解决方案:什么是优采云采集器 如何使用优采云采集器软件_爬虫软件技术与爬虫软件网页数据采集器门
优采云 发布时间: 2022-12-06 14:50解决方案:什么是优采云采集器 如何使用优采云采集器软件_爬虫软件技术与爬虫软件网页数据采集器门
什么是优采云采集器如何使用优采云采集器软件_爬虫技术和爬虫网络数据采集器传送门
图 160S
2018 年 10 月 28 日
优采云Data采集 平台是一个通用数据采集 程序框架。包括数据采集最常用的规划任务、数据发布、文字识别、OCR图形图像识别、采集存储等模块,可以支持其他采集软件快速、在平台上稳定使用。优采云采集器平台定义了统一的接口规范,提供了大量的API。用户可以轻松开发自己的应用程序并在该平台上运行,可以减少开发时间和成本。目前平台上有官方优采云采集器。
1. 优采云采集器 系统要求
操作系统:Win7、WinXP、Win2008、Win2003、Windows 2000等windows内核操作系统
硬件配置:CPU主频1.6G以上,内存1G以上,分辨率至少1024*768,网络带宽1Mbps以上。
必备组件: 本软件需要安装.NET FrameWork 2.0框架。如果程序无法打开,请下载并安装微软的.NET FrameWork 2.0框架。.net framework 2.0下载地址:
32位操作系统:
64 位操作系统:
2. 优采云采集器程序安装
将下载的压缩包直接解压到电脑任意位置即可完成采集的安装——安装过程不操作注册表和系统文件,不产生任何垃圾文件!
3. 优采云采集器程序升级
运行程序目录下的AutoUpdate.exe,根据提示升级。
4 卸载程序
只需删除采集 整个安装文件夹即可完成程序的卸载。卸载前,强烈建议您备份 Configuration、Extensions、Data 和 Module 文件夹(即用户配置、扩展目录、采集 数据和模块)以备下次使用!
采集相关条款
1. 优采云采集器采集 规则
简称规则,在V7之前的采集规则分为站点规则和任务规则,通常是指任务规则。V7及之后的版本使用了无限制的群管理任务规则,不再有站点规则的概念。所谓采集规则就是需要在软件中对采集一个网站或某个网站栏目网页进行设置。此设置可以从软件导出并保存为文件,然后导入到软件中。V7中任务规则文件的后缀为.ljobx,之前站点规则文件的后缀为:.lsite;任务规则文件后缀为:.ljob。
2. 优采云采集器采集 任务
采集任务也简称为任务。它是采集规则和发布规则的总和。它也是 采集 规则和发布规则的载体。采集任务编辑框可以设置规则和发布规则。从采集导出的采集规则文件(后缀为.ljobx)也可以称为作业规则。导入导出任务规则用于指导.ljobx文件的导入导出。
3. 优采云采集器 发布模块
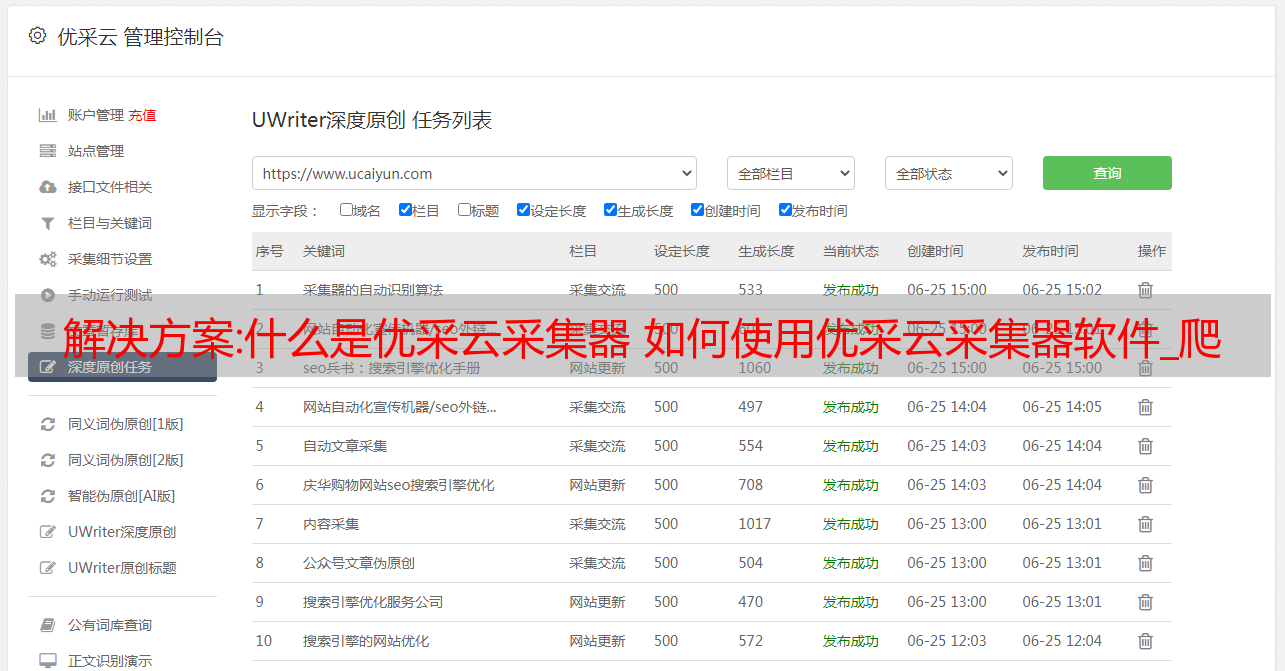
发布模块又称模块、发布规则,分为WEB发布模块和数据库发布模块。所谓发布模块,就是当采集数据需要发布到目的地(例如:网站/后台或指定数据库)时软件中的设置。此设置可以保存为文件并导入到 采集 中使用。数据库发布模块文件后缀为:.dpm;WEB在线发布模块文件后缀为:.wpm。(采集规则和发布模块可以从采集导出,也可以导入采集使用。采集规则负责网页上的数据采集 接下来发布模块负责将采集的数据发布到网站。可以看出,采集规则的编写和修改与网站即采集相关,release模块的编写和修改与网站相关> 发布数据。例如,从不同的网站列采集数据到同一个网站(频道)的某个部分,需要多个采集规则和一个发布模块。从一个 网站 列 采集 向不同的 网站 系统发布数据需要一个 采集 规则和多个发布模块。请注意,这里的采集规则指的是采集网站和抓取内容的设置。)而release模块的编写和修改,则与网站相关,用于发布数据。例如,从不同的网站列采集数据到同一个网站(频道)的某个部分,需要多个采集规则和一个发布模块。从一个 网站 列 采集 向不同的 网站 系统发布数据需要一个 采集 规则和多个发布模块。请注意,这里的采集规则指的是采集网站和抓取内容的设置。)而release模块的编写和修改,则与网站相关,用于发布数据。例如,从不同的网站列采集数据到同一个网站(频道)的某个部分,需要多个采集规则和一个发布模块。从一个 网站 列 采集 向不同的 网站 系统发布数据需要一个 采集 规则和多个发布模块。请注意,这里的采集规则指的是采集网站和抓取内容的设置。)采集 到不同的 网站 系统需要一个 采集 规则和多个发布模块。请注意,这里的采集规则指的是采集网站和抓取内容的设置。)采集 到不同的 网站 系统需要一个 采集 规则和多个发布模块。请注意,这里的采集规则指的是采集网站和抓取内容的设置。)
4. 优采云采集器 标签
标签是指用于提取某些内容信息的字段名,由用户在编辑规则时指定。比如标题,手机号,邮箱,作者,内容标签,采集获取的信息可以通过release模块中对应的标签名获取,格式为[标签:标签名]这样的如 [tag: title] ,优采云采集器中有两类标签:列表页标签和内容页标签。对于内容信息,内容页标签只有在获取内容页或多页内容(集合内容)时才获取内容信息。
注意:html标签通常还有另一种说法,这里的标签指的是一些html代码中的属性标识,比如:
5. 优采云采集器 起始网址
用于获取子链接地址的入口URL可以是一个,也可以是多个。您可以通过添加起始 URL 向导添加多个具有相同格式的 URL 或导入文本 URL。这里的起始URL相当于2010版本之前的0级URL的概念。如果没有定义获取多级 URL 的方法,这些地址将用作内容 采集 的内容页面 URL。
6. 优采云采集器 多级 URL
根据列表中多级URL采集的顺序分析地址。多级URL相当于2010版之前的1级、2级、3级到N级的概念。依次解析采集到最后一层,得到内容页的地址。多级URL的获取可以采用自动分析、手动分析、Xpath可视化抽取方式采集获取低级URL。在采集的过程中,可以同时采集列表分页和从列表页中提取附加参数。
7. 饼干
简单的说就是一个字符串,用来和服务交互,记录你的用户信息,也就是登录信息,在Http请求访问中。在浏览时使用时,通常会以文本形式记录在您的IE缓存目录中,以便您下次在有效期内无需输入用户信息即可继续访问已验证权限的网页。
8.用户代理
这个用来通知服务你使用的客户端是IE6、IE7、FireFox或者某个爬虫。在一些需要登录的网页中,可能会同时验证Cookie和User-Agent,所以可能需要设置为与原生浏览相同的格式。
9.分页
比如这个文章页面:它的内容比较长,分成7页显示,真正的内容需要组合7页的内容。这样的7个子页面就是分页。
10.多页
比如绿盟科技的这个页面:我们需要获取它的下载地址,下载地址需要打开新的页面才能看到。在这个页面中,我们称后一个页面为多页。
同理,要获取这样一个产品页面中的所有对应信息,并使用一条规则搞定,需要定义多个页面,例如:报价:、参数:多个页面、图片:多个页面: 等等。V7的无限多页规则可以在多页中继续设置多页或者桥接页采集子级内容,比如本例图片的多页:也分为:外观图片,细节图片, 附件图片, 要获取附件图片的所有内容,需要在图片多页的基础上继续定义一个二级深度的附件图片多页:。将标签 采集 定义为您在此多页中需要的信息。
11. 常规
指用于描述或匹配一系列符合一定语法规则的字符串的单个字符串。详见百度百科:例如d+可以匹配一个或多个数字。这里收录有一个30分钟的正则表达式经典教程:
优采云采集器有纯正则,也有基于参数匹配的伪正则。匹配时,用【参数】标签替换你要提取的字符串,用【合并时对应序号的参数1】、【参数2】、【参数N】合并需要的字符串。有关详细信息,请参见下面的 [parameter] 项。
[范围]
用于匹配要抽取的某个信息的标记。例如,如果你想在下面的代码中提取和组合某种格式。从代码“mClk(this,'108484','134217','168475','1');”中提取并组合新的地址格式 举个例子。
"mClk(this,'[parameter]','[parameter]','[parameter]','1');",按照顺序,参数108484为参数1,以此类推。实际需要的地址是如下地址格式:bbs/read.php?id=[参数1]&sort=[参数3]&action=[参数2],上面代码中的3个参数和下面地址中的id, soft和action参数要对应相应的值,顺序不能颠倒。这形成了新的地址格式。
(*)
(*)是通配符,在优采云采集器中可以表示起始地址中的页码,可以匹配标签规则、模块或其他设置中的任意字符串,如(*)可以匹配xxx 字符串也可以匹配到 yy 字符串。
12.cron 表达式
它是一个收录 6 或 7 个子表达式的字符串。每个表达式代表一个字段,每个字段描述一个单独的计划明细,每个字段由一个空格分隔,由两种格式组成。
秒 分钟 小时 DayofMonth Month DayofWeek Year 或
秒 分 时 月中的日 月中的日
Cron 表达式至少有 6 或 7 个由空格分隔的时间元素。每个时间元素都使用数字,但也可以出现以下特殊字符,分别表示其含义:
1.Seconds 秒(允许值0-59,允许特殊符号,-*/)
2.Minutes分钟(允许值0-59,允许特殊符号,-*/)
3.Hours小时(允许值0-23,允许特殊符号,-*/)
4. Day-of-Month 一个月中的第几天(允许取值1-31,允许使用特殊符号,- * / ? LWC)
5.Month月份(允许取值1-12或JAN-DEC,允许使用特殊符号,-*/)
6. Day-of-Week 星期几(允许值1-7或SUN-SAT,允许特殊符号,-*/?LC#)
7.Year (optional field) Year (optional field, allowed value is left blank or 1970-2099, allowed special symbols, - * /)
特殊字符含义:
(1) * 表示该字段的任意值。如果在 Minutes 字段中使用 *,则表示该事件将每分钟触发一次。
(2)?它只能在 DayofMonth 和 DayofWeek 字段中使用。实际上不会匹配域的任何值,因为 DayofMonth 和 DayofWeek 会相互影响。如果想在每个月的20日触发调度,不管20日是星期几,只能使用如下写法:13 13 15 20 * ?,最后一位只能是?而不是*,如果用*表示每个月20号的15:13:13,不管星期几都会触发,其实不然。
(3) – 表示范围,比如在Minutes字段中使用5-20,表示从5到20分钟每分钟触发一次
(4)/表示从开始时间开始触发,之后每隔固定时间触发。例如Minutes字段中使用5/20,表示从第5分钟开始每20分钟触发一次,结果分别在25、45、05等触发一次。
(5)、表示列举枚举值。如果在Minutes字段中使用5,20,则表示每分钟触发5分钟和20分钟。
(6) L表示last,只能出现在DayofMonth和DayofWeek字段中。
(7) W表示有效工作日(周一至周五),只能出现在DayofMonth字段中,系统会在离指定日期最近的有效工作日触发事件。此外,W 的最近查找不会跨越数月。
(8) # 用于判断每个月是星期几,只能出现在DayofMonth字段中。例如,4#2 表示某月的第二个星期四。
在新版优采云采集器定时任务管理定时任务设置中,可以设置完整的cron表达式。例如,0 15 08 ?* MON-FRI表示每周一至周五上午8点15分定时更新数据。
解决方案:优采云采集器能采集什么内容?
采集 就直接用吗?站群适不适合采集,以及如何操作,大侠来指导。
不吹牛,我什至不知道你在说什么。
###
花1400RMB充值优采云永久会员,说说感受,无*敏*感*词*...
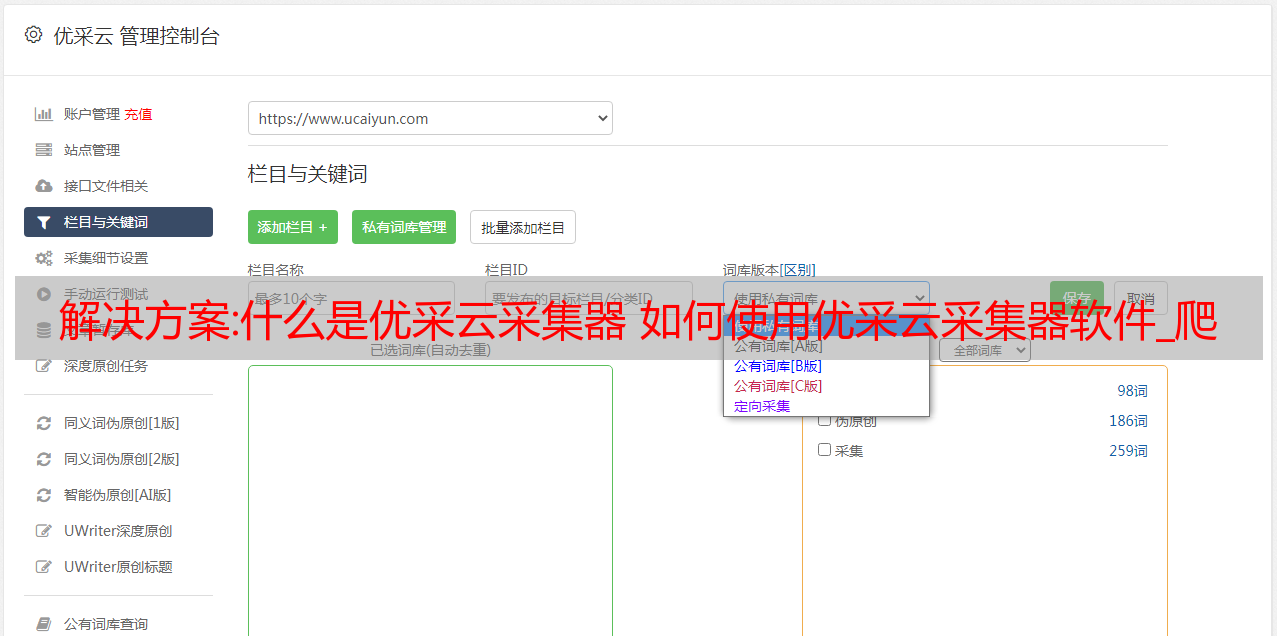
(1)可以设置采集规则,原理和phython类似,通过匹配源码中列表的首尾,匹配区域中的a标签url和采集过来,支持多页采集,比如别人的文章列表是1页10篇文章,一共90页,你也可以采集 马上过来。
(2)采集内容页,在找到上面第一步所有对应的文章内页链接的基础上,爬取每个文章的标题和内容,也可以下载源文章内容中的图片,并在参考路径上对应。
(3) 内容发布,支持一键发布市面上流行的cms程序,如织梦、Empire、WordPress等。我用的是dede织梦,一般是采集一批文章过来之后,大概有几百几千篇,我每天手动勾选采集器 5篇左右发布,效率更高。
###
我不知道你描述的是什么
###
不吹牛,我什至不知道你在说什么。
爱情约会
###
直接导入数据库是可以的,但是没必要,采集现在站不住脚了

