织梦采集规则
优采云 发布时间: 2020-08-07 11:32
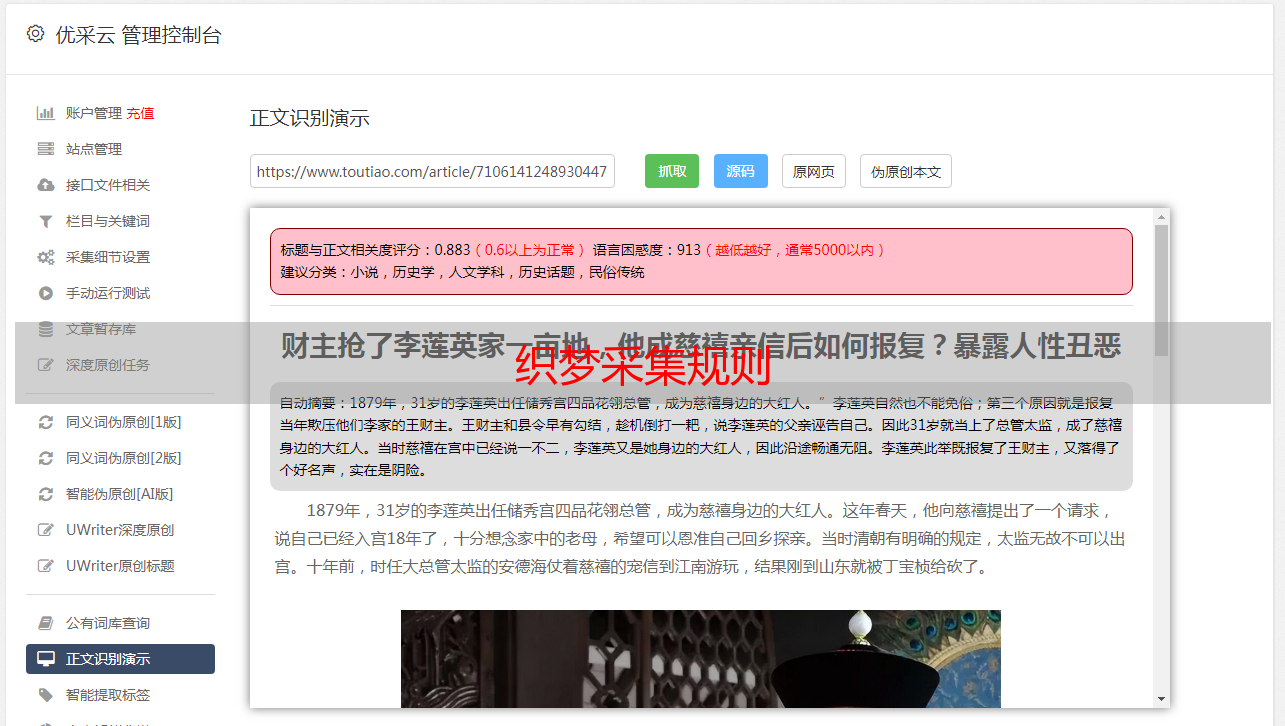
编织梦的采集规则一个拥有N个频道和N个网站数据的大型信息网站,对于网站管理员来说,不可能一次一个地发送每条数据!这时,为了节省人力和物力,采集器诞生了(对于优化的朋友,我不建议您使用它)!接下来,我将使用织梦管理系统附带的采集器从网站采集数据,向您展示如何编写采集规则!步骤1: 创建新的文章采集节点1.登录到后台的Dream Weaving管理,然后单击2,“采集” >>“采集节点管理” >>“添加新节点” >>“选择常见文章” >>“确认”步骤2: 填写采集列出规则1.节点名称: 任何名称(请注意,您必须能够区分它,因为如果节点太多,则有可能
我会搞砸的. ” 2.目标页面编码: 查看目标页面的编码(例如,我采集的网站的编码为GB2312)3.匹配的URL: 转到采集目标列表页面,然后检查其列表规则!例如,许多网站列表的首页与其他内部页面有很大不同,因此我通常不采集目标列表的首页!例如,我演示的网站的列表规则是,第一页设置了默认首页,而后面的实际路径却无法看到,如图所示: 因此,我们只能从第二页开始(尽管第一页可以找到第一页,但是许多网站根本没有第一页,因此在这里我不会谈论如何找到第一页)!让我们比较一下采集目标页面的第二页和第三页!如图: 是
看,这两个页面有规律地增加,第二个页面是list_2!第三页是list_3!因此,我们上面写的匹配URL(*)代表列表页面的2或3或4或更多!在第三个交叉开关上,我写了一个从2到5的(*),这意味着从2到5的+1增量与(*)而不是(*)匹配! 4.该区域开头的HTML: 在采集目标列表页面上打开源代码!在要采集的文章标题的前面附近找到一个部分,这是此页面上唯一的html标签,而要采集的其他页面也是唯一的html标签! 5.该区域末尾的HTML: 在采集目标列表页面上打开源代码!在要采集的文字中
在章节标题后面寻找一个章节. 此页面是唯一的页面,要采集的其他页面也是唯一的html标签!我们还没有使用过其他地方,所以我们可以忽略它!这样,就可以编写列表页面的规则!下图是我编写的列表规则的屏幕截图!写完后,单击“保存信息”,然后继续下一步!如果规则编写正确,则将测试URL捕获规则的内容: 如下图所示. 步骤3: 填写采集内容的规则1.文章标题: 在文章标题前后找到两个标签以识别标题!我在网站上采集的文章标题前后的唯一标签是...,写为[Content]. 2.文章内容: 在文章内容前后分别找到两个标签
签名,您可以识别内容!我采集的网站文章内容前后的唯一标签是
...

