解决方案:如何使用爬虫工具采集数据
优采云 发布时间: 2022-12-12 16:23解决方案:如何使用爬虫工具采集数据
网络爬虫是一种根据一定规则自动从万维网上抓取数据的脚本。根据一定的规则,意味着爬虫程序需要解析网页的dom结构,根据dom结构爬取感兴趣的数据。
(图1)
这是一个网页源代码的dom结构。我们需要逐级指定抓取的标签,如下图所示:
(图二)
图2是java程序使用webmagic框架开发的爬虫程序。这段代码是抓取对应的label,对应图1,运行后结果如下:
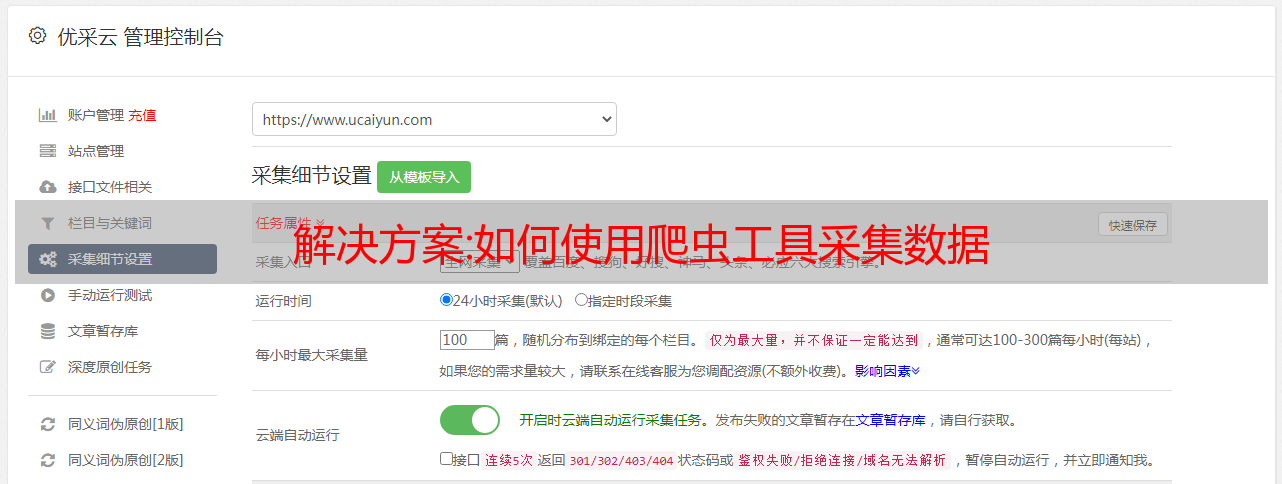
当然,以上是专业程序员的做法,但有助于我们理解爬虫工具的工作原理。非专业人士可以使用爬虫工具自行爬取数据。
1、首先输入你要抓取的网站的网址,点击“开始采集”。
2、工具自动识别当前页为多页数据,默认翻页采集。我们只需要点击“Generate 采集 Settings”。
3、点击采集的详细链接,这里我们要采集这个网站的所有化工产品的信息,所以点击中文名称栏的某个链接,然后点击右侧“点击链接”,如下图
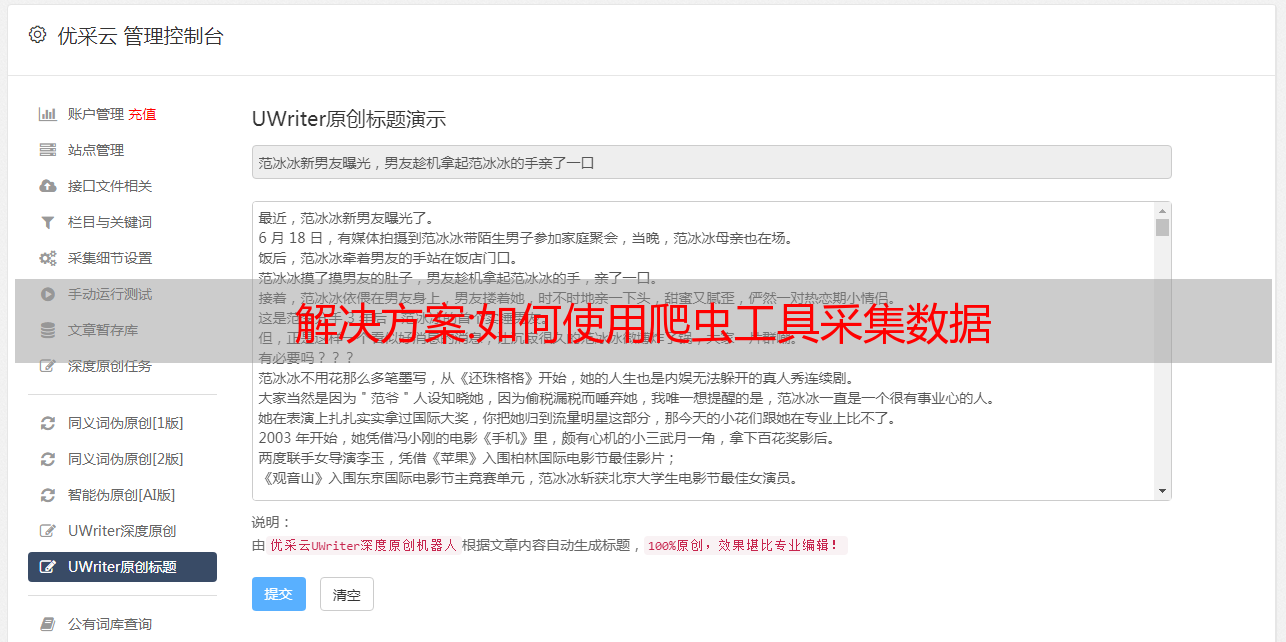
4、爬虫工具进入详细链接页面。这个页面的数据就是我们要爬取的。点击“Generate 采集 Settings”生成爬虫工具最后的爬虫过程。如下图所示,爬虫工具会按照这个流程给我们采集数据,直到数据采集完成。
5、点击“采集”按钮,爬虫工具将正式开始运行。爬虫工具的工作原理如下:
列表中的数据由爬虫采集获取。我们还可以处理采集的数据。您可以选择将其导入到 Excel 文档中或直接将其导入到数据库中。这是后续的分析数据。用于进一步处理所需的数据。有了这些基础数据,就可以对数据进行分析,得到一些业务依据,作为业务决策的支撑。比如沃尔玛通过他们的大数据发现,买尿布的爸爸们喜欢一起买啤酒,于是他们把尿布和啤酒放在一起,啤酒的销量就大大增加了。这就是大数据的价值。
这次提到的爬虫工具的使用只是一个比较基础的应用,希望对大家有所帮助。科技漫步者带你走遍科技,后续会持续更新相关知识,欢迎关注。
汇总:Python网络数据采集_python获取网络数据
Python网络数据采集_python获取Python网络数据的网络数据
笔记采集即原创即采集清晰的思想,一池火焰,一次思想觉醒,方登的网络数据采集,无非是编写一个自动化程序,从网络服务器请求数据,然后解析数据,提取所需信息通常都有可用的API。API 将比编写网络爬虫来获取数据更方便。第1部分创建爬虫 第1章启动网络爬虫 一旦你开始采集网络数据,你就会感受到浏览器为我们所做的一切......
大家好,我是一个建筑师,一个会写代码诗的建筑师。今天就来聊聊Python网络数据采集_python获取网络数据,希望能帮助大家提高!!!
Python 网络数据注意事项 采集 第 1 部分 创建爬虫 第 1 章 最初构建网络爬虫
html → ...... - head → A Useful Page - title → A Useful Page - body → An Int...Lorem ip... - h1 → An Interesting Title - div → Lorem Ipsum dolor... 建筑师
办公室只听到了建筑师君的声音:
风梳万缕亭前柳。谁将是上行链路或下行链路?
章
2 解析复杂的 HTML 第 3 章 第 4 章中使用 API 采集
此代码由Java架构师必看网-架构君整理
token = token
webRequest = urllib.request.Request("http://xxx", headers={"token": token})
http://socialmediasite.com/api/v4/json/users/1234/posts?from=08012014&to=08312014
<p>
</p>
此代码由Java架构师必看网-架构君整理
http://socialmediasite.com/users/1234/posts?format=json&from=08012014&to=08312014
第5章 存储数据
from urllib.request import urlretrieve from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://www.pythonscraping.com") bsObj = BeautifulSoup(html) imageLocation = bsObj.find("a", {
"id": "logo"}).find("img")["src"] urlretrieve (imageLocation, "logo.jpg")
第六章 阅读文档
dataFile = io.StringIO(data)
from zipfile import ZipFile from urllib.request import urlopen from io import BytesIO wordFile = urlopen("http://pythonscraping.com/pages/AWordDocument.docx").read() wordFile = BytesIO(wordFile) document = ZipFile(wordFile) xml_content = document.read("word/document.xml") print(xml_content.decode("utf-8"))
第2部分 高级数据采集 第7章 数据清理 第8章 自然语言处理:汇总数据、马尔可夫模型、自然语言处理
from nltk import word_tokenize from nltk import Text tokens = word_tokenize("Here is some not very interesting text") text = Text(tokens)
第9章 使用登录窗口遍历Web表单以采集请求库提交基本表单单选按钮,复选框和其他输入提交文件和图像
import requests file = {
"image": open("filename", "rb")} response = requests.post("http://...", data = file)
登录和 Cookie 的处理
import requests from requests.auth import AuthBase from requests.auth import HTTPBasicAuth auth = HTTPBasicAuth('ryan', 'password') r = requests.post(url="http://pythonscraping.com/pages/auth/login.php", auth=auth) # HTTPBasicAuth对象作为auth参数传递到请求
第 10 章 采集 JavaScript 简介 Google Analytics Google Map
var marker = new google.maps.Marker({
position: new google.maps.LatLng(-25.363882,131.044922),
map: map,
title: 'Some marker text'
});
ajax 和动态 htmlSelenium 通过属性选择匹配任意字符或节点 逐个位置选择节点 *(星号),可以在不同条件下使用微软的 Xpath 语法处理页面重定向 第11章 图像识别和文字处理 OCR(光学字符识别) 处理格式化文本 使用训练验证码阅读验证码 获取验证码提交答案 第12章 避免采集陷阱 道德 让机器人看起来像人类 用户常见形式 安全措施问题清单使用爬虫测试网站测试 Python 单元测试简介硒单元测试使用硒单元测试进行Python 单元测试 使用 Selenium 单元测试选择 Python 单元测试与硒单元测试 第 14 章 远程采集 为什么要使用远程服务器 Tor 代理服务器
互联网真的是一个超级API,界面不是很人性化
蟒蛇的禅宗
美丽总比丑陋好。显式总比隐式好。简单总比复杂好。复杂总比复杂好。平坦比嵌套好。稀疏比密集好。可读性很重要。特殊情况不足以违反规则。虽然实用性胜过纯洁。错误永远不应该默默地过去。除非明确沉默。面对模棱两可,拒绝猜测的诱惑。应该有一种——最好只有一种——显而易见的方法。尽管除非您是荷兰人,否则这种方式起初可能并不明显。现在总比没有好。虽然从来没有比现在更好。如果实现难以解释,这是一个坏主意。如果实现很容易解释,这可能是一个好主意。命名空间是一个很棒的主意 - 让我们做更多的事情!
美丽胜于丑陋 清晰胜于晦涩 简洁胜于复杂
复杂胜于混沌 平面比嵌套更好 松散比紧凑更好 可读性很重要 即使在特殊情况下,也不应违反这些规则 尽管现实往往并不完美,但除非您确定需要这样做,否则不应忽视任何例外情况 如果有多种可能性, 不要猜测 必须有一个 - 通常是唯一的 - 最佳解决方案 虽然这并不容易,因为你不是Python 1之父 动手总比不做要好 但最好不要不假思索地去做 如果你的解决方案很难理解,那肯定不是一个好的解决方案 如果你的解决方案很容易理解, 它一定是一个很好的解决方案 命名空间非常有用,我们应该利用它们
互联网简介:数据和采集道德约束

