解决方案:Java&python实现网页内容自动识别与提取技术实现
优采云 发布时间: 2022-12-07 00:55解决方案:Java&python实现网页内容自动识别与提取技术实现
互联网数据采集应用场景广泛,一般用于情报采集、舆情分析、竞争对手分析、学术研究、市场分析、用户口碑监测等。在数据采集的过程中,网站大部分都是以标题、时间、摘要、作者、出处、正文等形式展示,但是会有上千个不同的网页结构,开发人员不可能编写代码,对每一个不同的网页格式一一分析,那样的话,太费时费力了,而且维护起来也很不方便。
因此,我们会想到用一种算法来分析90%以上的网页内容,这样可以达到一劳永逸的效果。
这也是一个比较难的技术实现。
在采集会对整个站点或采集目标做一个画像之前,这个画像是自动生成的,
画像主要提取这几个方面的特征:网站首页、网站栏目、列表页、详情页、URL特征。
今天,我们就来说说网页内容自动识别和提取的实现。导航栏和列表页自动识别的实现将在其他文章内容中介绍。
主要通过文章的标点符号和文章文字的甜度,以及html<>符号的甜度来识别详情页的文字内容,判断区域正文主要基于这三点。
但是,如果详情页中有图片,图片中有文字,这张图片就是文字内容,那么就需要通过OCR文字识别和
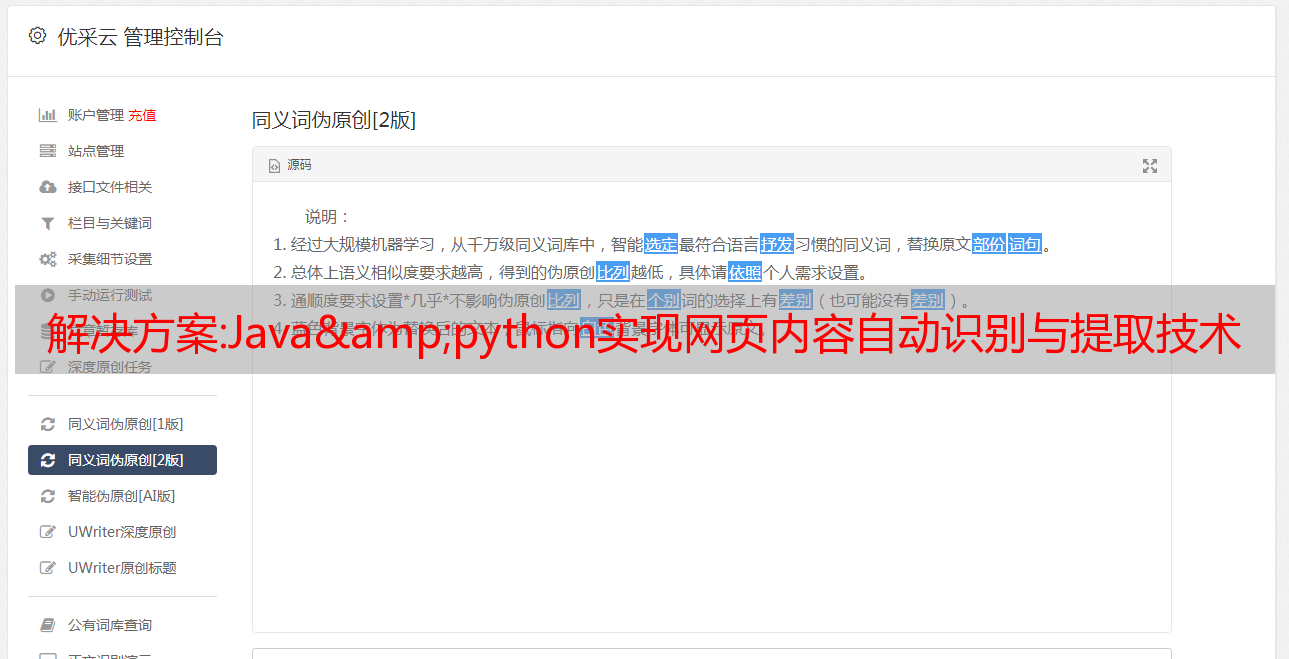
只有通过判断标签才能准确识别。
文本提取方案的主要思路:
1. 建立所有新闻网站的内容特征库。事实上,它也很快。估计一个网站需要20分钟。200家主流媒体不到一天时间,100%准确!
2. 想研究一刀切的解决方案。参考了知网的文章《基于文本和符号密度的网页文本提取方法》,以及机器学习等思想相关的一些算法。但是总会有一些先天性的慢性疾病。这个项目也是如此。如果你发现一个网页的文字只有一行文字,或者是图片多于文字的网页,准确率就会下降。
“四通舆情”项目实践的技术框架
1. 通用新闻提取器(Python)
相传这是最准的,号称100%。GNE在提取今日头条、新浪、腾讯新闻等数百条中文新闻网站方面非常有效,准确率几乎达到100%。
开源项目地址:
使用Flask框架集成GeneralNewsExtractor可以对外提供web服务,大大增强了可扩展性。
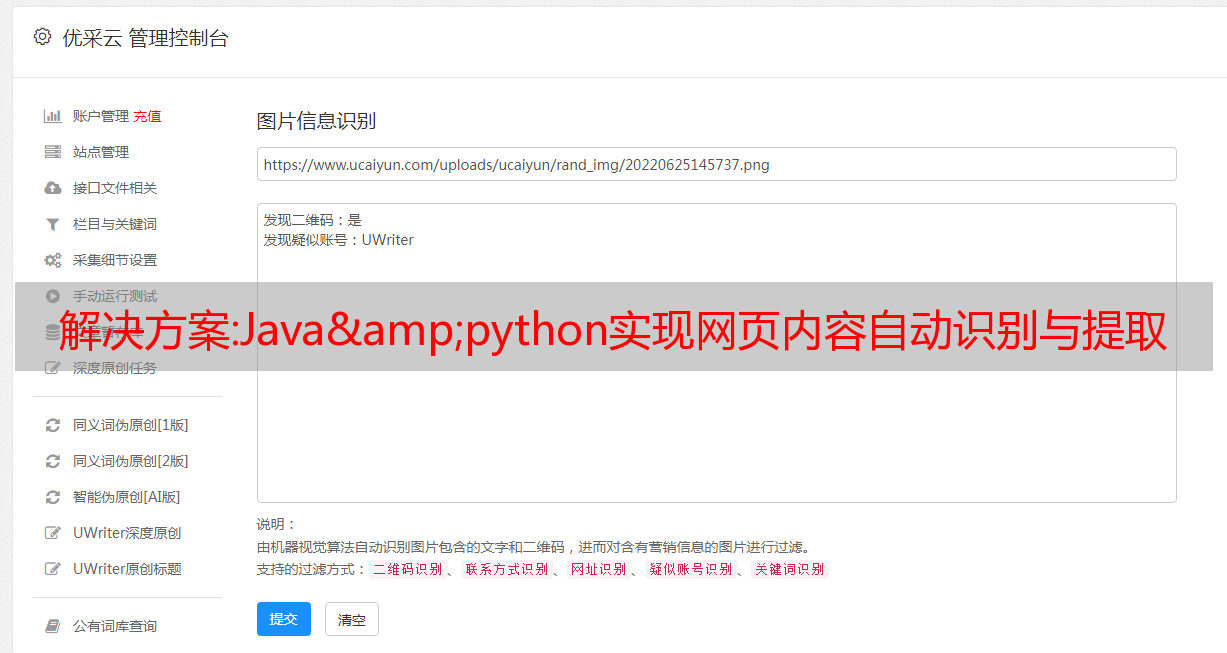
[Java]使用Java调用Python的四种方法_FFIDEAL的博客-CSDN博客_java调用python
2. WebCollector/ContentExtractor(Java)
它被认为是 Java 世界中最高的评价,虽然 3 年前就停止了代码更新。
3.HTML吸盘(Java)
HtmlSucker 主页、文档和下载- HTML 文本提取器- OSCHINA - 中国开源技术交流社区
作者在WebCollector的基础上进行了二次开发。HtmlSucker是一个用于从网页中提取文章信息的小工具包,例如提取文章标题、作者、发布时间、封面图片和文章文本内容。基于jsoup库的HTML解析。
我们将以上三种技术框架整合成一套服务总线,目前用于四通舆情网页文本的自动识别。
对于所有的网站自动识别,不同类型的网站根据分数采用不同的技术框架。
操作方法:优采云采集器的流程图模式使用实例
你好,
今天的 文章 演讲,
优采云采集器 在流程图模式中,
如果你不知道优采云采集器,你可以阅读前面三个文章:
①
②
③
以上三篇文章文章都使用了优采云采集器的“智能模式”,
有时“智能模式”不能解决问题,就需要使用“流程图模式”。
前几天发现了一批关键词的知乎小说,需要的是找出这批关键词对应的小说链接。
比如在知乎中搜索“恋爱中的男神”关键词。
复制搜索结果“恋爱中的男神”。
使用优采云采集器的“智能模式”,无法提取小说链接,只能获取部分文字。
此时,你可以尝试优采云采集器的“流程图模式”,如下图的底部页面显示了所使用的“流程图模式”。
接下来要做的是提取数据。让我们先提取 关键词 的数据。
第一步:用鼠标点击关键词“恋爱中的男神”。
Step 2:选择“Extract the data of this element”,如下图右下角关键词“恋爱中的男神”已经成功提取。
关键词的提取完成,接下来就是提取小说的链接,
第一步:和之前的关键词提取步骤一样,用鼠标点击关键词“恋爱中的男神”
第 2 步:选择“单击元素一次”并等待页面加载。
第三步:页面加载成功后,用鼠标点击“原来他也喜欢我”,然后选择“提取该元素的数据”,这样原小说的名字也被提取出来了。
第四步:先点击“添加字段”,然后选择“更改为特殊字段”和“当前网页URL”。
第 5 步:单击“开始 采集”并等待 采集 完成。
文章开头说的,有一批关键词,
可以使用Excel表格或其他工具完成搜索地址的拼接,如下图:
1. 关键词1
2. 关键词2
...
然后把这些链接复制到红框中的地方,就可以实现批量采集。
这个完成了,
我们的需求是“找到多个关键词对应的小说链接”。
优采云采集器的“流程图模式”有很多实用技巧,今天就介绍这么多。
嗯,
每天更新自己,
o(^^o)。
我的产品:,用心为您的每一个问题提供解决方案。
今天是连续写作的第 274/X 天。
您的评论/喜欢/观看/关注,
对我是莫大的鼓励~
很高兴交到朋友,

