事实:优采云采集规则,优采云采集器是什么
优采云 发布时间: 2022-12-03 19:31优采云采集rules, 优采云采集器什么是admin09-12 06:56127 views文章Category[Hidden] Preface采集Content rule setting To总结一下前言,昨天的文章简单教你如何设置URL的采集规则,今天的文章教你如何设置内容的采集规则。采集内容规则设置 1.定义采集内容 首先,我们需要了解采集需要什么内容。事实上,你的采集内容最终会进入数据库。一般来说,你的一个采集标签对应一个数据库字段。让我们继续昨天的网站。我的网站是一个资源集合网站。它实际上归结为 文章 发布,以及 文章 展示的 网站。我们 文章 的内容 对应于采集网站文章的内容。一般来说,文章文章最重要的是文章标题和文章内容。如下。
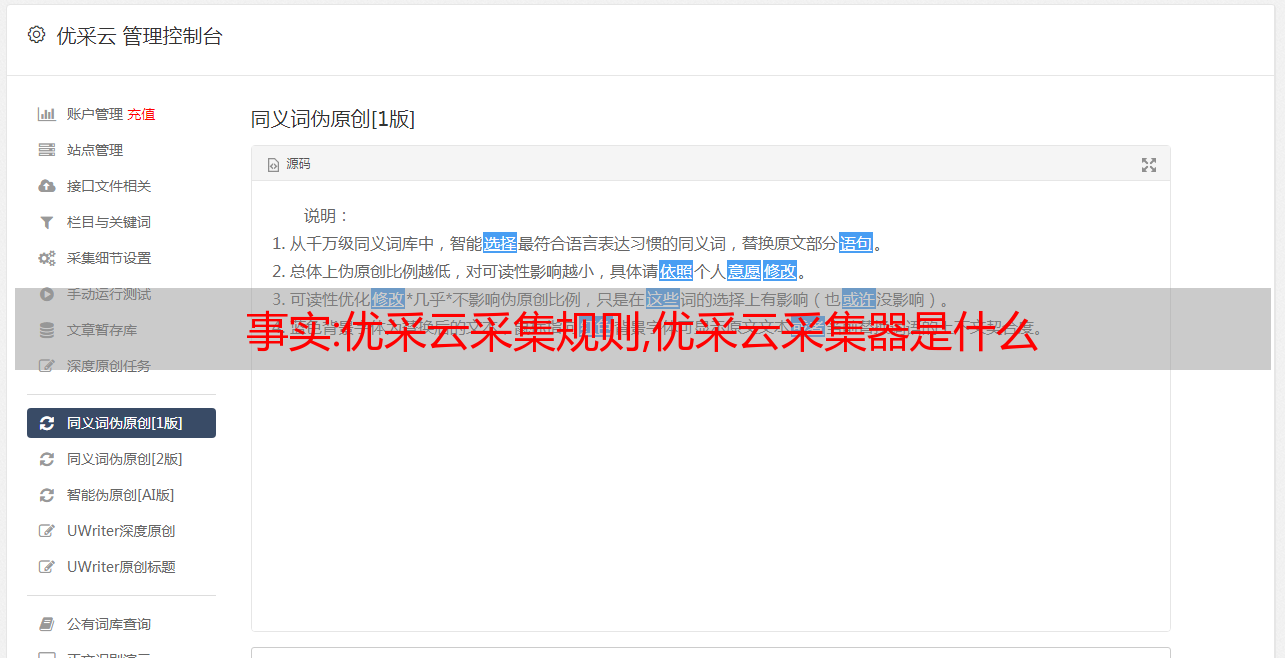
2.查看源码,分析源码
通过上图所示方法找到html代码:网上看美图源码+下载py源码。如果我们要获取里面的标题,就需要用到编写采集规则最重要的思路:拦截。我们可以在上面的标签中这样想:如果有一种前后截取的方式,从“”开始,到“”结束,那么就可以截取标题。好在优采云采集器提供了这样的操作,我们只需要进行如下设置: 3.优采云采集器获取标签内容的具体方法可以参考下图:
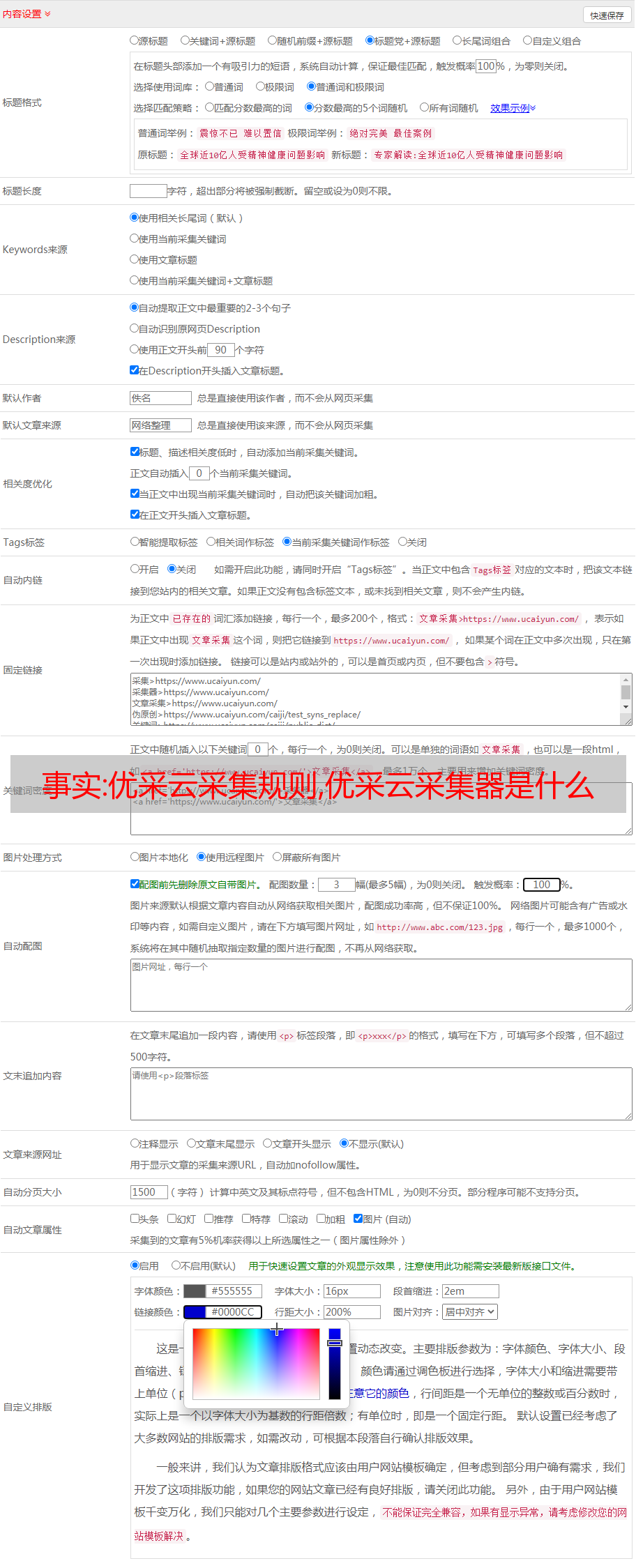
总结 1、我目前遇到的采集基本都是通过拦截html标签实现的,这种方法基本适用于80%的网站。所以不要怀疑,如果你没有得到,那一定是你的规则前后拦截有问题。2. 采集 只需要你继续测试。那些夜晚我无法得到标签。结果去百度看文章,然后测试了一下。最后因为tag中少了一些字符而被拦截。不准确。3、这个方法是自己测试可行的,采集按照这个思路应该不会错。我自己维护的一个 采集 站点:欢迎来到 采集 测试。4.如需获取教程中的网址,请关注公众号并回复:采集 网址
优采云浏览器采集教程,优采云采集器使用教程优采云采集器发布教程,优采云采集作品发布
解决方案:python自动生成采集规则_快速制作规则及获取规则提取器AP
一、简介
文章使用的前面例子中的规则都是固定的。如何自定义规则并结合提取器来提取我们想要的网页内容呢?对于程序员来说,理想的目标是掌握一个通用的爬虫框架。每次添加新目标 网站 时,都必须相应地更改代码。这显然不是一个好的工作模型。这就是本文文章的主要内容。本文通过一个案例来说明如何将新定义的采集规则集成到爬虫框架中。即利用可视化GooSeeker爬虫软件对亚马逊图书商品页面制作采集规则,结合规则提取器抓取网页内容。
2.安装Jisoke GooSeeker爬虫软件
一、前期准备
进入极速客官网产品页面,下载对应版本。我的计算机上已经安装了 Firefox 38,因此只需在此处下载爬虫即可。
2.安装爬虫
打开Firefox –> 点击菜单工具 –> 插件 –> 点击右上角插件工具 –> 选择从文件安装插件 –> 选择下载的爬虫xpi文件 –> 立即安装
下一步
下一步
3.开始制作爬虫规则
1.运行规则定义软件
点击浏览器菜单:Tools -> MS Moshutai,弹出MS Moshutai窗口。
2.制定规则
在地址栏中输入我们想要 采集 的 网站 链接,然后按回车键。页面加载完成后,在工作台页面依次操作:命名主题名称->创建规则->新建排序框->在浏览器菜单中选择需要抓取的内容,命名并保存。
4.应用规则提取API KEY
打开Gooseeeke官网,注册登录后进入会员中心->API->申请API
5.结合extractor API敲一个爬虫程序
1.引入Gooseker规则提取模块gooseker.py
(下载地址:gooseeker/core at master FullerHua/gooseeker GitHub),选择一个存放目录,这里是E:\demo\gooseeker.py
2.创建一个.py后缀的文件,与gooseker.py同级
比如这里是E:\Demo\third.py,然后用记事本打开,输入代码:
注意:代码中的31d24931e043e2d5364d03b8ff9cc77e为API KEY,请替换为您申请的;amazon_book_pc 是规则的主题名,同样替换成你的主题名
# -*- 编码:utf-8 -*-
# 使用 GsExtractor 类的示例程序
# 使用 webdriver 驱动 Firefox采集Amazon 产品列表
# xslt 保存在 xslt_bbs.xml 中
# 采集结果保存在第三个文件夹
导入操作系统
导入时间
从 lxml 导入 etree
从 selenium 导入 webdriver
从 gooseker 导入 GsExtractor
# 参考提取器
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "amazon_book_pc") # 设置xslt抓取规则
# 创建目录存放结果
当前路径 = os. getcwd()
res_path = current_path + "/third-result"
如果 os.path.exists(res_path):
经过
别的:
os.mkdir(res_path)
# 驱动 Firefox
驱动程序 = 网络驱动程序。火狐()
url = "!658391051%2Cn%3A658414051%2Cn%3A658810051&page=1&ie=UTF8&qid=6258544"
司机。得到(网址)
时间。睡觉(2)
# 获取总页数
total_page = driver.find_element_by_xpath("//*[@class='pagnDisabled']").text
总页数 = int(总页数) + 1
# 使用简单的循环加载下一页链接(您也可以找到下一页按钮并在循环中单击它)
对于范围内的页面(1,total_page):
# 获取网页内容
内容 = 驱动程序。页面源。编码('utf-8')
# 获取文件
文档 = etree。HTML(内容)
# 调用extract方法提取需要的内容
结果 = bbsExtra。摘录(文档)
# 保存结果
file_path = res_path + "/page-" + str(page) + ".xml"
打开(文件路径,“wb”)。写(结果)
print('th' + str(page) + 'page 采集 is complete, file:' + file_path)

