最新版:苹果cmsv10如何给视频添加迅雷下载地址?
优采云 发布时间: 2022-12-06 01:25最新版:苹果cmsv10如何给视频添加迅雷下载地址?
随着网站的数量越来越多,竞争越来越激烈,站长们对网站的内容和功能提出了更高的要求。
今天给小白站长们分享一下如何给视频网站添加迅雷下载地址,可以跳过。
我们在使用采集资源时,资源站通常有播放和下载两个界面。
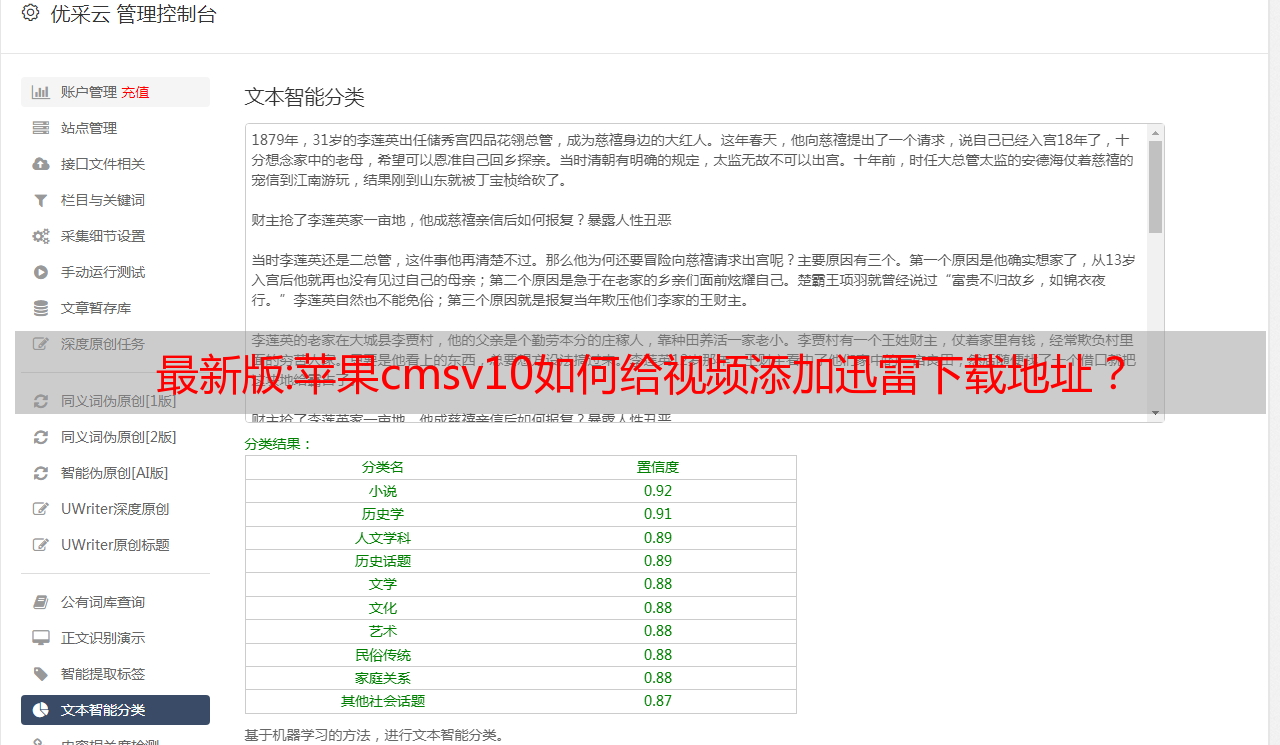
一般我们只添加采集播放接口。如果想让网站有下载视频的链接,那么需要添加采集下载接口。
这会在你想要的资源站采集中提供一个下载界面。我们只需要像添加采集播放接口一样添加上传下载接口即可。
但是,在书写上也有差异。除了接口不同之外,还有一些参数需要添加。以下是添加下载接口时的几个步骤,供参考。
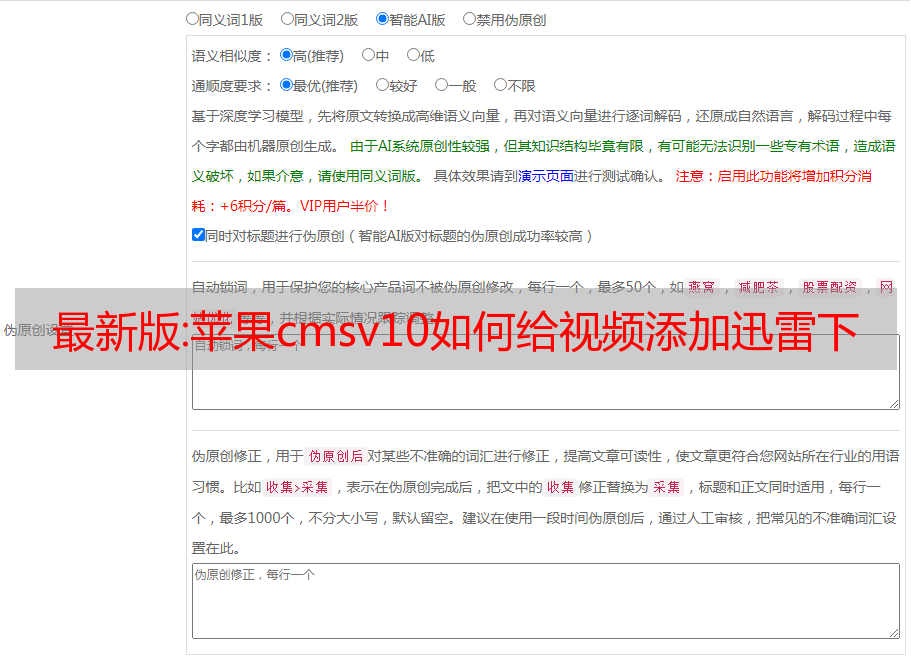
添加视频下载接口后,然后绑定分类,最后点击采集,这时网站就会有一个视频下载地址,如果你的模板不支持迅雷下载功能,就没有下载地址显示,本站最新模板均有迅雷下载功能。下面是其中一种迅雷下载样式的截图: 苹果cmsv10模板,带有迅雷下载功能。
最新版本:Web Crawler with Python - 08.模拟登录 (知乎)
(PS 你也可以在我的博客 文章 上阅读这篇文章)
在抓取数据的过程中,经常会遇到需要登录的网站,尤其是抓取社交(微博、豆瓣等)网站时,几乎无法避免模拟登录。由于我很喜欢玩知乎,而且知乎的模拟登录也不是很复杂,所以对教别人很有帮助。本博客将以模拟登录知乎为例,介绍如何使用Python代码登录网站。
和之前一样,我们打开Chrome的开发者工具,如图:
注意上图中选中的“Preserve log”选项。很多时候网站的登录操作完成后,会有一个跳转操作,比如跳转到首页(比如知乎)或者跳转到个人页面(QQ空间等) .),这会导致我们登录操作的网络请求记录被后续请求覆盖(这个描述好像不太准确,原谅我的语言水平)。当我们选择这个选项时,为了我们的方便,从现在开始的所有历史请求都将被保留。
OK,我们来填入用户名和密码,点击登录按钮,看看发生了哪些有趣的操作(虽然只是一个小数字,还是把密码隐藏起来吧):
有朋友私信问我,Network下一般有很多请求记录,怎么才能找到自己需要的请求。一般来说,对于一个登录操作,都会是一个POST请求,名字中带login或者signin的会比较可疑。另外一般可以排除js、css或者image请求,然后在剩下的请求中搜索。体验了几次,就很准了,跟那个东西一样,你懂的。
对于这个请求,我们可以通过右侧的“headers”选项卡得到如下信息:
关于什么是xsrf/csrf,这里不做过多解释,这里摘自谷歌的解释:
CSRF(Cross Site Request Forgery,跨站域请求伪造)是一种网络攻击方式,可以在受害者不知情的情况下,以受害者的名义伪造请求并发送到被攻击站点,从而使未经授权的人在其下执行操作在这种情况下保护权限是非常有害的。
这个参数体现在对应网页的源代码中,是这样的:
还有最后一个问题需要解决:验证码。这里主要是模拟登录知乎,所以不会有太多验证码相关的问题。对于这个例子,我们会手动输入验证码,但是代码的设计会考虑如何用自动识别的验证码代替。代码。我们现在要做的就是找到验证码对应的url。您可以通过点击验证码获取新的验证码图片。在这个过程中,实际上是向知乎服务器发送了一个请求。通过Chrome的开发者工具(配合知乎JS代码),可以看到验证码实际上是向“/captcha.gif”发送了一个GET请求,参数是当前的Unix时间戳。
那么,让我们从头开始,当我们使用浏览器登录知乎时,我们到底做了什么:
打开知乎登录页面(GET,)浏览器(自动)从知乎加载验证码,输入用户名、密码、验证码点击登录
因此,对于我们模拟登录的代码,我们也将还原上述步骤。
首先,我们设计了一个验证码识别的规范:通过一个函数,接收验证码图片的内容,返回验证码的文本字符串。有了这样的界面,我们就可以手动输入识别验证码,或者使用人工编码服务,或者使用OCR进行机器识别。但是不管是什么识别方式,我们都可以在不影响其他代码的情况下改变实现。如下,通过手动输入验证码识别实现:
def kill_captcha(data):
with open('captcha.png', 'wb') as fp:
fp.write(data)
return raw_input('captcha : ')
那么,我们的思路是通过一个函数模拟上面分析的步骤,登录知乎,返回登录成功的requests.Session对象。我们持有这个对象来完成登录后才能完成的事情。函数的实现如下:
import time
import requests
from xtls.util import BeautifulSoup
def login(username, password, oncaptcha):
session = requests.session()
_xsrf = BeautifulSoup(session.get('https://www.zhihu.com/#signin').content).find('input', attrs={'name': '_xsrf'})['value']
captcha_content = session.get('http://www.zhihu.com/captcha.gif?r=%d' % (time.time() * 1000)).content
data = {
'_xsrf': _xsrf,
'email': username,
<p>
'password': password,
'remember_me': 'true',
'captcha': oncaptcha(captcha_content)
}
resp = session.post('http://www.zhihu.com/login/email', data).content
assert '\u767b\u9646\u6210\u529f' in resp
return session
</p>
由于知乎在登录成功后会返回一个JSON格式的字符串,所以我们使用assert来判断返回的字符串中是否收录登录成功返回的内容。如果成功,将返回 requests.Session 对象。另外,这里的BeautifulSoup是通过xtls.util导入的,因为默认创建BeautifulSoup对象时需要指定解析器,否则会报警告。实在是懒得写了,也不想看warning,所以自己做了一些包。它会自己选择你目前拥有的最好的(在我看来)解析器。
按照我们分析的逻辑组装好相应的代码后,就可以真正测试是否可行了。测试代码非常简单:
if __name__ == '__main__':
session = login('email', 'password', kill_captcha)
print BeautifulSoup(session.get("https://www.zhihu.com").content).find('span', class_='name').getText()
在登录过程中,您将需要手动输入验证码。当然,如果通过其他方式识别验证码会更方便。如果登录成功,则此测试代码会将您的 知乎 昵称打印到终端。
概括
本博客以登录知乎为例,讲解如何模拟登录。可以用一句话来概括:分析你的浏览器是如何运行的并模拟它。看完你就会明白模拟登录原来这么简单,那就自己试试另一个网站(比如试试豆瓣),如果你觉得很简单,那就挑战一下微博的模拟登录吧。
好了,这篇博客到此结束,这几天比较忙,更新速度比较慢,见谅~~~

