最佳实践:阿里巴巴企业名录采集教程
优采云 发布时间: 2022-12-12 11:38最佳实践:阿里巴巴企业名录采集教程
本文介绍了如何使用 优采云采集 阿里巴巴企业名录。采集网站:
%CE%E5%BD%F0&button_click=top&earseDirect=false&n=y
阿里巴巴企业名录采集数据说明:本文仅以“阿里巴巴-供应商搜索-硬件所有企业信息采集”为例。在实际操作过程中,您可以根据自己对数据的需求更改阿里巴巴的搜索词采集。
阿里巴巴企业名录采集 内容说明:企业名称、*敏*感*词*营产品、企业所在地、企业员工人数、企业经营模式、企业处理方式、企业累计交易笔数、企业重复购买率。
使用功能点:
l分页列表信息采集
lXpath
第一步:创建阿里巴巴企业名录采集任务
1)进入优采云采集器主界面,选择自定义模式
阿里巴巴企业名录 采集 第 1 步
2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”,阿里巴巴企业名录采集的任务就创建好了。
阿里巴巴企业名录 采集 第 2 步
第 2 步:创建阿里巴巴企业名录翻页循环
l 找到翻页按钮,设置翻页周期
l 设置ajax翻页时间
l 设置滚动页面
1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧的操作提示框中,选择“循环点击下一页”选项。
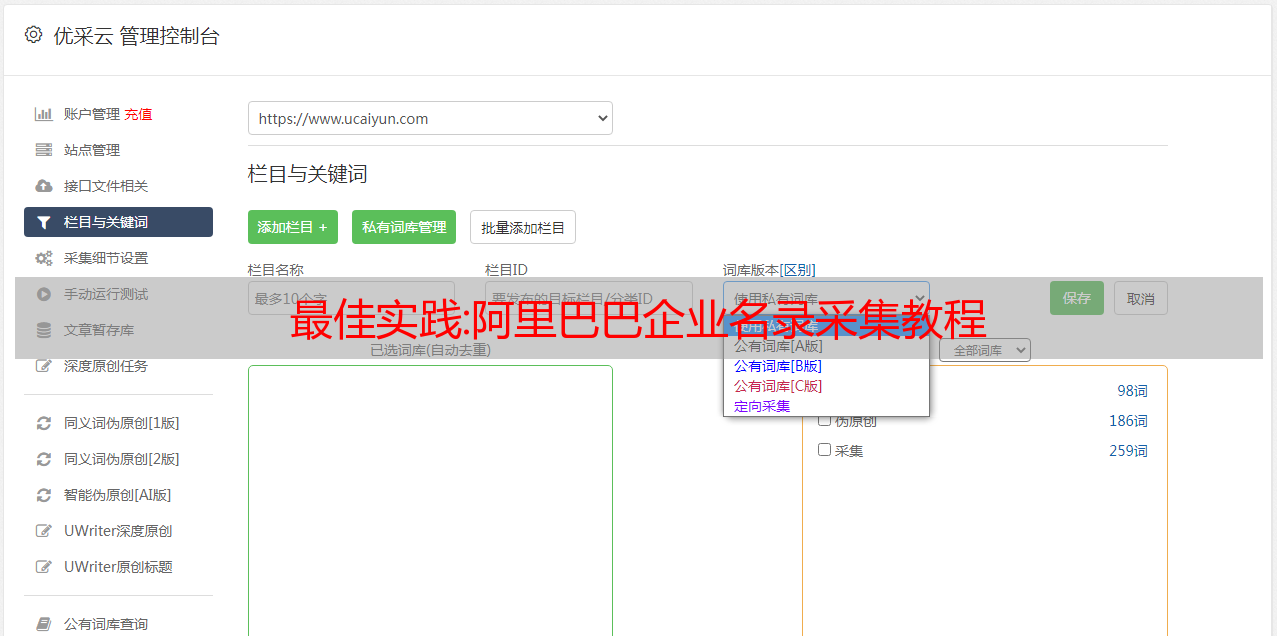
阿里巴巴企业名录 采集 第 3 步
第三步:阿里巴巴企业名录信息 采集
l 使用Google或Firefox观察源码,确定企业信息的xpath
l 提取企业信息
1)打开火狐或者谷歌浏览器,我用的是谷歌浏览器,将鼠标移动到企业信息栏,观察代码,可以发现整个企业信息的xpath是//div[@class="wrap"] ,这样就可以把整个企业数据作为一个循环,然后分别提取标题、主要产品、所在地、员工人数等企业数据。
阿里巴巴企业名录 采集 第 4 步
2)观察公司名称的源码,可以发现公司名称的xpath为
//div[@class="列表项标题"]
企业具体信息的xpath为
阿里巴巴企业名录 采集 第五步 - 企业名称的xpath
阿里巴巴企业名录 采集 第六步-企业具体信息的xpath
3)在流程图的左侧,可以拖拽一个循环,将数据提取到流程图中。
阿里巴巴企业名录 采集 第 7 步
4)点击刚才拖入流程图的循环模块,将图片采集的循环方式设置为不固定元素列表,在xpath前填写观察源码得到的代码(//div[@ class="wrap" ]) 然后单击确定。
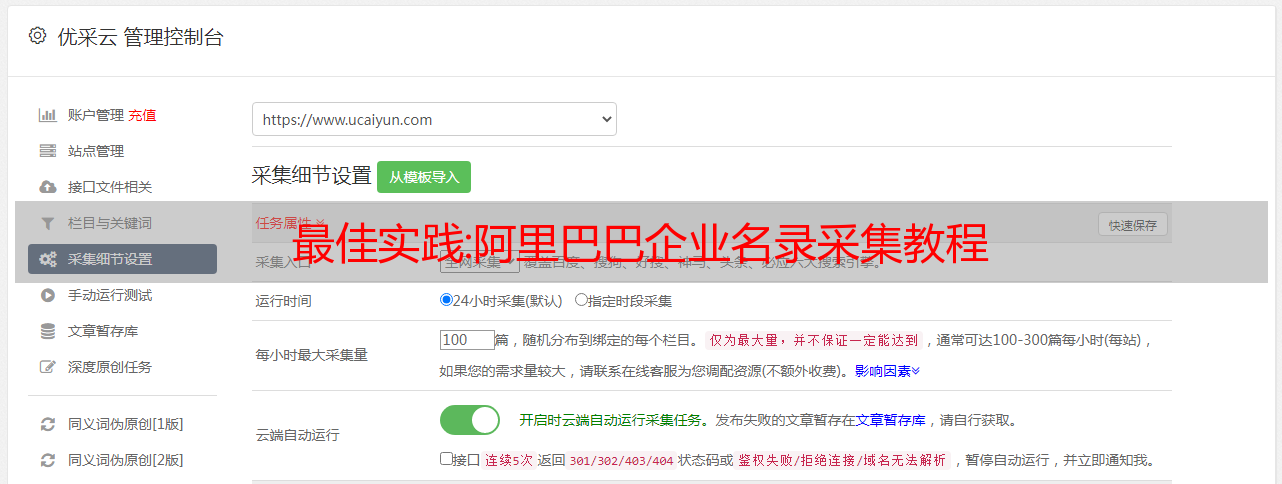
阿里巴巴企业名录 采集 第 8 步
5)提取元素选择添加空字段(第9步),命名为企业名称,第10步选择自定义数据字段(第10步),在弹出框中选择自定义定位元素,结合xpath之前分析过,如下图第11步设置,还是这个框,第12步设置自定义抓包方式如下图。
同样,企业的具体信息也采用同样的方式进行设置。自定义定位元素中元素匹配的Xpath设置是//div[@class="wrap"]/div[@class="list-item-detail"],相对于Xpath设置是/div[@ class="list-item-detail"],自定义获取方法设置为获取文本。
阿里巴巴企业名录 采集 第 9 步
阿里巴巴企业名录 采集 第 10 步
阿里巴巴企业名录采集 Step 11 - 自定义定位元素设置方法
阿里巴巴企业名录 采集 第十二步 - 自定义爬取方式
6)修改采集任务名称和字段名称,点击下方提示中的“保存并启动采集”
7) 根据采集的情况选择合适的采集方式,这里选择“Start local采集”
阿里巴巴企业名录 采集 第 13 步
注意:本地采集为采集占用当前电脑资源,如果有采集时间要求或者当前电脑长时间不能执行采集,可以使用云采集功能,云采集在网络采集中进行,没有当前电脑的支持,可以关闭电脑,多个云节点可以设置分担任务,10个节点相当于10台电脑分担任务,帮你采集,速度降低到原来的十分之一;采集获得的数据可在云端保存三个月,并可随时导出。第四步:阿里巴巴企业名录数据采集及导出
1)采集完成后,会弹出提示,选择导出数据
2)选择合适的导出方式导出采集好的数据
最佳实践:java基础;spring boot学习;微服务;Java教程;Java web
演示站:
(备注2018-06-05:由于服务器迁移到腾讯云,导致无法访问记录,导致腾讯云屏蔽我,我正在重新备案,网站目前无法访问访问,即使我可以,内容页面是为了备案,请见谅)
一、环境要求 linux+nginx+php5.6+mysql5+Memcache
2、建议安装宝塔linux系统环境,构建网站,在伪静态文件夹工具下添加nginx.conf内容:if (!-e $request_filename) { rewrite ^/(.* )/index.php? s=
最后;}3.给目录777权限,否则无法安装自动采集
4.设置好后,直接打开你的网站,根据提示填写网站的名字,数据库链接信息,设置后台账号密码...
5、然后去后台配置采集信息或者导入采集规则,添加任务。慢慢研究。
1.源码下载
源码下载:
2. 采集规则下载
上传一些后台采集规则(规则都是小灰灰自己写的,当然也有一小部分参考了别人写的)
规则:
ptcms_Yunlaige_2.txt(4.99 KB, 下载次数: 241)
ptcms_37中文网_2.txt(3.48 KB, 下载次数: 167)
ptcms_79 Literature_2.txt(3.27 KB, 下载次数: 144)
ptcms_88读书网_2.txt(3.19 KB, 下载次数: 100)
ptcms_八一中文网-主页_2.txt(3.34 KB, 下载次数: 122)
ptcms_笔下文学-采集rules_2.txt(3.42 KB, 下载次数: 149)(5月31日新增)
ptcms_New Biquge_2.txt(3.3 KB, 下载次数: 180) (6月1日新增)
ptcms_Apex Novels_2.txt(3.27 KB,下载次数:224)(6 月 2 日添加)
ptcms_E novel-home page_2.txt(3.9 KB, 下载次数: 184) (6月3日新增)
如果你有小说站点需要为ct编写采集规则,也可以提供站点网址,小灰灰会编写规则,有空上传。
3.PC版的分类和排行榜的修复,把文件放在对应的目录下即可~
pt分类排名修复.rar(2.39 KB, 下载次数: 181)
如图所示:
5.补充问题:(2018-06-03)
(1)如果安装后出现404,那肯定是你的伪静态规则有问题。上面提供的伪静态规则是 Ng。如果你用Apache,请自己转换(偷偷告诉你,伪静态规则在tool文件夹里。)
(2)采集完成后会显示转码失败,可在后台设置项:转码阅读显示方法:修改为直接在此处显示即可解决问题
(三)其他需要补充的问题
有回复就有动力。天冷了,我连规矩都懒得分享了。有用的话我会点赞回复的,或者大家有什么问题请告诉我,不然就荒废了~
可以的话记得多给分哦~~~~
小灰灰缺我的爱情币
谢谢亲爱的

