部分,每个字节本身都收录一定的信息。因此,恶意软件的字节序列特征提取可以作为恶意软件的一部分。静态特征。这个静态特征就是按照一定的规则对被测程序进行字节级的切分。为被测程序提取字节序列的最常见方法是使用 n-gram 模型。n-gram模型将待测程序按照大小为n的滑动窗口进行划分,得到一系列长度为n的字节序列。提取方法如图2所示。2000年,Schultz等人。首先使用n-gram模型提取恶意软件的字节序列特征,并结合相关的机器学习算法对基于Windows平台的恶意软件进行检测。该团队在不同的分类器中训练提取的字节序列特征,并将其与传统的基于特征的方法进行比较。最后,实验表明,该方法对恶意软件的检测效率提高了一倍。2017年,孙博文等人利用恶意软件的字节序列特征、操作码序列特征和PE头信息进行静态特征融合,融合后的特征输入到集成学习分类器中,最终获得了良好的分类泛化能力。拉夫等人。没有对整个程序字节序列进行切分,直接作为分类器的输入。他们利用词嵌入技术将整个程序字节转化为定长向量,并以此构建字节之间的语义关系,进一步利用卷积神经网络提取的特征进行恶意软件检测。图23-gram 字节序列 2.1.2 可读字符串 对于一些恶意软件,其程序代码中可能存在一些不变的可读字符串。比如字符串“ 图23-gram 字节序列 2.1.2 可读字符串 对于一些恶意软件,其程序代码中可能存在一些不变的可读字符串。比如字符串“ 图23-gram 字节序列 2.1.2 可读字符串 对于一些恶意软件,其程序代码中可能存在一些不变的可读字符串。比如字符串“

