解决方案:一种基于影视素材本体的关键词查询扩展方法研究
优采云 发布时间: 2022-12-05 22:15解决方案:一种基于影视素材本体的关键词查询扩展方法研究
沉毅1,赵琳2
(1.上海大学计算机中心 上海 200444;2.上海大学计算机工程与科学学院 上海 200444)
: 在语义搜索引擎系统中,为了在不限制用户输入的情况下使检索内容更贴近用户需求,提出了一种基于视频素材本体的查询扩展方法。根据本体模型对用户检索文本中的关键词进行推理,并根据相似语义进行扩展,旨在得到更符合用户检索需求的扩展关键词集,并在以此为基础来检索视频素材,从而提高搜索引擎的召回率。
:语义搜索;本体;查询扩展;视频片段
基于关键词的搜索引擎的查询扩展通常以检索文本中的关键词为中心,与这些关键词相关的语义概念很少被收录在扩展集中。在这种情况下,当用户输入的搜索内容较少时,系统根据扩展集搜索得到的结果准确率和召回率较低,不能满足用户的需求。因此,基于关键词的搜索引擎无法消除用户需求与检索结果之间的不一致。基于本体的关键词查询扩展弥补了这一不足。该技术结合了本体、搜索引擎、计算机语言学等技术,将用户输入的搜索文本中的关键词提取出来,并与这些关键词相关的词一起,形成一个新的、更长、扩展的 关键词 集,可以更准确地表达用户的搜索需求。根据这个集合,我们可以尽可能全面地了解用户的搜索意图。在[1]的基础上对信息资源进行检索,从而在一定程度上弥补了用户检索信息的不足,同时提高了搜索引擎的召回率。
1 相关研究
本体论起源于哲学,又称本体论、本体论或本体论。GRUBER TR [2] 对本体的定义“本体是共享概念模型的清晰和形式化的规范”得到了最广泛的认可。自2000年本体概念被引入人工智能领域以来,本体引起了各个学科的极大兴趣。
目前,本体描述语言有很多种。由于Web Ontology Language (OWL)格式在所有本体语言中具有最强的描述能力,能够清晰地表达词表中术语的含义和术语之间的关系,使其在Web内容的可理解性上更胜一筹到其他几种本体语言,所以本文选择OWL作为本文的本体描述语言。
1.2 本体推理
除了本体中直接定义的知识外,还有很多隐含的其他知识,需要借助推理工具进行关键词推理和查询,从而获得隐含的知识。本文选择Jena[3]作为影视领域的本体推理引擎。Jena 是惠普开发的 Java 开源工具包。其推理API以其强大的推理功能可以操作OWL描述的本体。它已广泛用于语义 Web 应用程序中。
在本文中,Jena推理需要实现以下内容: (1) 实现将本体持久化到数据库的操作;(2)推理类间关系,对视频素材本体模型进行分析,生成一组描述概念上下关系的三元组,用于后续计算本体模型中的概念相似度。
1.3 查询扩展
为了提高检索的命中率,需要利用查询扩展技术[4],在不限制检索文本内容的情况下,根据用户输入的检索信息中的关键词进行语义扩展由用户输入。基于本体的查询扩展技术的引入在信息检索过程中取得了一定的效果。该技术基于领域本体推理得到的知识,通过计算本体概念的相似度,将本体中与检索关键词相关的概念作为查询扩展的一部分。这种通过量化得到的query expansion set,不仅降低了search bias,而且限制了检索关键词扩展的范围,从而大大提高了召回率。
2 基于视频素材本体的查询扩展
2.1 视频素材本体建模
基于影视素材本体的关键词查询扩展采用语义技术对本体中的概念进行推理扩展,推理扩展基于影视素材本体模型。
本文采用Protégé,采用图解建模的方法构建影视本体模型。您可以在Protégé中点击相应的项,添加或编辑类、子类、属性、实例等。建模完成后,保存为OWL格式文件,Protégé自动将本体转换为OWL格式语言。视频素材本体建模后的部分效果如图1所示。
2.2 查询推理规则
Jena自带的通用规则[5]不会限定具体领域,主要检查本体中基于实例、公理和规则的层次关系、传递性、类间不相交性等概念和约束的可满足性,因此实现查询隐式。收录信息并扩展隐性知识。当Jena自带的规则不能满足系统的推理需求时,可以自定义规则来满足系统的个性化需求。本文借助SPARQL[6]查询语言,建立自定义查询规则,以获得更准确的查询结果。
SPARQL 由 W3C 发起。它根据定义匹配的三元组模板查询RDF,可以将RDF中满足一定条件的三元组以集合或RDF图的形式作为查询结果返回。SPARQL提供了四种不同的查询形式[7]:SELECT、ASK、CONSTRUCT、DESCRIBE,其中SELECT是最常用的查询类型,本文也采用这种查询形式。SPARQL的查询语法是四元组(GP, DS, SM, R),其中DS和R可以根据查询需要省略。查询语句的格式如表1所示。
2.3 相似度值和查询扩展阈值的确定
本文不讨论相似度和查询扩展阈值的详细计算过程,仅给出简要的处理方法。
影响概念语义相似度的因素很多,常见的有:字面相似度、语义重合度、距离相似度、层次差异和层次深度、属性匹配等,需要结合本体的结构和属性模型,将相关因素带入相似度计算方法,综合各种影响因素,得到概念相似度计算公式。
得到本体中概念的相似度后,在查询扩展的过程中,需要确定一个阈值,过滤相似度不满足阈值的概念,将满足阈值的概念加入到查询扩展集中。通常的阈值确定方式是:根据本体中小规模测试概念的相似度值和暂定阈值,人工评估相似度满足阈值的概念是否满足系统要求,通过不断实验调整阈值,最后确定阈值。
3 语义扩展
3.1关键词查询扩展过程
本节结合本体模型和推理规则,在参考文献[1]和[8]的基础上,总结了扩展视频素材检索文本中关键词的语义相似度的过程,如图2所示. 其中,sim1(A,B)和sim2(A,B)表示根据关键词是否为影视素材本体中的概念来判断不同情况下的相似度计算公式,综合影响影响概念相似度的各种因素;而a和b是用来过滤相似度概念的阈值。经过实验和不断调整参数,最终将a设为0.51,b设为0.63。
关键词语义相似度扩展过程如下:首先将检索文本预处理后得到的关键词集中的关键词添加到扩展的关键词集中,然后依次添加关键词集中的每一个关键词判断它是否是视频素材本体中的一个概念。如果当前关键词不是本体中的概念,则需要找到本体中根据公式sim1(A,B)计算的相似度大于阈值a的概念,将这些概念添加到扩展的 关键词 集;如果当前关键词是影视素材本体中的概念,则检查本体中是否存在与当前关键词等价的关键词,如果有,则添加< 中扩展名的等效词
3.2 查询扩展实现
在关键词查询扩展实现部分,本文使用MySQL数据库存储数据。以下是查询扩展实现计算中用到的数据表:
searchText:用于存储预处理后得到的检索到的关键词;
classCon:存放Jena解析本体文件后得到的概念信息,包括(节点ID,节点名称,节点层级,父节点ID);
classInOnt:存储本体中满足阈值b的节点对及其相似度信息,包括(节点AID,节点BID,相似度);
classDouble:存储预处理得到的关键词,而不是本体中的节点,以及本体中与这个关键词相似度达到阈值b的节点信息,以及两者信息的相似度. 包括(关键词, 节点ID, 节点名称, 相似度);
expandKeywords:存储展开的关键词,包括(节点ID,节点名称,相似度)。
下面给出基于视频素材本体的关键词查询扩展的实现:
(1) 获取领域本体文件;
(2)利用Jena解析本体文件,生成一组描述上下关系概念的三元组,以文件的形式存入内存;
(3) 对于步骤(2)中文件中的三元组,从根节点开始,依次遍历每个节点,将节点信息保存到表classCon中;
(4)从表classCon中读取节点并组成所有节点对,以(节点1,节点2,相似度)的形式写入到表classInOnt中,其中相似度值设置为0;
(5)将表classInOnt中未处理的记录一一取出,根据取出的记录和本体模型计算影响两个概念相似度的不同因素的值;
(6)根据公式sim2(A,B)根据步骤(5)中计算出的决定语义相似度的因子的值计算概念对的相似度,修改表classInOnt中对应的相似度值;
(7)检查表classInOnt中是否有未处理的记录,如果有,转步骤(5);否则转步骤(8);
(8)删除表classInOnt中相似度小于阈值b的节点对,完成本体中节点对相似度值的更新;
(9) 根据步骤(4)~(8),可以完成表classDouble中关键词和节点对的更新。不同的是概念相似度需要根据公式sim1(A,B)计算,保留的关键词与节点对的相似度需要满足阈值a;
(10) 从表searchText中取出一个未处理的关键词,判断是否是本体中的概念,如果是则将其相似度设为1,将关键词和相似度值相加给extension中的关键词设置expandKeywords,判断本体中是否有与当前关键词等价的概念,如果有,则在expandKeywords中加入等价词,并设置对应的相似度值与 1 等价的词,转步骤(11),否则转步骤(12);
(11) 从表classInOnt中找到与当前关键词的节点对的关键词,将这些关键词和节点对的相似度添加到expandKeywords;
(12) 从表classDouble中找到与当前关键词组成的节点对的节点,将这些节点及其相似度添加到expandKeywords;
(13)检查searchText中是否有未处理的关键词,如果有则转步骤(10),否则转步骤(14);
(14) 输出存储扩展后的关键词的表expandKeywords,算法结束。
通过上述算法得到扩展的关键词集合。
3.3 查询扩展实验
为了验证关键词相似度查询扩展算法的有效性,用视频素材本体模型对该算法进行了验证。选择搜索文本“两个孩子在路上骑自行车”。"、"Bicycle",根据3.2节的扩展实现算法查询扩展这些关键词,得到扩展后的关键词和对应的相似度,如表2所示。
从表2可以看出,对检索到的文本“两个孩子骑自行车”进行预处理和语义相似度扩展后,得到扩展的关键词集合,计算集合的相似度值从大到小排序, 如表 3 所示。
由表2和表3可知,根据本文的研究,检索关键词基于影视素材本体模型进行了扩展,扩展集中的概念能够反映用户的检索意图更完整,从而验证了本文。所提出的关键词 查询扩展方法的有效性。
4。结论
本文基于影视领域的本体模型,研究了关键词在素材检索过程中的查询扩展,提出了关键词根据相似度进行扩展的实现方案,即在搜索文本中搜索关键词,对影视素材本体模型中的概念进行推理,得到相似度满足阈值的查询扩展集。实验结果表明,扩展后的关键词集能够充分收录用户的检索需求。本文的下一步是对根据扩展关键词集关键词中的相似关系对检索结果进行排序进行深入研究。
参考
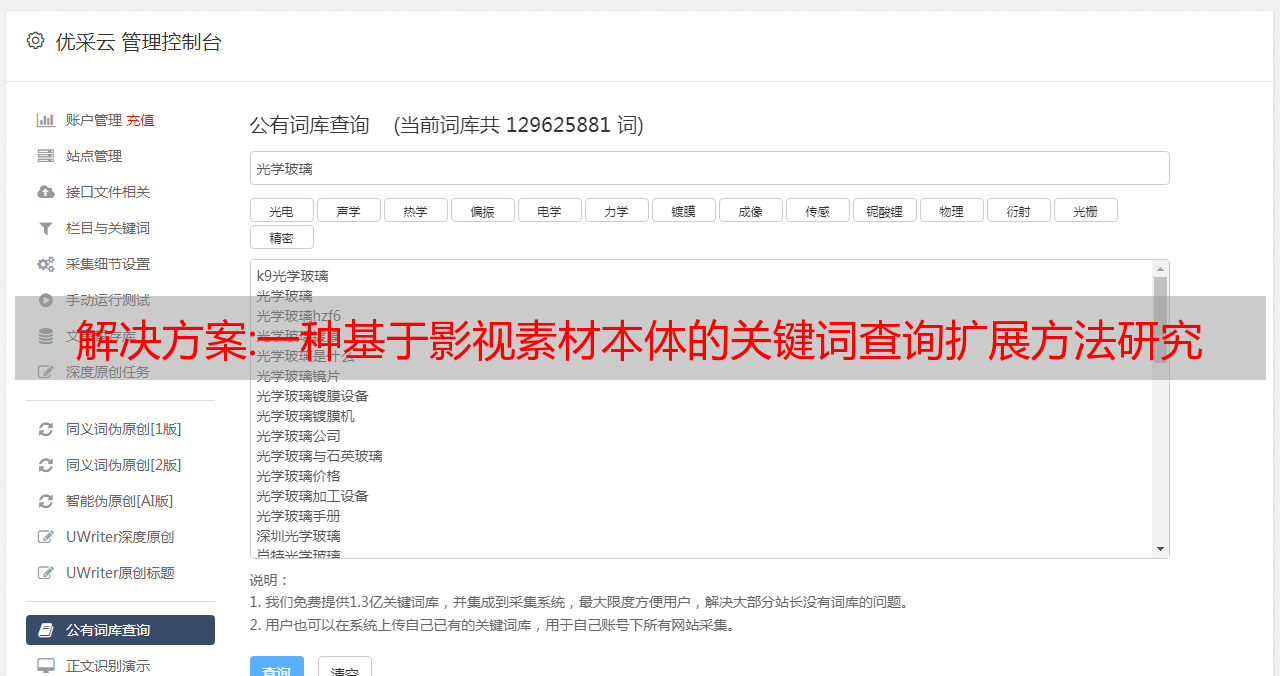
[1] 干建侯, 蒋悦.本体方法及其应用[M].北京:科学出版社,2011.
[2]GRUBER T R. 用于知识共享的本体设计原则[J].国际人机研究杂志, 1995, 43(56): 907928.
[3]Apache Jena入门[EB/OL].(2015××××)[20160130].
[4]李帅.基于语义相似度的查询扩展优化[D].杭州: 杭州电子科技大学, 2011.
[5]李冰.基于领域本体的专利语义检索研究[D].北京:北京理工大学,2015.
[6] W3C.SPARQL Query Language for RDF [EB/OL].(2013-03-21)[2016-01-20]. /TR/2013/REC-sparql11-query-20130321/.
[7]岳晓璐.语义Web中RDF数据关联规则挖掘方法研究[D].大连: 大连海事大学, 2015.
[8] 陆靖.基于语义网的语义搜索研究与应用[D].北京:北京工业大学,2013.
最新版本:dxc采集器破解版vip3.0 discuz论坛采集插件 vip商业版dz3
温馨提示:本插件所有者亲身测试后方可使用。楼主使用的程序是dz3.3,请放过小白
DXC 3.0 的主要功能包括:
1. 采集文章 各种形式的url列表,包括rss地址、列表页、多级列表等。
2.多种规则编写方式,DOM模式,字符截取,智能获取,更方便的获取想要的内容
3.规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独特的网页文本提取算法,自动学习归纳规则,平移采集更方便。
5.支持图片定位和水印
6.灵活的发布机制,可以设置发布者、发布时间点击率等。
7、强大的内容编辑后台,可以轻松编辑采集内容,发布到门户、论坛、博客
8、内容过滤功能,针对采集的内容过滤广告,剔除不必要的区域
9.批量采集,注册会员,批量采集,设置会员头像
10. 无人值守定期量化采集和发布文章
★、这个插件里面有详细的教程,仔细看就会安装
★、本插件为DXC3.0版本,
【郑重声明】:由于模板价格极低,#标签不提供技术支持#。插件安装需要一定的discuz安装使用经验,新手和不接受的请勿拍。需要帮忙安装的可以加50元,我可以帮忙安装
请看下图

