分享文章:帝国cms采集排除重复链接重复标题、内容为空的文章
优采云 发布时间: 2022-12-03 18:51分享文章:帝国cms采集排除重复链接重复标题、内容为空的文章
1. 背景--专栏--
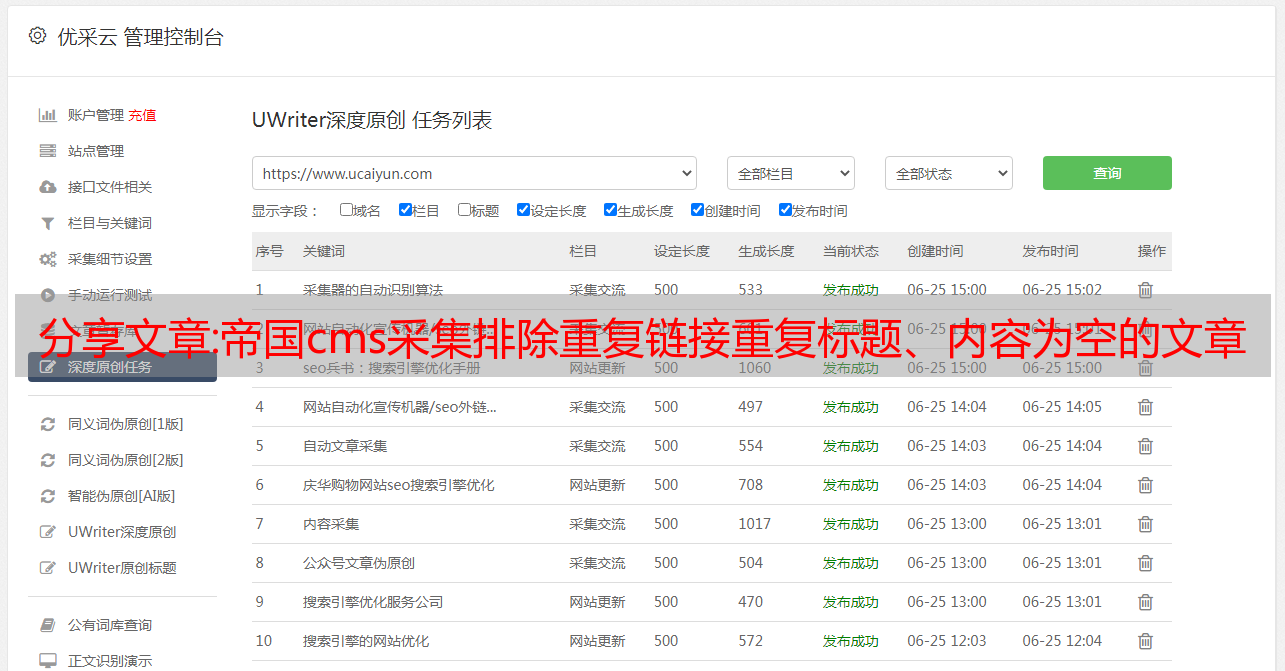
采集管理 2.添加采集节点,选择要输入的列(或管理采集节点,点击修改),进入页面——有一张一张蓝色的标题卡, 3, (1)“附加选项”有一个选项,是否重复采集同一链接: □重复采集(不要选择非重复采集) 注释:不要采集重复的链接, 单击□中的勾号 (2), “附加选项”下还有一个“过滤器选项”选项,内容为空且不采集□(新闻文本字段) 过滤器类似: 不要采集标题与()字信息相似[与入站信息比较](如不限,请填写“0”) 不要采集标题完全相同的信息(与入站信息进行比较) □注: 如果内容为空且未采集,请单击□中的勾号,不要采集 如果标题类似于大于 (),请在括号中填写数字,不要采集重复标题,单击□勾选 [Empirecms采集 以排除具有重复标题的重复链接,并且内容为空文章网站 网址:[db:源名称]
]。
分享:关于文章采集随便聊两句
除了伪原创,洪宇曾经手动做seo采集修改过几篇文章,效果还不错。
所以,永远不要采集。
像优采云这样的老采集工具八年前就听说过,今年这个软件好像已经有十年了。
这么多年了,这么有名的工具,我一直没有真正了解过。
后来有一定的开发能力,需要采集一些东西,就自己写了,没兴趣看懂。。。
今天没事,安装看了市面上几个比较知名的软件,总结了一下。
优采云,确实很强大。以前一直以为他是通过get或者post拿到源码,然后正则化的。但事实上,没有。
记得我的seo启蒙老师开发了一个简单通用的网页采集小工具。不需要正则化。当时宏宇觉得它真的很厉害,连我这种菜鸟都能用。
后来我也尝试开发一个... 才发现要把采集做好并没有那么简单。当年老师开发的那个,可没那么好用。简单意味着它不是万能的。
鸿宇写的软件一直想傻瓜式,让小白可以快速上手,但是简单了功能并不强大,所以两者之间的平衡点真的很难把握。
像优采云这样强大的工具,每个版本都会有专门的教程教你如何使用。说明软件功能强大,但使用门槛太高。
看完网页源码,过滤内容,然后采集,就是一个很简单的过程。
不过现在很多网站都是用js来加载内容的。如果你不会解析js,你将无法阅读内容的源代码。
而且每个网站的js都不一样,所以门槛高。采集软件无法解析每一个网站的js,就注定了软件的逻辑不能这么高级。
洪宇水平有限,对于js解析基本是一窍不通。但是不管js怎么工作,最后总会显示给用户看的。所以我们只需要让浏览器运行完js,然后采集就可以了。
这导致很多效率低下。我们需要一个浏览器来帮助我们浏览,而我们采集浏览网页。
面对今日头条这种js展示的网页,洪宇只能采用这种傻瓜式开发。它是否有效并不重要,只要它能 采集 得到它。
今天看了看市面上的采集软件,惊奇的发现在采集中也用到了我的逻辑。
通过浏览器打开页面,在采集链接之前等待页面完全加载,然后打开链接,然后是采集内容。
软件的高级之处在于它会自动分析帧,你不需要对内容进行正则化,你可以通过点击鼠标选择你想要的部分采集,然后他就会采集 这适用于每个 文章 部分。
说实话,洪宇有些失望,觉得这些收费这么高的商业软件是有什么本事的,但又没有。
当然,量产采集就相当于攻击这个网站。所以很多 网站 都会受到限制。
道高一尺,魔高一丈。采集工具加换ip,加清cook,加换浏览器,基本配置。其实大部分软件并没有真正改变浏览器,只是改变了ua。
在这个前提下,要想提高效率,就只能靠多线程了。
有很多缺点。如果你的电脑配置不好,长时间运行多个浏览器,你可能会受不了,而且关于换ip,大部分软件都自带代理ip功能,需要另外花钱这个代理ip。
因此,要想真正做到傻瓜式采集,还是需要有一定的开发能力,为某个网站开发一个独立的采集工具。
这样只需要填一个关键词,然后点击采集就可以自动导出了。
对于SEO,采集一直是一个需求,因为大多数人的原创能力都是有限的。即使你有能力,你的效率和数量也是有限的。
关于采集,鸿宇打算...

