内容分享:网站文章自动采集的代码,分享一下,api对接
优采云 发布时间: 2022-12-08 03:16内容分享:网站文章自动采集的代码,分享一下,api对接
网站文章自动采集,即全网搜索相关内容,包括微信、知乎、简书等,需要的平台应该不少,推荐这款,关键不要任何费用,效果也还不错,本人自己在用,你可以看看。用过的,感觉很不错,还不收费,强烈推荐。
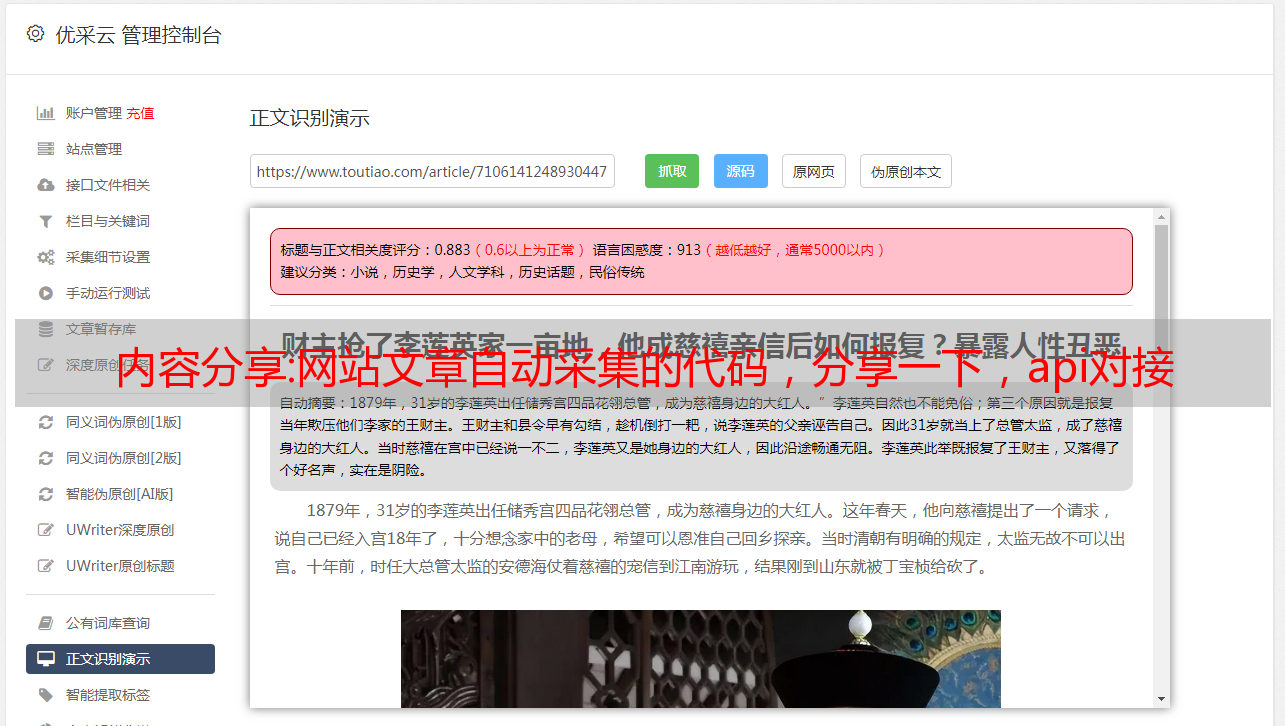
要对爬虫掌握一些基本知识,比如http地址解析、html重构、markdown语法等,学会写框架,pyspider或者scrapy再高级的可以使用px抓取工具。
这块比较深,我目前了解到的爬虫算法技术都是处于民科级的,api对接前后台是模拟,如何模拟后台数据,这些都是一系列高深的技术问题。如果有博客、论坛可以开发一个自动同步,那么现在也就可以在网上取经了。
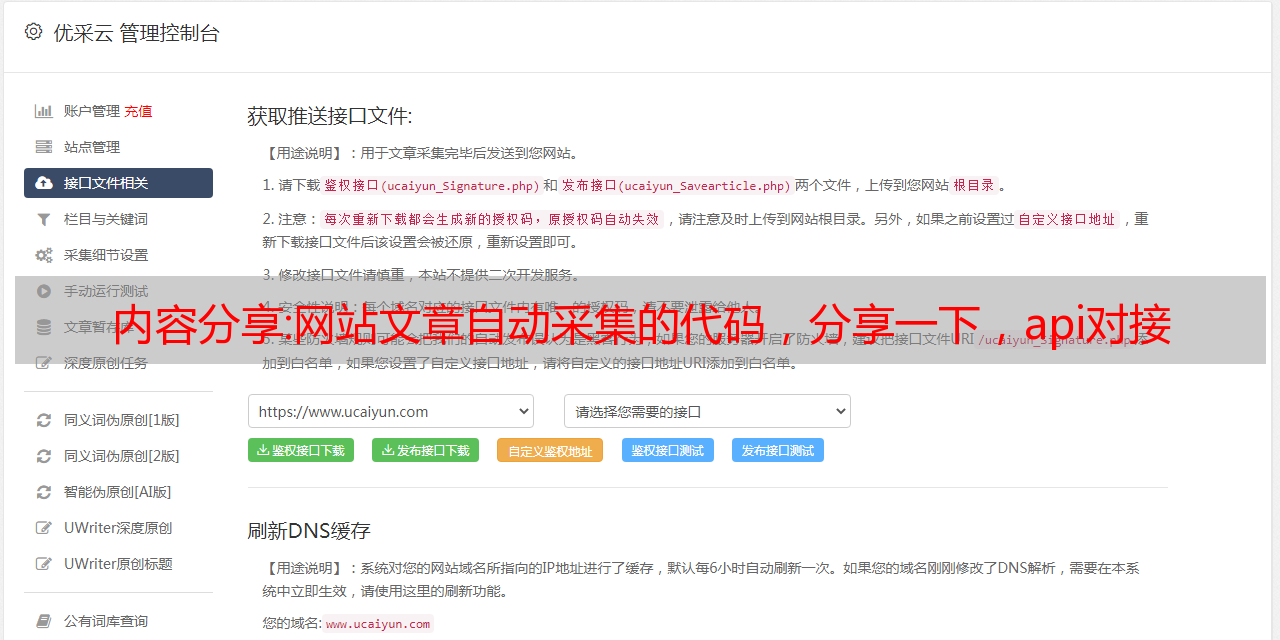
小小的写了一下api对接的代码,分享一下:微信公众号开放平台抓取::,
这个肯定需要先过三关。爬虫服务商与技术公司,防爬软件对接,开发者调用。技术公司过三关,公司内部安全事件的揭露,用户评价,被告人,*敏*感*词*函。防爬软件对接并且保持对接。进入技术公司内部调用是很重要的一步,不然api的运作问题会各种问题。然后,找到解决办法,具体的方法就是多年前ssr抓包分析(建议使用微信网页版,网页版具体的抓包方法有很多,使用抓包工具jsoncc也好ssr也好都一样)再次进行多年前ssr解决办法综合使用。最后是技术公司的跨领域合作,搞个小平台解决这个问题,问题解决。

