内容分享:we-extract解析和采集微信公众号文章的账号及内容必备工具
优采云 发布时间: 2022-12-06 10:48内容分享:we-extract解析和采集微信公众号文章的账号及内容必备工具
We-extract是分析采集微信公众号文章账号和内容的必备工具
时间:2022-07-27
本次文章介绍we-extract分析和采集微信公众号文章账号和内容必备工具。主要内容包括其使用实例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考。
介绍
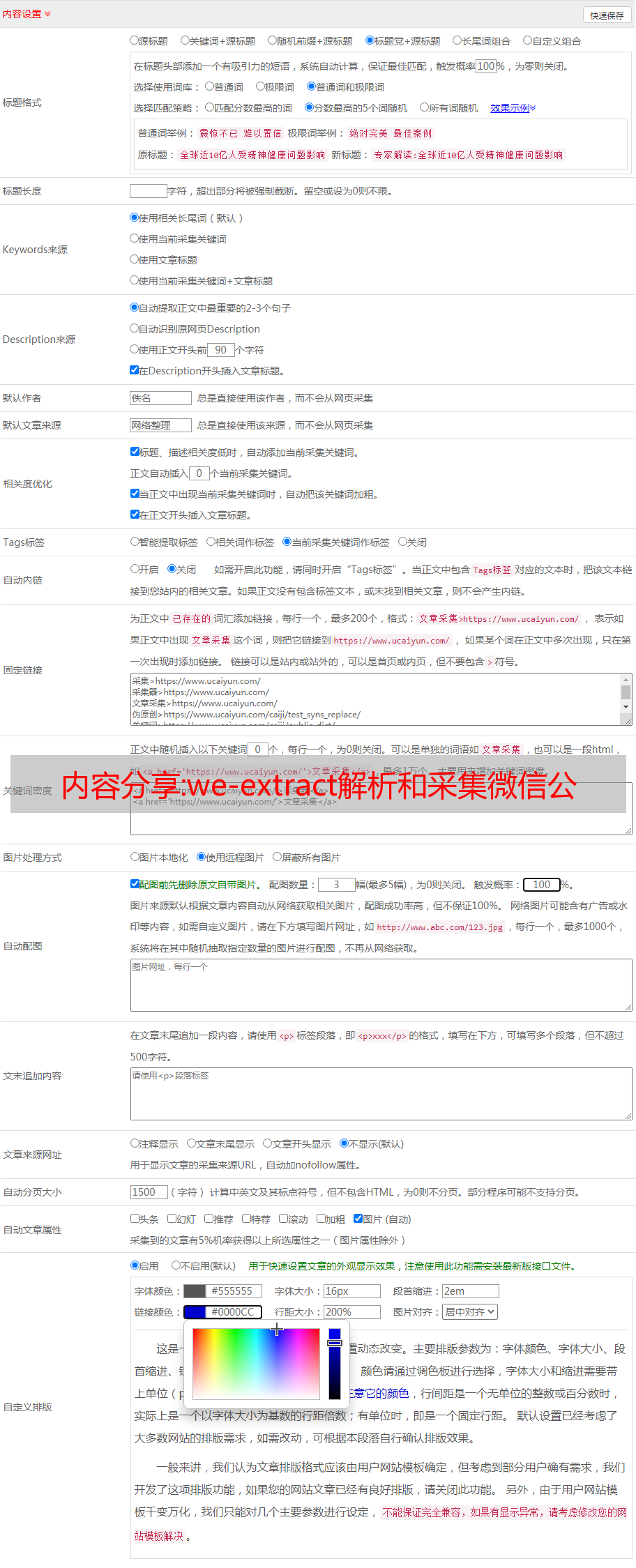
we-extract用于分析微信公众号文章的账号和文章信息,居家旅行必备工具,采集微信公众号文章。
we-extract是订阅服务WeRss的核心工具,欢迎使用:
安装
npm install we-extract
// or
yarn add we-extract
利用
节点版本需要支持异步
const extract = require('we-extract').extract
const rs = await extract('微信文章 url 或者 文章内容')
// 选项
const rs = await extract('微信文章 url 或者 文章内容', {
shouldReturnRawMeta: false, // 是否返回原始的 js 解析结果,一般只用于调试,默认不返回
shouldReturnContent: true // 是否返回内容,默认返回
})
返回结果说明
正确返回
{
<p>
done: true,
code: 0,
data: {
account_name: '微信派',
account_alias: 'wx-pai',
account_avatar: 'http://wx.qlogo.cn/mmhead/Q3auHgzwzM7Xb5Qbdia5AuGTX4AeZSWYlv5TEqD1FicUDOrnEIwVak1A/132',
account_description: '微信第一手官方活动信息发布,线下沙龙活动在线互动平台。独家分享微信公众平台优秀案例,以及权威专家的精彩观点。',
account_id: 'gh_bc5ec2ee663f',
account_biz: 'MjM5NjM4MDAxMg==',
account_biz_number: 2396380012,
account_qr_code: 'https://open.weixin.qq.com/qr/code?username=gh_bc5ec2ee663f',
msg_has_copyright: false, // 是否原创
msg_content: '省略的文章内容',
msg_author: null, // 作者
msg_sn: '9a0a54f2e7c8ac4019812aa78bd4b3e0',
msg_idx: 1,
msg_mid: 2655078412,
msg_title: '重磅 | 微信订阅号全新改版上线!',
msg_desc: '今后,头图也很重要',
msg_link: 'http://mp.weixin.qq.com/s?__biz=MjM5NjM4MDAxMg==&mid=2655078412&idx=1&sn=9a0a54f2e7c8ac4019812aa78bd4b3e0&chksm=bd5fc40f8a284d19360e956074ffced37d8e2d78cb01a4ecdfaae40247823e7056b9d31ae3ef#rd',
msg_source_url: null, // 音频,视频时,此处为音频、视频链接
msg_cover: 'http://mmbiz.qpic.cn/mmbiz_jpg/OiaFLUqewuIDldpxsV3ZYJzzyH9HTFsSwOEPX82WEvBZozGiam3LbRSzpIIKGzj72nxjhLjnscWsibDPFmnpFZykg/0?wx_fmt=jpeg',
msg_article_type: null, // 文章分类
msg_publish_time: '2018-06-20T10:52:35.000Z', // date 类型
msg_publish_time_str: '2018/06/20 18:52:35',
msg_type: 'post' // 可能为 post repost voice video image
}

}</p>
错误返回
{
done: false,
code: 2002,
msg: '链接已过期'
}
常见错误
we-extract 定义了详细的错误信息,方便开发和错误处理。1开头的error表示可能需要重试(或者暂时保存内容调试),2表示错误没有疑问,可以不处理。
'1000': '解析失败,可能文章内容不完整',
'1001': '字段缺失',
'1002': '请求文章内容失败',
'1003': '请求文章内容为空',
'1004': '访问过于频繁',
'1005': 'js 变量解析出错',
'2001': '参数缺失',
'2002': '链接已过期',
'2003': '该内容被投诉且经审核涉嫌侵权,无法查看',
'2004': '公众号迁移但文章未同步',
'2005': '该内容已被发布者删除',
'2006': '此内容因违规无法查看',
'2007': '涉嫌违反相关法律法规和政策发送失败',
'2008': '微信文章系统出错',
'2009': '链接不正确'
经验
更多经验坑会持续更新到Github项目页面。
分享:采集小红书数据爬虫,小红书app爬虫数据采集,仅供学习交流使用
采集 小红书数据爬虫:
1、本来打算通过app端的界面直接访问采集数据,但是在app界面手机端设置本地代理并开启抓包后,无法正常访问数据.
于是在微信小程序中使用小红书app接口获取采集数据。
2、使用fiddler抓包,在手机端进入小程序端口,选择makeup向下滑动请求数据,fiddler会抓取请求数据和相应的响应。
从上面两张图中,可以看到请求的一个过程。这里每次点击拖动只会更新10条数据(数据收录在data{}中)。接下来我们分析请求的header参数。
“授权签名”:“13c136011f62d6bc0e7d2bf1f7f04201”,
而且参数还具有时效性,可以在请求的时间段内返回有效数据。
这里暂不做分析,先把这10条数据拿下来试一下,以后再处理。
本期学习交流先到这里,感谢阅读
python交流群:414967318
如有需要请访问:/zcykj.html

